Outline

「テスト自動化その前に ~テスト自動化アンチパターン~」というテーマのもと、JaSST Tohokuが開催されました。
今回、発表する機会をいただき、ここで発表した内容をつづりました。
尚、当日はオンライン参加になりました。
本当は岩手の現場に行きたかったのですが、このような世の中・事情もありましてリモートより参加しました。
phase-1 process issue & solution
QAを立ち上げた当初のチーム構成は小さかった。
そのため、以下のようにテスト自動化は順風満帆でした。
・マニュアル、自動化双方密にコミュニケーション
・自分ひとりで1つのサービスに集中して実装
・テスト自動化の対象は、ゴルフの予約といった超重要な機能に絞ってカバーしていた
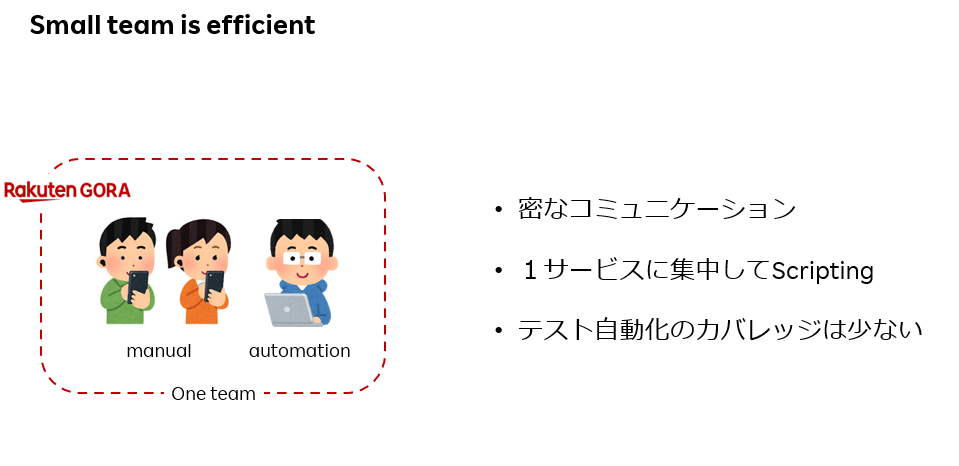
だが、時がたつにつれ組織は大きくなる。
・組織が徐々におおきくなる → 人が増え、対象サービスが増え、マニュアル・自動化のチームが分離
・サービスがふえる → 自動化も各サービスに追従する
・自動化エンジニアが増える → 自動化でのカバレッジが大きくなる
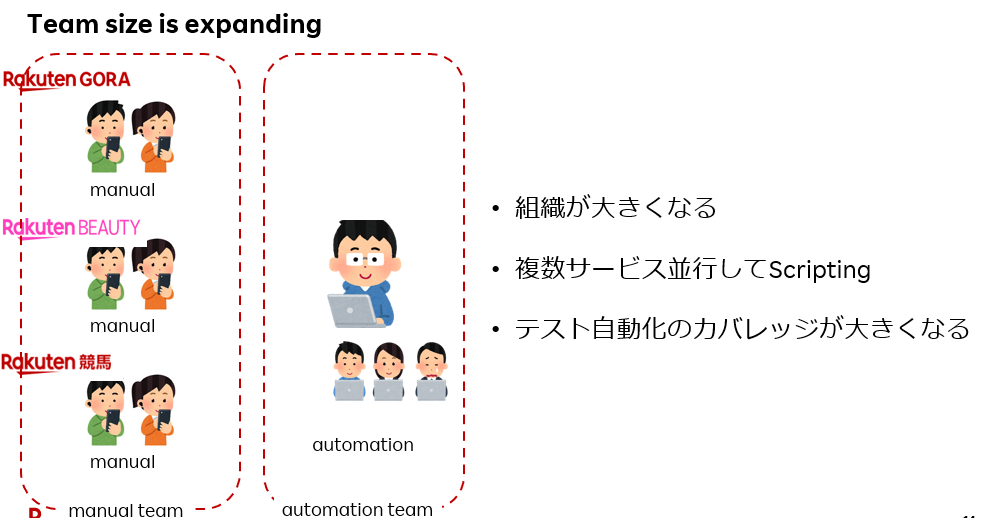
上記のように、組織が拡大していくと何が起きるか?
