TL; DR
- Data Augmentation色々試した
- 精度がどう変わるか比較してみた
- 結局RandomErasingが良いのかな?
- 学習データに合ったAugmentationを選ぼう
Data Augmentationとは
データを水増しする方法です。
画像で言うと、1枚の画像を反転させたり回転させたりグレースケールにしたりして水増しします。
元の画像・反転させた画像・回転させた画像の3枚があれば、元のデータを3倍にできるってことですね。
なぜData Augmentationをするのか
そんなことしてどうなるの?って話なのですが、Data Augmentationをすると過学習を防ぐことができるというメリットがあります。
過学習とは、訓練データに対して学習しすぎて、未知のデータに対して適応できなくなってしまう現象のことを言います。
データ数を増やすことでこの過学習を防止することができるのです!これを正則化って言います。
今回試してみたData Augmentation
今回使った手法は以下の通りです。
- RandomHorizontalFlip : 画像を確率pで左右反転する
- RandomAffine : 画像をランダムに回転/拡大縮小する
- RandomErasing : 画像をランダムな一部分にノイズを付加する
- RandomPerspective : 画像を確率pでランダムに透視変換する(歪ませる?)
では1つずつ確認していきましょう。
ちなみに、加工する前の画像はこちらです。

RandomHorizontalFlip
画像を確率pで左右反転するというものです。
pはデフォルトだと0.5なので、1/2の確率で画像が左右反転します。
train_data = dsets.CIFAR10(root='./tmp/cifar-10', train=True, download=False, transform=transforms.Compose([transforms.RandomHorizontalFlip(p=0.5), transforms.ToTensor()]))
train_loader = DataLoader(train_data,batch_size=batch_size,shuffle=False)
このような結果になりました。

元の画像が左右反転されてますね。
RandomAffine
画像を指定した範囲内でランダムに回転および拡大/縮小します。
train_data = dsets.CIFAR10(root='./tmp/cifar-10', train=True, download=False, transform=transforms.Compose([transforms.RandomAffine([-30,30], scale=(0.8,1.2), shear=10), transforms.ToTensor()]))
train_loader = DataLoader(train_data,batch_size=batch_size,shuffle=False)
[-30,30]は、画像を-30度~30度の間で回転させるというものです。
scale=(0.8,1.2)は、画像を0.8倍~1.2倍するというものです。
このような結果になりました。

RandomErasing
画像のランダムな範囲を真っ黒に塗りつぶしちゃおうというもの。
個人的にかなり推しています。
train_data = dsets.CIFAR10(root='./tmp/cifar-10', train=True, download=False, transform=transforms.Compose([ transforms.ToTensor(),transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3))]))
train_loader = DataLoader(train_data,batch_size=batch_size,shuffle=False)
上記では、p=0.5より、1/2の確率でノイズを付加させるということになります。
scale=(0.02,0.33)は、画像の2%~33%までが黒くなるということです。この範囲もランダムに選択されます。
ratioは消去領域のアスペクト比の範囲が設定されています。
出力された画像の一例が次の通りです。
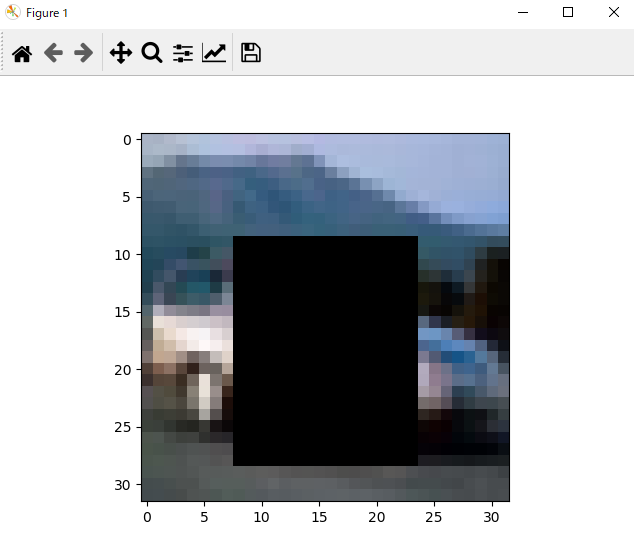
車と言われれば車だなあって思えますが、一見何かわからないですね。
RandomPerspective
ランダムに透視変換(?)をするものらしいです。
train_data = dsets.CIFAR10(root='./tmp/cifar-10', train=True, download=False, transform=transforms.Compose([transforms.RandomPerspective(distortion_scale=0.5, p=0.5, interpolation=3), transforms.ToTensor()]))
train_loader = DataLoader(train_data,batch_size=batch_size,shuffle=False)
pはRandomPerspectiveを実行する確率ですね。他と同様デフォルトでは0.5です。
distortion_scaleは歪みの程度を指定するみたいです。まあデフォルトのままで良いでしょう。
interpolation=3は、BICUBICというフィルタを用いるということだそうです。
まあ僕には総じて良くわからいので実行結果を見てみましょう。

