オフラインリアルタイムどう書くE03に参加してきました。
戦略
まず、凸頂点がどのような条件で現れるのかを考えました。
結論として、今回の問題では00の図形を除くと共有される頂点(下図の赤で示した箇所)は必ず凹頂点になるため、逆に言うと共有されない頂点(下図の青で示した箇所)が凸頂点となるため、すべての図形の頂点を取得し、一度しか現れない頂点の個数を数えることで凸頂点の個数を求めることができます。

ただし、00の図形は凹頂点を含んでいるため、頂点を共有しないにもかかわらず凹頂点になる場合があるので、その部分を取り除いてから数える必要があります。

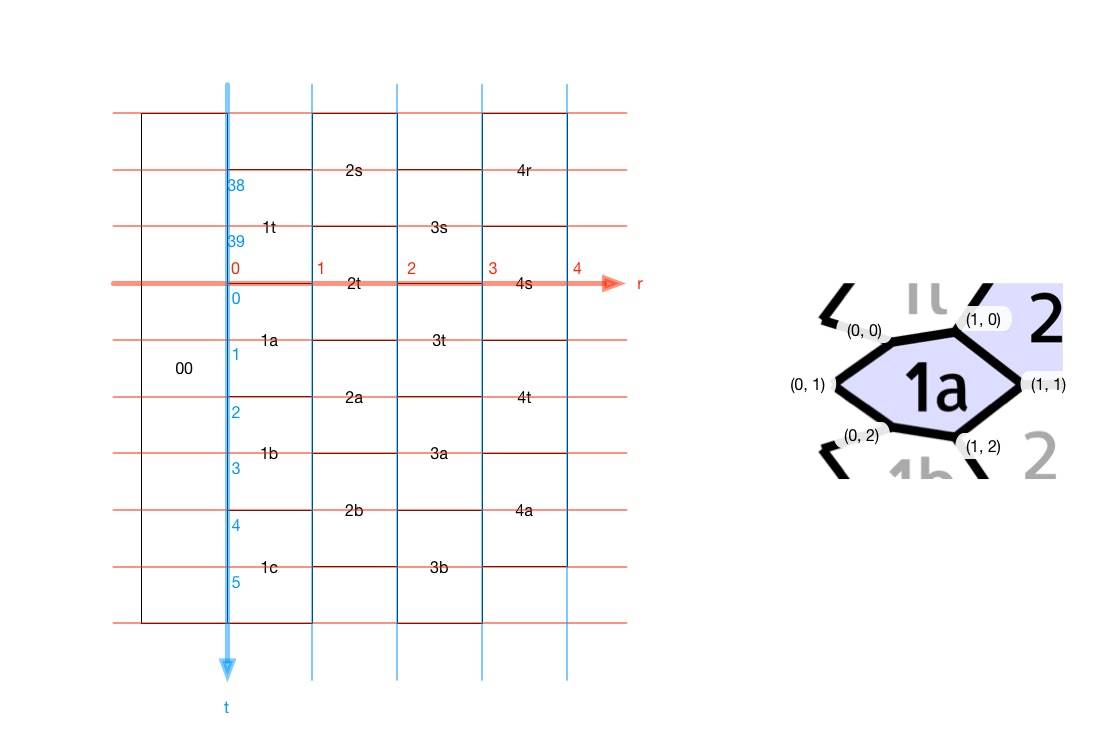
頂点は、半径方向の数字を r 、回転角方の文字 a 〜 t を数値の 0 〜 19 に置き換えたものを tとして、次のように定義しました。
\begin{eqnarray*}
vertex_{hex} & = & (r - d_r, 2t + r - 1 + d_t \pmod{40}) \\
ここで \\
d_r & = & \lbrace 0, 1 \rbrace \\
d_t & = & \lbrace 0, 1, 2 \rbrace
\end{eqnarray*}
頂点の座標の取り方は、図に表すと次のようになります。
Ruby(時間内に解いたもの)
今回は Ruby で挑戦し、おそらく初めて時間内に全テストが通るコードを書くことができました。
共有されない頂点の個数を数えればよいということに気がつくまでおよそ20分、そこからコードを書き始めておよそ30分、計50分あまりでの書き上げました。
00の凹頂点は、全頂点を取得後に図形に00が含まれる場合は凹頂点になる点をすべて取り除くという方法で対処しています。
見返してみると冗長なコードが散見されます。
Ruby
後になって、00の凹頂点を数えないようにするには、後から点を取り除くのではなく凹頂点を最初から複数回登録すれば頂点が共有されているとみなされて数え上げの対象から外すことができることに気がつきました。
それを踏まえて書き直したのがこちら。さらに短くなりました。
def solve(input)
input
.chars
.each_slice(2)
.each_with_object([]) {|(r, t), a|
r, t = [r, t] == ['0', '0'] ? [0, 0] : [r.to_i, t.ord - 'a'.ord]
if [r, t] == [0, 0]
40.times {|i| a.push [0, i] }
20.times {|i| a.push [0, i * 2 + 1] }
else
[0, 1].product([0, 1, 2]).each {|dr, dt| a.push [r - dr, (t * 2 + r - 1 + dt) % 40] }
end
}
.group_by {|r, t| [r, t] }
.map {|k, v| [k, v.size] }
.select {|k, size| size == 1}
.size
.to_s
end
# 以下テスト実施用コード
def test(input, expected)
actual = solve(input)
if actual == expected
print '.'
else
puts <<-EOS
input: #{input}
