最近、コロナウイルスの情報がたくさん出回っていますが、誰が投稿したかわからないような情報だと正しいかどうか判断が難しいと思います。
真に正しい情報を得るには、なるべく一次情報を自分で分析するべきです。この記事では、北海道が公開している陽性患者属性データを使って、年代ごとの重症率を比較します。
データ読み込み
分析にはPythonのPandasを使います。まずはPandasをインポートします。
import pandas as pd
続いて、データを読み込みます。
df = pd.read_csv("https://www.harp.lg.jp/opendata/dataset/1369/resource/3132/010006_hokkaido_covid19_patients.csv", encoding="shift-jis")
読み込んだデータはheadメソッドなどで確認できます。
df.head()
年代と重症度のカテゴリ分け
さて、今回は年代ごとの重症度を比較していきます。まずは、現在のデータではどのようにカテゴリ分けされているかを確認します。
まずは年代から見てみます。
df["患者_年代"].value_counts()
非公表 231
20代 223
70代 219
60代 202
50代 193
40代 176
80代 163
30代 157
90代 75
10代 33
10未満 16
100代 5
10歳未満 4
高齢者 1
Name: 患者_年代, dtype: int64
概ね、「~代」で分けられていますが、一部表記ゆれ(10未満と10歳未満)や年齢不詳(高齢者と非公表)があります。
既存のカテゴリでは分析がやりづらいので、こちらでカテゴリを定義し、それぞれのデータに新たなカテゴリを割り振ります。
まずは、元のカテゴリが新しいカテゴリのどれに当てはめるかを定義します。
age_dict = {
"10未満": "10代以下",
"10歳未満": "10代以下",
"10代": "10代以下",
"20代": "20代",
"30代": "30代",
"40代": "40代",
"50代": "50代",
"60代": "60代",
"70代": "70代",
"80代": "80代",
"90代": "90代以上",
"100代": "90代以上",
"非公表": "不明",
"高齢者": "不明"
}
次に、新たなカテゴリ列をDataFrameに追加します。
df["年代カテゴリ"] = [age_dict[key] for key in df["患者_年代"]]
ここで定義した年代カテゴリを元に、重症者数の集計を行います。
同じように、患者状態についても元カテゴリの確認と新しいカテゴリの定義を行います。
df["患者_状態"].value_counts()
軽症 会話可 1004
− 108
非公表 102
無症状 102
無症状 会話可 97
軽症 88
軽症、会話可 54
中等症 会話可 35
軽症・会話可 30
中等症 29
重症 13
重症 会話不可 9
ベッド上安静、会話可 7
無症状、会話可 5
重傷 会話不可 3
死亡後陽性が判明 2
中等症 会話不可 2
症状なし 会話可 2
ベッド上安静 会話可 1
陰性確認済み 1
軽症 高熱 1
調査中 1
意思疎通程度 1
中等症・会話可 1
Name: 患者_状態, dtype: int64
stat_dict = {
"重症": "3.重症",
"重症 会話不可": "3.重症",
"重傷 会話不可": "3.重症",
"中等症 会話可": "2.中等症",
"中等症": "2.中等症",
"中等症 会話不可": "2.中等症",
"中等症・会話可": "2.中等症",
"軽症 会話可": "1.軽症",
"軽症": "1.軽症",
"軽症、会話可": "1.軽症",
"軽症・会話可": "1.軽症",
"軽症 高熱": "1.軽症",
"無症状 会話可": "0.症状なし",
"無症状": "0.症状なし",
"無症状、会話可": "0.症状なし",
"症状なし 会話可": "0.症状なし",
"−": "不明",
"非公表": "不明",
"ベッド上安静、会話可": "不明",
"死亡後陽性が判明": "不明",
"意思疎通程度": "不明",
"陰性確認済み": "不明",
"調査中": "不明",
"ベッド上安静 会話可": "不明"
}
df["状態カテゴリ"] = [stat_dict[key] for key in df["患者_状態"]]
これで、年代カテゴリと状態カテゴリの割り当てが完了しました。実際にどのように割り当てられたかはheadメソッドなどで確認できます。
df.head()
年代ごとの重症者数の集計
カテゴリの準備ができたので、さっそく状態カテゴリごとの患者数集計を行います。集計にはcrosstabによるクロス集計を採用しました。
// matplotlibの日本語化
pip install japanize-matplotlib
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
pd.crosstab(df["年代カテゴリ"], df["状態カテゴリ"]).apply(
lambda x: x/sum(x), axis=1
).plot(
kind="bar",
logy=True,
rot=45,
figsize=(8,4),
color=["grey", "grey", "orange", "red", "grey"]
).legend(loc="upper left")
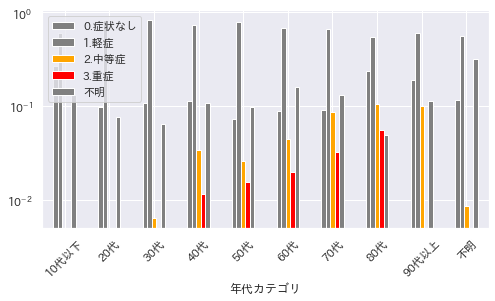
全体的に中等症、重症の数は少なめ(10%未満)なので、y軸を対数表示にしました。
コロナウイルスは若者では軽症でとどまり、高齢者では重症化しやすいとよく言われていますが、実際に集計してみると確かにその傾向がみられます。
30代までは中等症、重症例はほぼ存在しなく、40代から80代にかけて年齢に比例して重症者数の割合が明らかに増加しています。
まとめ
今回は、北海道のコロナウイルス陽性者属性データを用いて、重症化率が年齢に比例して大きくなることを確認しました。
このように、国や都道府県が公開している一次データを自分で分析することで、より正確な知見を得ることができます。
オープンデータが必ず正しいというわけでもありませんが、なるべく正確な情報をすばやく得るための方法の一つとして、今回紹介した方法を試してみてはいかかでしょうか。
以上です。