はじめに
以前steamsale.meという海外ゲーム関連のサイトを作って公開したところ、
サイトを通じて色んな方と出会いがありまして、僕にとって良い刺激になり、きちんと公開してよかったと思っています。
その方々とお話していると、クローラやシステムについて聞かれることが多く、
僕自身筆不精なのでこういった記事を書くのは苦手なのですが、どこかの誰かの役に立てたらと思いまして、記事として残しておこうと思います。
作ったサイト
CROWDY(クラウドソーシングの一括検索サイト)
http://crowdy.jp/
クラウドソーシングサイトとは、フリーランサーや在宅ワーカーが仕事案件を見つけられ、企業側は発注できるサイトです。
僕自身も利用して仕事を受けたことがあり、その時に1箇所でサクサク仕事を探せるサイトがあったらいいなと思い作りました。製作期間は約2ヶ月です。
構造はほとんどSTEAMSALEと同じですが、復数のクラウドソーシングサイトを復数のクローラで取得して
1つのDBに纏めていますので、クローラのチューニングが結構重要でした。
クローラシステム
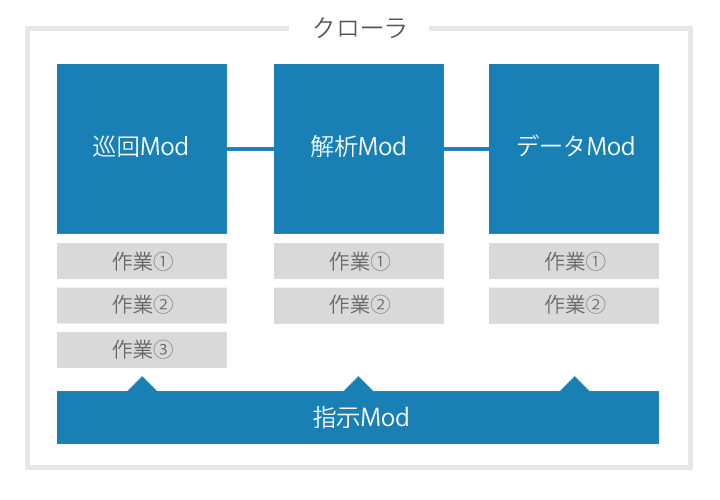
STEAMSALEはもともと内輪向けシステムでして、クローラ自体も個人的に組んだものです。
CROWDYでも同じシステムを使用、基盤はphp+pearで作成されています。
クローラは主に4種類の独立した役割(以下Mod)で構成されており、設定ファイルを渡すだけで自動巡回してくれる設計です。
指示Mod
設定ファイルを元に他のModに作業を与える役割です。
ページごとの更新頻度や重要度で調整したり、優先すべき作業が出てきた場合には、それぞれのModの作業キューの順番を入れ替え、効率を管理します。
現在のマシンのメモリ残量や実行プロセス数を監視しており、それにより実行頻度を調整します。
巡回Mod
実際のサイトにアクセスしリンクを集める役割です。
取得時間なども記録しており取得済みのリンクはスキップします。
ページに解析が必要な場合、サイトをクローラ内にキャッシュします。
解析Mod
キャッシュされたページを解析し、データファイルを出力する役割です。
またデータファイルからURLを取得して解析する機能もあり、巡回しなくてもページ決め打ちで取得することも可能な仕様にしています。
データMod
作成されたデータファイルから、DBに保存したり、最終的なデータの形にする役割です。
データファイルを再利用してさらに解析Modに渡すこともあるため、柔軟性のある仕組みにしています。
これらのModをクローラの管理画面から作成し、つなげ、設定ファイルを作成する感じです。
raspberry-piを使ったクロールマシンの長所と短所

クローラは24時間体制で動かすため、出来るだけ省電力でコア数の多いPCが望ましいと思い、
mini-itxで構築できるサーバーも検討したのですが、まずは安価で手に入るraspberry-piで構築を始めてみました。
長所
- 電気代が安い。場所を取らない
- ボード自体の価格が安いので、拡張性が高い(単純にマシンの買い足しが容易)壊れてもあまり凹まない
- raspberry pi2modelBから4コアになったこともあり、並行処理にそれなりに強く、クローラとして結構優秀。
短所
- 謎の故障が多い。
- STEAMSALEのときは印象として、セールの更新が朝の4、5時くらいに一気にくることが多かったのでクローラの調子が悪い時は難儀しました。
- チューニングの結果、今はある程度安定していますが、たまに謎の再起動や電源が入らなくなったり
- 書き込みエラーが起こったりと、ほっといて大丈夫というわけにもいかないようです。
raspberry-pi設定メモ
raspberry-piの設定は現在も思考錯誤中なので、暫定的な設定です。
config.txtのチューニング
俗にいうオーバークロックです。高過ぎるとハングアップし、低すぎても処理が追いつかずハングアップするので
コーディングの効率化に併せてチューニングします。
ちなみにraspi-configでも設定できるのですが、どうもかゆい所に手が届かないので、手動で設定したほうがよさそうです。
今回は下記の様な設定で動かしています。
arm_freq_min=700
arm_freq=900
core_freq=250
sdram_freq_min=400
sdram_freq=450
over_voltage=2
gpu_mem=16
watchdogの導入