・人が多くなり、チーム分離することでマニュアル、自動化で連携が薄れてくる → お互いにテストが不明確になってきます。 マニュアルからすると「自動化なにやってんだ」と言われる (ノ_・、)シクシク
・自動化のカバレッジが広くなるということは、サービスのリリースに伴う仕様変更が影響しやすくなる → 失敗が増えてくる
このように、組織が大きくなると、テスト自動化の役割がさまよってしまう。
これを解決するために大きく二つのことをしました
・テストの責任範囲・役割を明確にする
・新規機能、既存機能の仕様変更の明確化と、自動化の優先順位
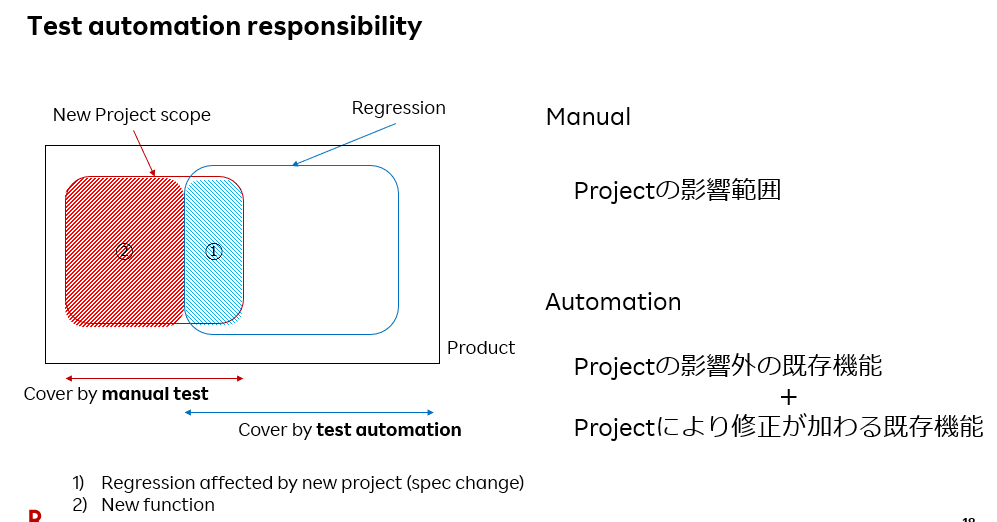
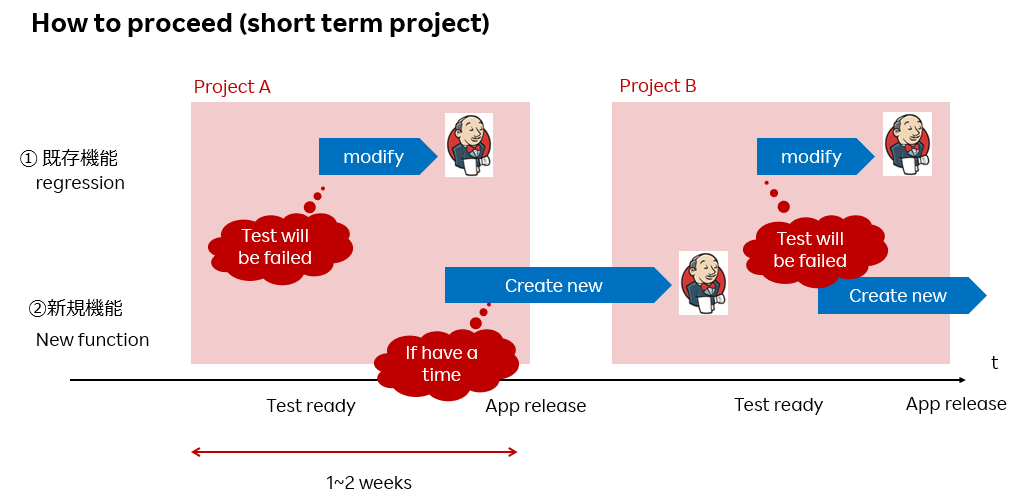
マニュアルとテスト自動化の責任範囲を示したのが下図になります。
・青い枠=既存機能、regression → テスト自動化は常時チェックする範囲
・赤い枠=新しいプロジェクトが始まったときにできるプロダクトスコープ。①既存機能で仕様変更発生する部分+②新規機能で構成
プロジェクトの間、マニュアルチームは赤い枠、プロジェクトスコープに責任を持つ。テスト自動化は青い枠、regression(①を含む)に責任を持つ。
当然、プロジェクトにより、①のregressionのテスト自動化は失敗するようになります。それをどのようにして修正するかが次のスライドです