たしかに歪んでますね。
比較してみた
比較内容は以下の通りです。
- 1epochごとに訓練誤差の平均を算出し、それが0.05未満になったら終了
- 0.05未満になるまで何エポックかかったか比較
- 精度がいくらになったかも比較
しっかりとdata augmentationが効いていれば、訓練誤差が0.05未満になるまでに時間がかかるはずです。
続いて、実験条件は以下の通りです。
- モデルは訓練済みのResNet50を使用
- 誤差関数はCrossEntropyLoss
- Weight Decayなどの、他の正則化手法は適用しない
- optimizerには学習率0.01,momentum=0.9のSGDを使用
結果は以下の通りになりました。
| 手法 | 学習が完了するまでのepoch数 | 精度(%) |
|---|---|---|
| augmentationなし | 7epoch | 81.53 |
| RandomHorizontalFlip | 14epoch | 84.71 |
| RandomAffine | 45epoch | 83.88 |
| RandomErasing | 43epoch | 85.38 |
| RandomPerspective | 68epoch | 85.55 |
「学習が完了する」というのは、「1エポックごとのCrossEntropyLoss()の平均が0.05未満になった時点」と定義させていただきました。
augmentationなしの場合は7epochで学習完了になってしまっていますが、RandomPerspectiveだと68epochもかかっていますね。すべての手法においてきちんと正則化できていることがわかります。
さらに、精度も3~4%程改善しています!
一番精度が良いのはRandomPerspectiveという結果になりましたが、RandomErasingの方が25epoch少なくてほぼ同程度の精度を出しているので、学習時間と精度を考えるとRandomErasingが1番良さそう。
すべての手法を一緒に使ってみる
「全部の手法を一気に使えば最強じゃん!」という発想のもと、実験してみました。
200epoch学習させた結果が以下の通りです。
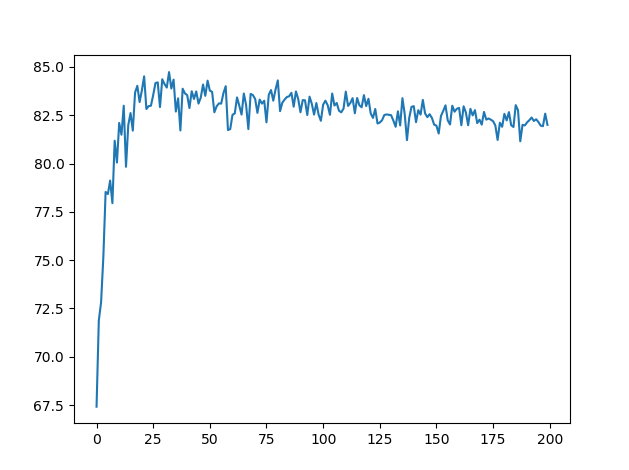
正答率85%以上の精度は見込めなさそうです。やりすぎは良くないですね。
結論
今回はRandomErasingが良さそうという結果にしましたが、これはCIFAR-10でのみの結果であるかもしれません。
学習データに合ったData Augmentationを使うということが大事そうですね。
僕はとりあえずRandomErasingを使ってみて精度が低かったら別の手法を試してみる、というようにしていこうと思います。