ある条件になると再起動がかかるようになるモジュールです。
とりあえず1分あたりのload-averageが10を超えたら再起動するように設定しています。
sdcardへの書き込み軽減
かなりハードに読み書きを繰り返すので、出来るだけsdcardの寿命を伸ばす為
swap削除したり、ログファイルの書き込みを制限したりしています。
VPNの導入
外出先でのサーバー監視用にsoftether vpnclientを導入しています。
rootでログイン
なんとなくsudo苦手なんです…
特徴語検出と類似レコードの抽出
CROWDYを作るにあたり必要になると思っていたのが「似たような案件を取得する機能」でした。
いくつか試してみたのですが、今回は形態素解析とTF-IDFという方法からヒントを得て、類似レコードを選出してみました。
形態素解析はmecabを利用したのですが、そのままの辞書では足りないのでwikipedia等の百科事典サイトの見出し語やCROWDY内の特徴語を再帰的に利用して、辞書を作成する必要がありました。
これらを使って、例えば「phpでのWebシステム開発のプログラマー募集」であれば
「プログラマー php システム開発 Web」というキーワードを取得できるので、あとは全文検索で類似記事を取得できる、という仕組みです。
まだ試行錯誤段階で変な特徴語を取ってきたり(500円等、数字が入っていたりひらがなのみの単語の抽出に弱い)してしまうので
少しずつチューニングが必要のようです。
クラウドソーシング関連に限らず、大量のデータを用意して精度を上げる研究を続けていきます。
終わりに
今後の課題としまして、復数のraspberry pi間での負荷分散処理や監視処理等、
並列コンピューティングらしきことができれば面白いなぁと思っています。
(小さな処理を大量の端末で並行処理する、というのに憧れます)
こういったサイトに投稿するのは初めてで、見苦しい点もあるかと思いますが
サイト共々、お役に立てれば幸いです。
まだまだ未熟ではありますが、今後ともよろしくお願い致します。
リソース
- GMOクラウドVPS - Web・データベースサーバー
- Raspberry Pi2 model B - クローラー、シングルボードのすごく小さいコンピュータ
- Bootstrap - デザインテンプレート
- php - プログラム
- MySQL - データベース
- Mroonga - 全文検索エンジン
参考サイト
-
Raspberry Pi での謎のハングアップ対策(watchdogtimerで再起動)
https://linux.yebisu.jp/memo/999 -
街角のリブロガー: raspberry piでフリーズしたら自動で再起動する
http://www.srchack.org/article.php?story=20131120111723365 -
RaspberryPiをオーバークロックする - Qiita
http://qiita.com/key/items/94c1391950c5230b1ff6 -
Raspberry Pi B+ のSDカードの寿命を延ばすために - N@i Blog
http://y-naito.ddo.jp/index.php?id=1416793317 -
Raspberry Pi B+ のオーバークロック - N@i Blog
http://y-naito.ddo.jp/index.php?id=1417228001 -
Linux on Flash blog: A look at Raspberry Pi 2 performance and overclocking
http://linuxonflash.blogspot.jp/2015/02/a-look-at-raspberry-pi-2-performance.html -
TF-IDFで文書内の単語の重み付け | takuti.me
http://takuti.me/note/tf-idf/ -
形態素解析と検索APIとTF-IDFでキーワード抽出
http://chalow.net/2005-10-12-1.html -
テキストからWikipedia見出し語を抽出
http://aidiary.hatenablog.com/entry/20101230/1293691668 -
軽量データクラスタリングツールbayon - mixi Engineers' Blog
http://alpha.mixi.co.jp/entry/2009/10714/