既存機能で修正発生する①に関しては、そのプロジェクト内でscriptを修正し、テストが動くようにします。
他方、新規機能②に関しては、そのプロジェクト内ではMUSTではない。余力があれば着手し、次のプロジェクトに間に合えばよい感じで作成する。
このようなプロセスの見直しにより、以下のような効果が得られた。
・マニュアルチームからの信頼、効率的な品質保証
・少人数のテスト自動化エンジニアでテスト自動化の責務を果たす
phase-2 script issue & solution
phase-1で示した通り、新しいプロジェクトが発生しても仕様変更にテスト自動化が追従するようになった。
テストが毎日成功を継続するようになり、テスト失敗するまで見守るようになった。
ところが、テストがどんどん実行待ちになり、時間がかかるようになった。
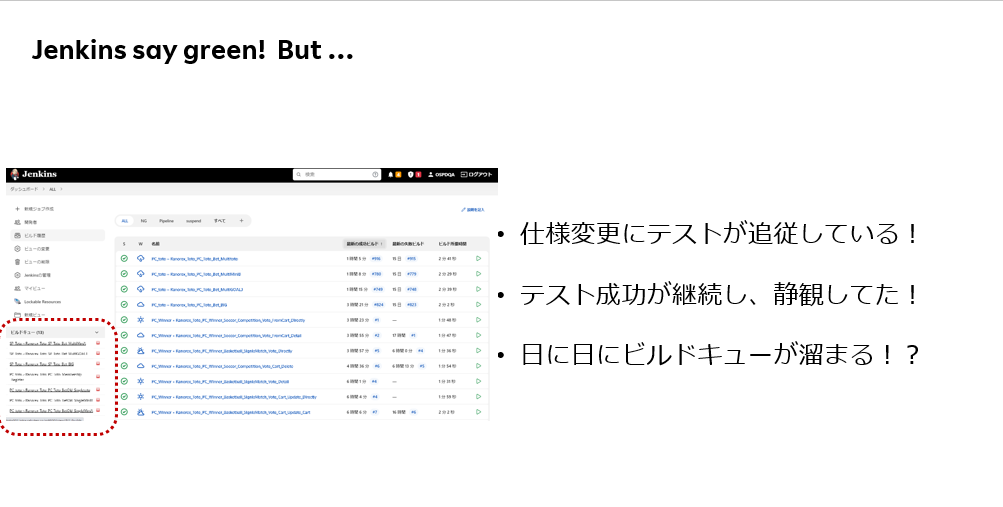
下図の左は一つのテストの実行回数と実行時間を表したグラフです。
テストはずっと成功していますが、実行を重ねていくと突然実行時間がかかるようになった。
テスト成功中は気にしてなかったので、それが積み重なりいつの間にか全般的にテストが終わらないという問題が起きた。
このテストが遅くなる原因として、いろいろ考えられます
