はじめに
自然言語処理の勉強も始めました。すぐに忘れてしまうのでアウトプットを兼ねてBERTの改良モデルである「Sentence BERT」についてまとめました。
対象読者
- 自然言語処理初心者
Sentence BERTとは?
自然言語処理モデルであるBERTの一種です。
事前学習されたBERTモデルに加えて、「Siamese Network」という手法を使い、BERTよりも精度の高い文章ベクトルの生成ができます。
BERTを改良したモデルとして2019年に発表されました。
Sentence BERTの何がすごいの? BERTと何が違うの?
BERTと違って、複数の文章のクラスタリングに有効です。
BERTでも、ラベル付きデータを用意してファインチューニングを行い、2つの文章を高精度で比較することは可能です。ただ、複数の文章をクラスタリングするには精度が悪かったり精度がいまいちだったり課題がありました。BERTで複数の文章をインプットとして推論するように実装するのはおすすめできません。複数文章をインプットとしてクラスタリングする場合にSentence BERTが役に立ちます。
この課題がSentence BERTでは「Siamese Network」という手法を使うことにより改善されています。
実際、文章の類似度を見てみても、精度が高い結果が得られました。BERTだと65時間かかるものが、なんと5秒に短縮されています。これは少し極端な例だと思いますが、Sentence BERTの効率性の良さが読み取れると思います。あと、「BERTの精度を維持した状態」というのがポイントです。
論文を引用すると以下のとおりです。
BERT(Devlin et al。、2018)とRoBERTa(Liu et al。、2019)は、セマンティックテキスト類似性(STS)のような文ペア回帰タスクに新しい最先端のパフォーマンスを設定しました。ただし、両方のセンテンスをネットワークにフィードする必要があるため、計算のオーバーヘッドが大きくなります。10,000のセンテンスのコレクションから最も類似したペアを見つけるには、BERTを使用した約5,000万の推論計算(約65時間)が必要です。BERTの構造により、意味的類似性検索や、クラスタリングなどの教師なしタスクには適していません。
この出版物では、Sentence-BERT(SBERT)を紹介します。これは、シャムおよびトリプレットネットワーク構造を使用して、コサイン類似性を使用して比較できる意味的に意味のある文の埋め込みを導出する、事前トレーニング済みのBERTネットワークの変更です。これにより、BERTの精度を維持しながら、最も類似したペアを見つけるための労力が、BERT / RoBERTaの65時間からSBERTの約5秒に短縮されます。
SBERTとSRoBERTaは、一般的なSTSタスクと転送学習タスクで評価され、他の最先端の文埋め込み方法よりも優れています。
また、BERTはトークンごとのベクトル化するのに対して、Sentence BERTは文章単位でベクトル化します。ここが、文章同士の類似度で精度の高い結果が得られる理由でもあります。
Sentence BERTの仕組み
Pooling層を追加しているのが特徴です。

Sentence BERTで何ができるの?
Sentence BERTでは以下のことができるようになります。
- 文章分類
- チャットボット、FAQ自動生成
- 感情分析
- など
これだと、BERTとあまり変わらないですね。Sentence BERTの何がいいのでしょうか? それはBERTと比較して精度が大幅に向上しています。BERTでもファインチューニング次第で精度を高くすることが可能ですが、かなり限定的であることがBERTの課題です。それがSentence BERTによって、BERTよりも広範囲に高い精度が得られるようになりました。
また、BERTと比較して効率がよいのも特徴です。実際推論に要する時間も短くなっています。
Sentence BERTの利用方法
Sentence BERTの論文の実装としては、「Sentence Transformers」があります。このフレームワークを利用して手軽に始めることが可能です。
事前学習モデル
b-xlm-r-multilingual
これはsentence transformersモデルです。センテンスと段落を768次元のベクトル空間にマッピングし、クラスタリングやセマンティック検索などのタスクに使用できます。
bert-base-nli-mean-tokens
sentence transformersの学習方法に記載されているモデルですが、品質が悪く現在は非推奨となっていました。
事前学習モデルのリストは以下にあります。
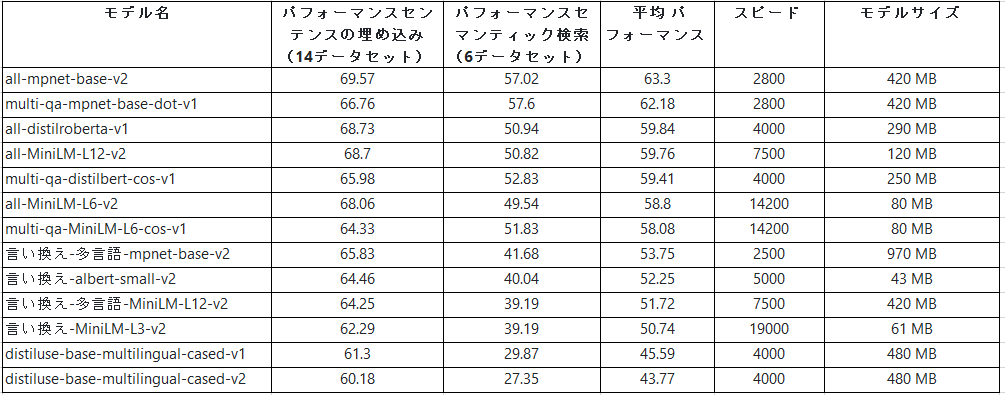
事前学習モデル一覧
使用方法
- Sentence Embeddingsの計算
- Semanticテキスト類似度
- Semantic検索
- リトリーブ&リランク
Triplet Loss
よく「Triplet」というワードが登場しますが、トリプルの類似語で「3つの組」という意味があります。これは特徴量を「positive」、「negative」、「anchor」の3つに分類していることから「Triplet」と呼ばれています。
Sentence Transformers実践
インストール方法
インストールは簡単です。すぐに利用できます。
!pip install sentence-transformers
その他、詳細は以下へ。