・ 判別分析など多くのものにあるオプション
・ サンプル数の偏り
・ 何を見つけたいか?
重みづけ
言葉の通り、たとえば、比重1のものに、比重10の重みを付けて計算することです 機械学習のライブラリをはじめとして、いろいろなツールに重みづけのオプションがあるのですが、意味を図で説明してみようと思いました ここでは、線形判別という機械学習に対して使ってみます 重みづけは、機械学習以外にも、回帰分析など、サンプルを統計的に扱うところにはオプションとしてついています
重みづけをしなかったらどうなる
まず、重みづけをしないと、困る様子を、先にみてみましょう

赤(画像ではピンク)100個、青100個 からなる上のようなサンプルがあったとします
青 100 個
赤 100 個

判別分析のツールを使って、X軸の変数、Y軸の変数の2変数を使って、2つのグループに分けてみます 線形判別を使うので、境界はまっすぐな線です 線をひきます 赤全体のうち、76 % を、上手く赤のグループに分けることができました
次に、青のサンプルを 300に増やしてみます
青 300 個
赤 100 個

あれ? 同じ方法を使って、赤のサンプルのうち正解は24 % になりました
さらに青を増やしていきます
青 1000 個
赤 100 個

赤の正解率は 1 % になってしまいました! なぜなら、青の個数が、赤の 10倍 もあるので、全体の正答率を上げようとすると、青の正解の割合を上げたほうが、赤と青の平均の正答率は高くなるからです つまり、少数派の赤は、ほとんど無視されてます
※ どう分類するかの設定は、実は変えることができるのですが、少なくとも、ここで使っている機械学習ライブラリのデフォルトの設定ではそうなっています
動画も作ってみました

重みづけ
さて次に、赤に 10倍の 重みづけをすると、こんな風になります 10倍というのは、青に 1 の重みを付けたときに、赤には 10 の重みを付けて判別モデルを作ったということです

一番最後の画像ではこうなっています
青 1000 個
赤 100 個
なのに、72 % の割合で赤が正解しています 重みづけをしない場合の、いくつかの上のほうの図と比べてみると、ちょっと数値が違いますが、青 100 個、赤 100 個 の 76 % のときに近い割合ですね
少ないものを検出する
たとえば医療の領域では、特定の疾患の患者さんのデータを集めることと同時に、患者さん以外のデータ(Healthy Control 健常群と呼びます)も集めます。人口全体の中で患者さんは少数派です 通常、機械学習で検出したいのは、割合が少ないほうの患者さんグループです
機械学習モデル作るときに使うデータにはたいてい限りがあって、一部分だけ集められる状態だったり、とりあえず試してみたいから、手に入りやすいデータだけを使ってみたりすると思います 病院でデータを集めると、患者さんのデータをたくさん集めることができますが、町の中でデータを集めると、健常群の中に少数派の患者さんがまざるデータになるでしょう
重みづけは、機械学習に使うサンプル数に偏りがあるときにも使えますが、おそらく一番の目的は、割合が少ないサンプル(この場合は赤)を検出したいときに、そこに重みを付けることで検出できるようにすることです
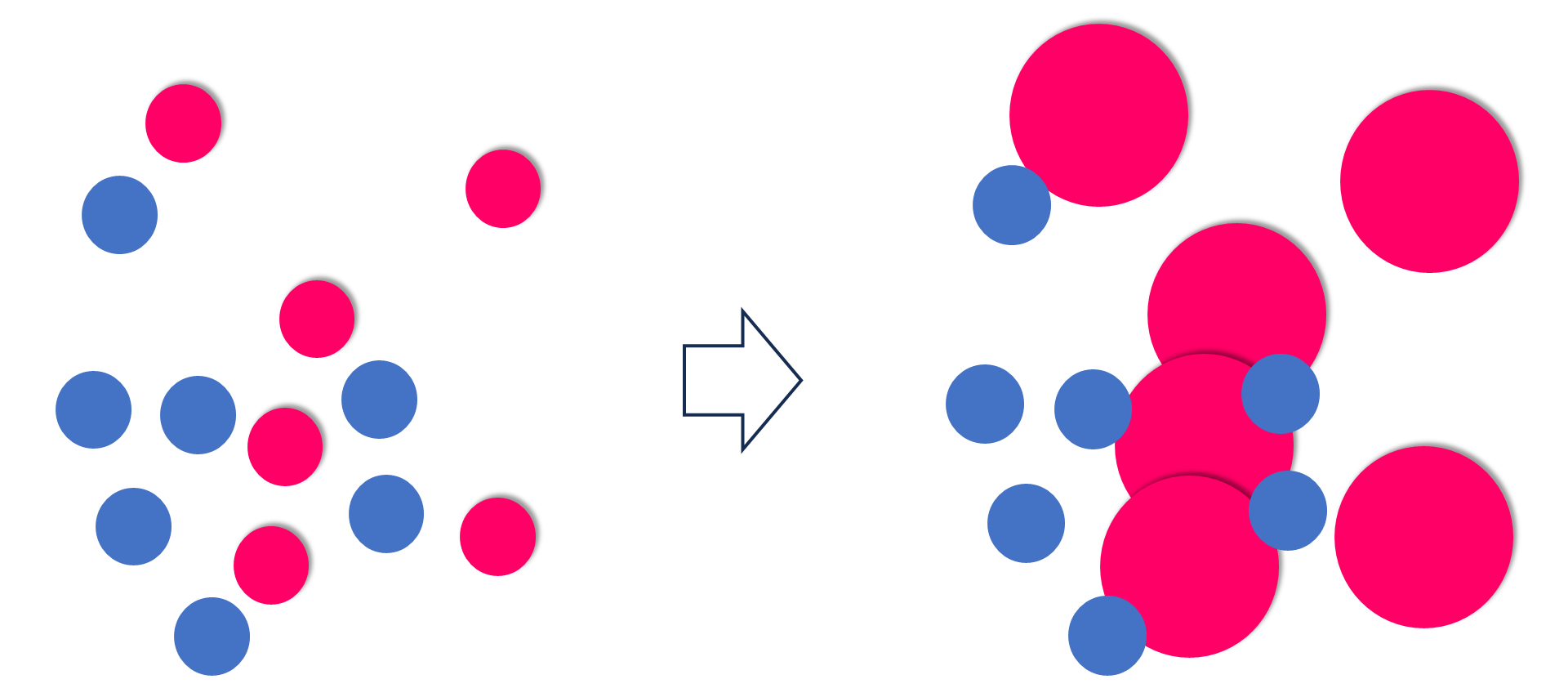
赤への重みづけのイメージです 赤が重要なんですね