・テストデータ肥大化
・Pipelineが肥大化、テストの高依存化
・いけてないテスト自動化の実装
ただ、そもそも「遅くなっているという問題に気付いていないことが、問題である」と。
つまり、テスト自動化が成功し続けても、自動化の内部品質に課題あった。
上記問題の対策として、「テスト実行結果の可視化と、問題可能性の早期検出の仕組化」を行った。
以降、具体的に説明します。
まず、前提としてすべてのテスト実行情報をDBに蓄積します。
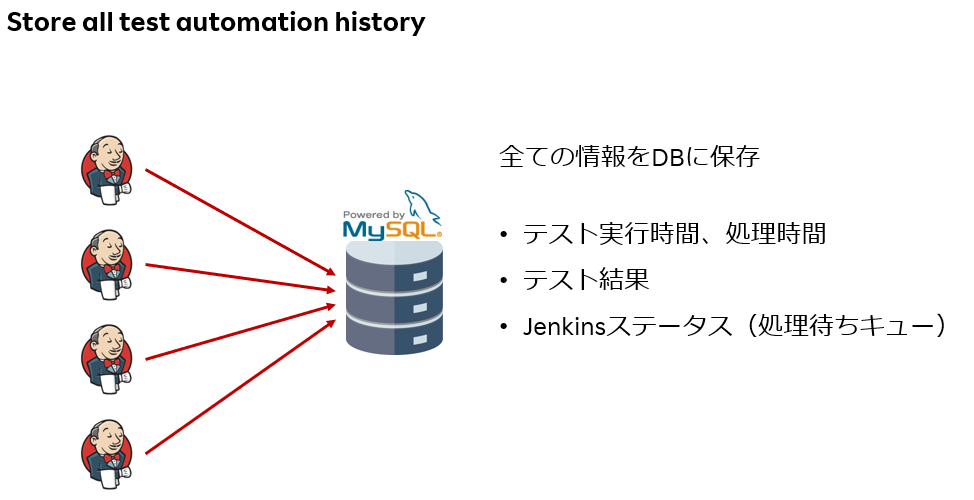
そのDBをもとに、スクリプト単位のパフォーマンスを可視化する。
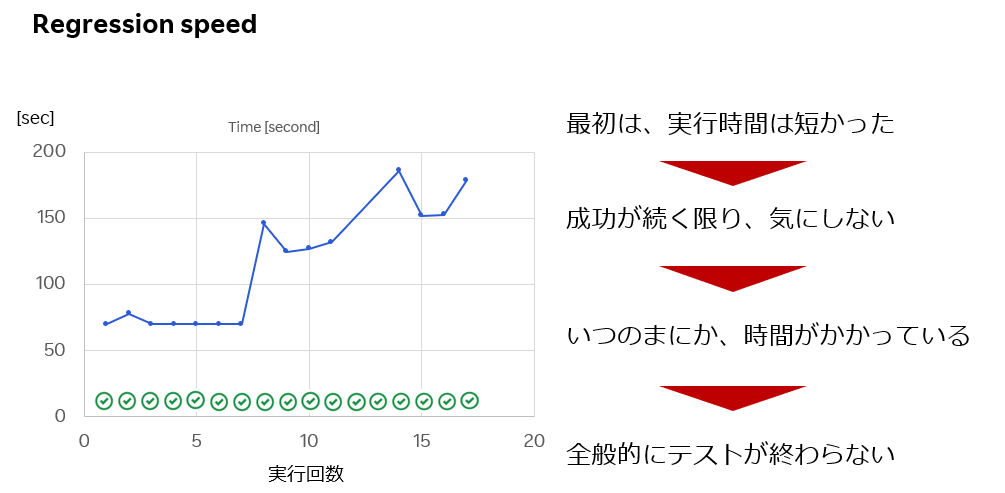
下図の1行が1つのテストスクリプトの実行結果の履歴、平均実行時間、時間推移が確認できる。
また、フィルター機能により、パフォーマンスの悪そうなオプションで絞り込みを行い、問題のスクリプトを絞り込むことができる。

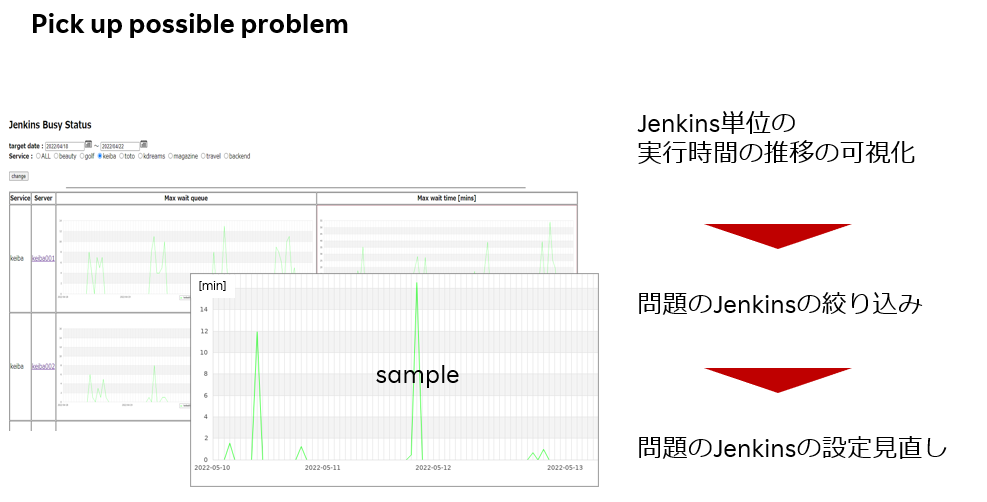
また、下図はjenkins単位のパフォーマンスを可視化する。
sampleのグラフは、時間軸に対してテストの待ち時間の最大時間を現したもので、jenkinsで問題のあるものを可視化することで、早期にjenkinsの見直しをすることができる。
