本記事について
本記事は「Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization (Huang+, ICCV 2017) 」について紹介するものです。大学の講義で論文実装の課題があったため、「AdaINってなんかよく聞くしめちゃすごいらしいけどあんまよく知らんからこの機会に勉強してみるか」と思って選んでみました。
元論文はこちら、今回作成した再現実装はこちらになります。
概要
どんな研究?

Style Transferは上の画像のように、content画像の構造を持ちながら、style画像のテクスチャを持つような画像を生成するタスクです。画像は元論文のものを用いています。
AdaINはStyle Transferのタスクにおいて、以下の二点を達成しました
- リアルタイムな任意のstyleへのStyle Transferが可能に
- ユーザによるstyleに関する様々なコントロールが可能に
そのために提案された手法が、**Adaptive Instance Normalization (AdaIN)**です。
以上がこの研究のざっくりとした概要です。めちゃくちゃシンプルな手法でインパクトのある生成結果を得られたのがやはりすごいですね。
AdaINってどんなもの?
AdaINはnormalizationの一種です。Style Transferのタスクでは、content画像の構造を残しながらstyle画像っぽいテクスチャの画像を生成するわけですが、AdaINはcontent画像の平均と標準偏差をstyle画像のものに置き換えるように正規化することでこれを実現しました。
これによって任意のstyleについて一枚のリファレンスだけで適応することができるようになりました。さらに、styleの混ぜ合わせ具合やcontentとstyleの比率などをテスト時にコントロールできるなど、大変応用性の高い手法となっています。
背景(これまでのNormalization)
Batch Normalization (BN)
BNは、入力の各チャネルについてバッチごとに平均と標準偏差を正規化するという機構です。BNを用いることにより、ネットワークの収束が速くなることが知られています。
BNは以下の式で表すことができます。
{\rm BN}(x) = \gamma\Bigl(\frac{x-\mu(x)}{\sigma(x)}\Bigr)+\beta
ここで$\mu(x)$および$\sigma(x)$はそれぞれ平均と標準偏差、$\gamma$と$\beta$はデータから学習されるaffineパラメータです。
本来はネットワークの収束を速くするために加えられた機構ですが、画像生成モデルでも効果を発揮することがわかっています。さらに面白いことに、ターゲットドメインで学習したパラメータを用いて正規化をすることにより、Style Transferへも応用できることがわかりました。AdaINはこの考え方が起源と言えるでしょう。
Instance Normalization (IN)
BNはバッチごとにまとめてに正規化をしていたのに対して、INは各画像について個別に正規化を行う機構です。少しの変更のようにも思えますが、これだけで大幅な改善があることがわかりました。
INは以下の式で表すことができます。
{\rm IN}(x) = \gamma\Bigl(\frac{x-\mu(x)}{\sigma(x)}\Bigr)+\beta
Conditional Instance Normalization (CIN)
INを拡張し、異なるstyle $s$それぞれについて$\gamma$と$\beta$を学習するように変更したのがCINです。
CINは以下の式で表すことができます。
{\rm CIN}(x; s) = \gamma^s\Bigl(\frac{x-\mu(x)}{\sigma(x)}\Bigr)+\beta^s
INをよりStyle Transferに特化した形に拡張した手法と言えますが、学習時に見たstyleでないと適応することができないという点が課題でした。
AdaIN (Adaptive Instance Normalization)
この論文の提案手法であるAdaINについて書いていきたいと思います。
AdaINには、BNやINのように学習によって求めるパラメータ$\gamma$と$\beta$はありません。その代わりとして、style画像$y$の平均と標準偏差を用いて正規化をします。content画像$x$を、平均と標準偏差がstyle画像のそれと一致するように正規化するという感じです。
AdaINは以下の式で表すことができます。
{\rm AdaIN}(x, y) = \sigma(y)\Bigl(\frac{x-\mu(x)}{\sigma(x)}\Bigr)+\mu(y)
AdaINはINのとてもシンプルな拡張でありながら、任意のスタイルへの適応を非常に低コストで行うことができるという点でとても優れています。学習時に見たことのないstyleであっても、style画像の平均と標準偏差さえ求めてしまえばStyle Transferは可能だからです。
さらに、複数のstyle画像を重み付けして用いたり、content画像とstyle画像の重みを変えたりできるなど、ユーザのコントロール性が高いのも大きな特徴といえます。
実装したモデル
今回は元論文のモデルをできる限り忠実に再現することを目指しました。モデル構造は以下の図のようになっています。
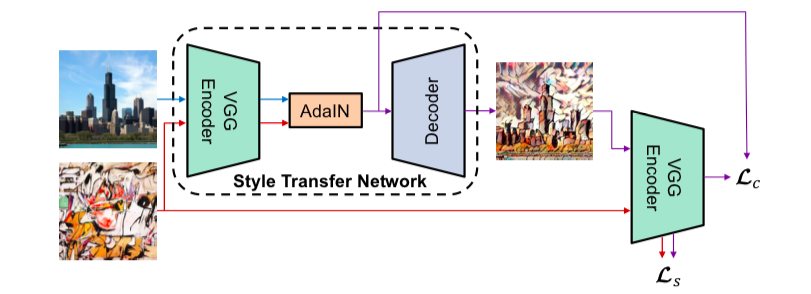
content画像とstyle画像それぞれから同じencoderを用いて中間特徴を抽出し、それらをAdaINに通して得られた特徴をdecoderに通して出力を得ます。ここでencoderは事前学習済みのVGG19の途中の層までを用いており、学習対象ではありません。注意点としては、paddingがreflection paddingに変更されています(地味にここの実装でかなり苦労しました……)。
lossに関しては、content画像と出力画像の中間特徴を比較するcontent lossと、style画像と出力がお像の中間特徴の平均と標準偏差を比較するstyle lossの二種類です。2つのlossの重みを調整することで、content寄りかstyle寄りかを調整することができます。
実装に関してはこちらを参照してください。
実験と結果
元論文と同じく、contentデータセットとしてMS-COCO、styleデータセットとしてPainter by Numbersを用いて実験を行いました。
実験結果は以下のようになりました。

概ねうまくStyle Transferができているのではないかなと思います。今回はcontent lossの重みとstyle lossの重みはそれぞれ1.0,10.0としましたが、styleの性質が強く出た生成結果になったかと思います。
ちょっとアーティファクトっぽいものが乗った感がありますが、原因はわかりません……。
おわりに
今回はAdaINの簡単な説明と実装を行いました。いままでDeepを扱う研究を行ってきたものの、実は自分でネットワークを実装するのは初めてだったので、とても良い勉強になったと思っています。思いがけないところで苦労したりするものですね……(VGG通す前の正規化忘れて三日間止まったりしてました)。
AdaIN、実装はシンプルなのに色々すごいことできるの、インパクトのある研究だなと思いました。インパクトのある研究したいですね……。
地味に初投稿なので拙い部分もあったかと思いますが、ここまでお読みくださってありがとうございました。