expected: #{expected}
actual: #{actual}
EOS
end
end
DATA.each do |line|
test *line.split
end
puts
__END__
1a2t3s2s 11
1a1c1d00 22
Haskell
メソッドチェインで書くことができたので、Haskell で書くと綺麗に書けそうだと思い翻訳してみたのがこちら。
頂点を取得する関数がまた分離しましたが、solve 関数をポイントフリースタイルで書けたので満足です。
import Data.Char
import Data.List
vertices [] = []
vertices ('0':'0':cs) =
[(0, t) | t <- [0..39]] ++ [(0, t * 2 + 1) | t <- [0..19]] ++ vertices cs
vertices (c1:c2:cs) =
[(r - dr, mod (t * 2 + r - 1 + dt) 40) | dr <- [0, 1], dt <- [0..2]] ++ vertices cs
where
r = ord c1 - ord '0'
t = ord c2 - ord 'a'
solve = show.length.filter (==1).map length.group.sort.vertices
-- 以下テスト実施用コード
test input expected =
if actual == expected
then
putStr "."
else
putStrLn $ concat
[ "\ninput: ", input
, "\nexpected: ", expected
, "\nactual: ", actual
]
where
actual = solve input
main = do
test "1a2t3s2s" "11"
test "1a1c1d00" "22"
-- 以下略
Prolog
Haskell で書けたのだから Prolog でも書けそうだ、と翻訳したのがこちら。
「複数回出現しない要素の数を数える」よい方法が思いつかなかったため、まず各々の要素を要素の出現回数に置き換えたリストを作成し、そのリストの中から値が1の要素の数を数える、という方法を取っています。
具体的には、[a, b, a, c] というリストがあった場合、それぞれの出現回数(a は 2 回、b と c は 1 回)に置き換えた [2, 1, 2, 1] というリストをまず作成し、そこから値が 1 の個数を数える、ということをしています。
:- initialization(main).
hex_vertex(R, T, DR, DT, [R1 ,T1]) :-
R1 is R - DR,
T1 is (T * 2 + R - 1 + DT) mod 40.
vertices([], []).
vertices([0'0, 0'0|CS], VS) :-
findall(V, (between(0, 39, T), append([0], [T], V)), VS1),
findall(V, (between(0, 39, T), T mod 2 =:= 1, append([0], [T], V)), VS2),
append(VS1, VS2, VS3),
vertices(CS, VS4),
append(VS3, VS4, VS).