このような仕組化により、以下のような効果が得られた。
・テスト自動化パフォーマンス問題の早期発見
・安定したテスト自動化の結果提供
Phase-3. Operation issue & solution
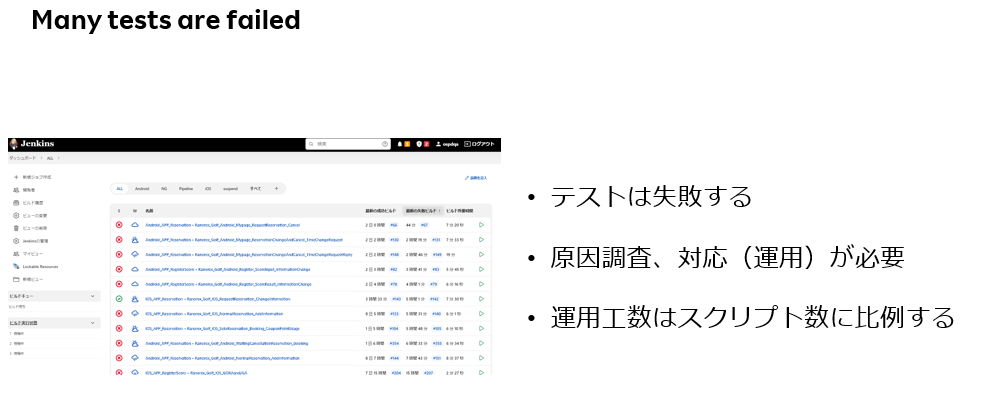
テスト自動化の運用フェーズが進むにつれて、テスト失敗が徐々に出てくる。
失敗したとき、その失敗原因の調査・対応(運用)が発生する。
マニュアルとテスト自動化のエラー発生時の対応は下図の通りです。
マニュアルテストの場合、テストの過程で問題がわかり、即バグチケットを上げる。
一方、テスト自動化の場合、テスト失敗のレポートがトリガになります。
そのトリガをうけて、まずレポートをかき集めて、失敗原因の分析を行う。
そして、再現性を確認するため自分のローカル環境で試してみたりして、原因を分析する。
その後、バグだとわかればバグチケットを上げます。
このように、テスト自動化は失敗したときの作業はマニュアル以上に大変になるときがあります。

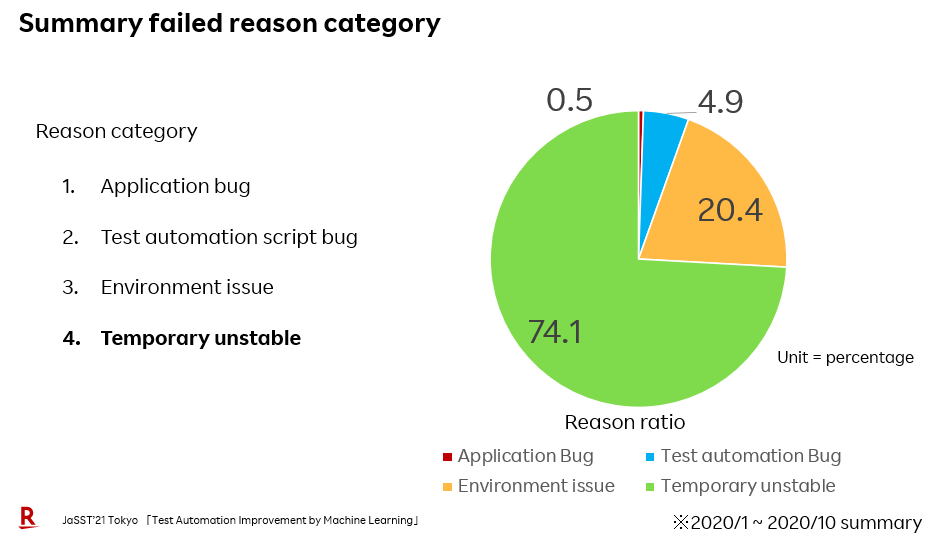
下図が、これまでの失敗の原因分析をした結果を表したものです。
大きく4つに分類されます。
1.Application bug
2.Test automation script bug
3.Environment issue
4.Temporary unstable
temporary unstableのバグが3/4を占めてることがわかります。
では、具体的なtemporary unstableの例は以下の通りです。
network断やtimeout等のように、一時的に発生する問題です。
この問題の場合、たいていの場合テストの再実行で復旧します。(テストのステータスがグリーンになる)
この作業は非常に非生産性であり、また3/4と量が多い!!
この、非生産性の課題を解決しないといけない。

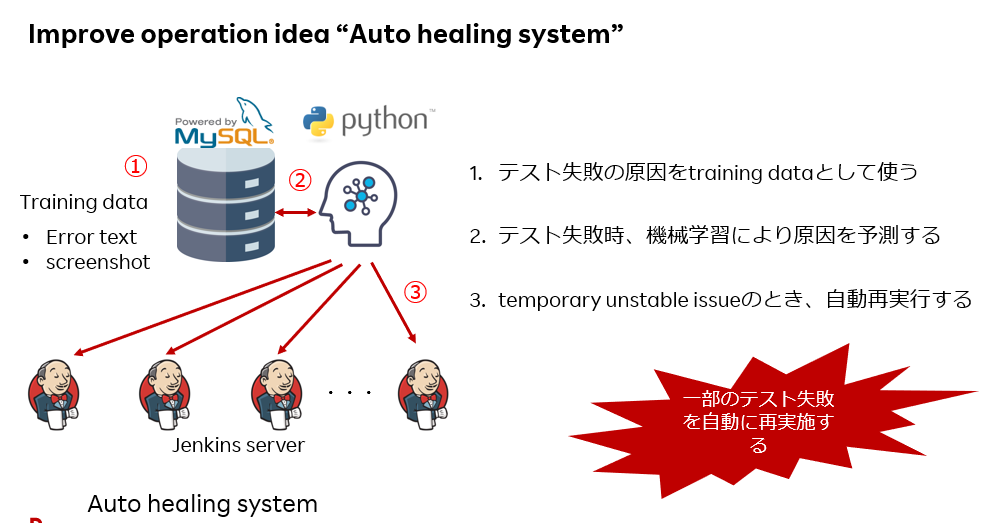
そこで、この非生産性作業を自動化することを試みた。
まず、テスト失敗のレポートを、原因のラベル付けを行い、training dataとして蓄積する。
次にテスト失敗が発生したときに、training dataをもとに機械学習により原因を予測する。
予測の結果、temporary unstableであった場合、テストの再実行を自動で行う。(auto healing system)
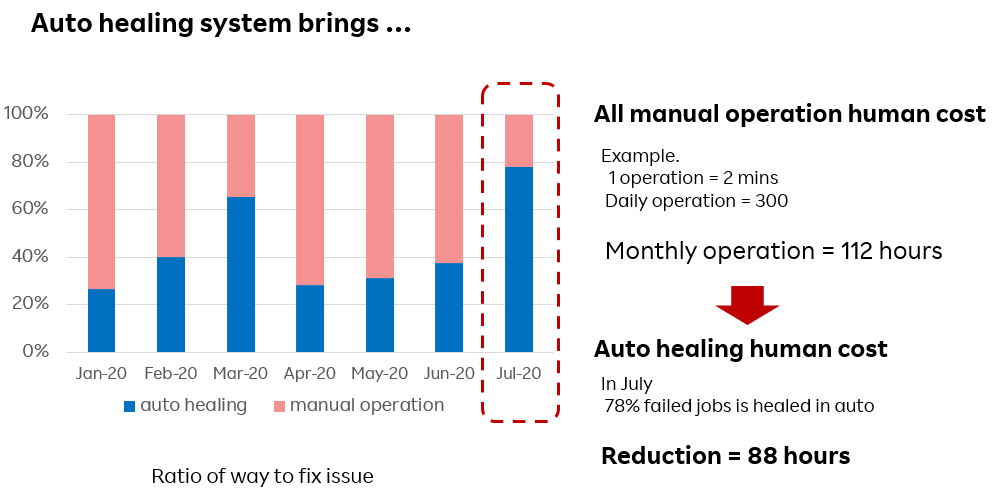
これによる効果が、下図のグラフである。
100%がテスト失敗のすべてを示す。
そのうち、青いエリアが今回のauto healing で自動復旧されたもの。赤いエリアが手で原因分析・対応を行ったものになります。
2020/7には、78%がauto healingにより自動復旧されているため、大幅な運用コスト削減が行われた。
この対応により、以下の効果が得られた。
・テスト自動化運用の効率化
・もっと知的な作業への集中
Q&A
Q1.
「マニュアル(手動)チームと自動チーム」に組織を分離したことでの効果
マニュアル=開発チームとの調整役、マニュアルテストの設計、実行
自動化=マニュアルからのテスト設計の共有を受け、scriptとoperationに集中
このようにロールを明確に分けることで、自動化は自動化に専念することができることが、効果かと。
Q2.
運用問題の対応ですが、とりあえずn回リトライし、それでもだめならば人が調査にはいる、のような仕組みでもいいのかな
テストリソースを無駄にしないためです。
全てを再実行すると、エラーになるであろうテストも再実行でテストリソースが消費され、テスト順番待ちもそれに合わせて増えてしまうためです。
また、テストによって半端なエラーで終わったテストでテストデータがおかしくなった状態で再実施すると、悪化する可能性もあるからです。
例)パスワード失敗でエラー → 繰り返し実施 → アカウントがロックされてしまう とか。