vertices([C1, C2|CS], VS) :-
R is C1 - 0'0,
T is C2 - 0'a,
findall(V, (between(0, 1, DR), between(0, 2, DT), hex_vertex(R, T, DR, DT, V)), VS1),
vertices(CS, VS2),
append(VS1, VS2, VS).
elems_counts([], _, []).
elems_counts([E|ES], List, [C|CS]) :-
findall(E0, (member(E0, List), E0 == E), ES0),
length(ES0, C),
elems_counts(ES, List, CS).
elems_counts(ES, CS) :-
elems_counts(ES, ES, CS).
solve(Input, Output) :-
vertices(Input, VS), % 全頂点を取得する
elems_counts(VS, CS), % 要素を要素の出現数に変換する
findall(C, (member(C, CS), C =:= 1), CS1), % 出現数が 1 の要素のみ抽出する
length(CS1, Count), % 出現数が 1 の要素の個数を数える
number_codes(Count, Output). % 個数を文字列にする
% 以下テスト実施用コード
judge(_, Expected, Expected) :-
format(".", []).
judge(Input, Expected, Actual) :-
format("~ninput: ~s~nexpected: ~s~nactual: ~s~n", [Input, Expected, Actual]).
test(Input, Expected) :-
solve(Input, Actual),
judge(Input, Expected, Actual).
main :-
test("1a2t3s2s", "11"),
test("1a1c1d00", "22"),
test("00", "20"),
% 中略
format("~n", []),
halt.
C++
全頂点を集めてから出現回数を数えるのは C++ では面倒な感じだったので、代わりに頂点を求めるたびに個数を数えていくという方法を取っています。
# include <iostream>
# include <string>
# include <map>
# include <numeric>
typedef std::map<int, int> Vertices;
const int ds[][2] = { {0, 0}, {0, 1}, {0, 2}, {1, 0}, {1, 1}, {1, 2} };
void vertices(const std::string& input, Vertices& vs)
{
auto ci = input.begin();
while(ci != input.end())
{
if((*ci == '0') && (*(ci + 1) == '0'))
{
for(int i = 0; i < 40; ++i)
{
vs[i] += (1 + i % 2);
}
}
else
{
int r = *ci - '0';
int t = *(ci + 1) - 'a';
for(auto di = std::begin(ds); di != std::end(ds); ++di)
{
++vs[(r - (*di)[0]) * 40 + (t * 2 + r - 1 + (*di)[1]) % 40];
}
}
advance(ci, 2);
}
}
std::string solve(const std::string& input)
{
Vertices vs;
vertices(input, vs);
int count = std::accumulate(vs.begin(), vs.end(), 0, [](int a, const std::pair<int, int>& v) { return (v.second == 1) ? (a + 1) : a; });
return std::to_string(count);
}
// 以下テスト実施用コード
void test(const std::string& input, const std::string& expected)
{
std::string actual = solve(input);
if(actual == expected)
{
std::cout << ".";
}
else
{
std::cout
<< "\ninput: " << input
<< "\nexpected: " << expected
<< "\nactual: " << actual
<< "\n";
}
}
int main(int, char* [])
{
test("1a2t3s2s", "11");
test("1a1c1d00", "22");
// 中略
std::cout << std::endl;
return 0;
}
Ruby 三度び
C++ の std::map で頂点を求めるたびに個数を数えるという方法は、Ruby でも Hash を使えば同じことができるので、もう一度 Ruby に翻訳してみました。test 以下は同じなので、solve のみです。
def solve(input)
input
.chars
.each_slice(2)
.each_with_object(Hash.new(0)) {|(r, t), a|
r, t = [r, t] == ['0', '0'] ? [0, 0] : [r.to_i, t.ord - 'a'.ord]
if [r, t] == [0, 0]
40.times {|i| a[[0, i]] += (1 + i % 2) }
else
[0, 1].product([0, 1, 2]).each {|dr, dt| a[[r - dr, (t * 2 + r - 1 + dt) % 40]] += 1 }
end
}
.select {|k, size| size == 1}
.size
.to_s
end