想定
- 主にWebサーバ
- HTTPレスポンスが「著しく遅い」もしくは「レスポンスコード異常」等
-
コマンドに重きを置いているため、リソース監視や死活監視等のツールを使用しない
ざっくり言うと「サーバ過負荷」を想定
1. ssh
OpenSSH SSH client (remote login program)
$ ssh -vvv サーバーホスト
もちろんまずは障害が発生しているであろうサーバにログインする事からスタート。
ここで注目すべきはオプションの -vvv
-v
冗長表示モード。ssh が進行中のデバッグメッセージを表示するようにします。これは接続や認証、設定の問題をデバッグするときに助けとなります。複数の-v オプションをつけると出力が増えます。最大は 3 個です。
このオプションにより、そもそもSSHにてサーバにログインする事が困難な際、SSHコネクション途中のどの箇所で詰まっているか等を確認する際の情報収集が容易になる。
2. w
Show who is logged on and what they are doing
$ w
02:00:08 up 185 days, 5:30, 4 users, load average: 5.30, 1.12, 0.16
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
nishikaw pts/0 p2313220-ipngn17 01:06 0.00s 0.00s 0.00s screen -dr
nishikaw pts/1 :pts/0:S.0 01:06 122days 2:04 2:04 emacs -nw
nishikaw pts/2 :pts/0:S.1 01:06 12days 0.01s 0.01s /bin/bash
nishikaw pts/3 :pts/0:S.2 01:06 26days 0.01s 0.01s /bin/bash
ログイン後、まず実行したいコマンド。サーバ過負荷時は1秒単位でコンソール作業も重くなる一方。てっとり早く状況確認するには w。コマンドレスポンスも早いため、重宝。
結果1行目左から 稼働時間, 接続ユーザ数, 過去1分平均負荷, 過去5分平均負荷, 過去15分平均負荷。2行目以降はログインユーザのセッション情報。
上の結果を見ると、負荷が次第に強くなっている事が分かる。(汗)
3. top
display Linux tasks
$ top -d 1
uptimeで状況確認後はさっそく問題になっているプロセスを探そう。top はロードアベレージはもちろん、各プロセスをメモリ・CPU等の使用率までまるわかり、しかもプロセスの実行PATHまで表示してくれるというスグレモノ。だいたいはこのTOPコマンドで原因が特定できることが多数。
オプションは -d 1 これは1秒毎に状況を更新するよう促すオプション。
-d
Delay time 3.0 seconds
(遅延時間 デフォルトは3秒毎更新)
サーバは刻一刻と過負が高まっているのに3秒なんてまっていられない。
なお実行後は、まず c を押す。そうする事で各プロセスの実行パスが表示される。以下が c の Before After。
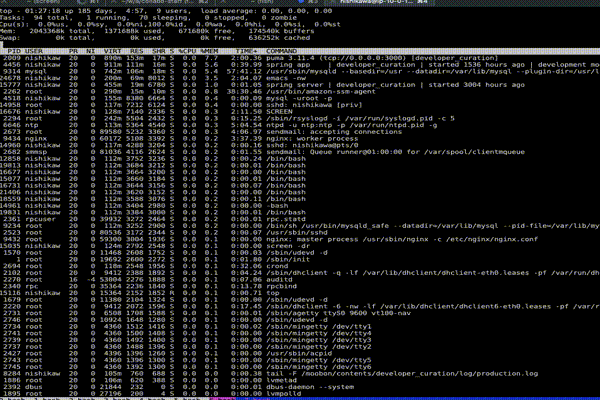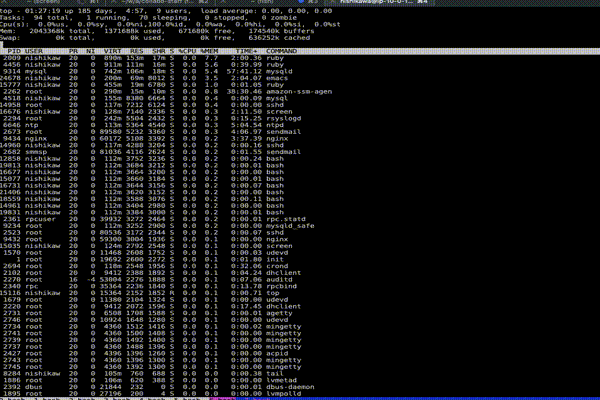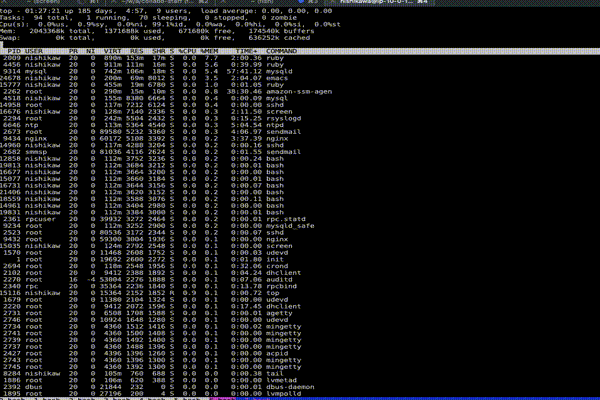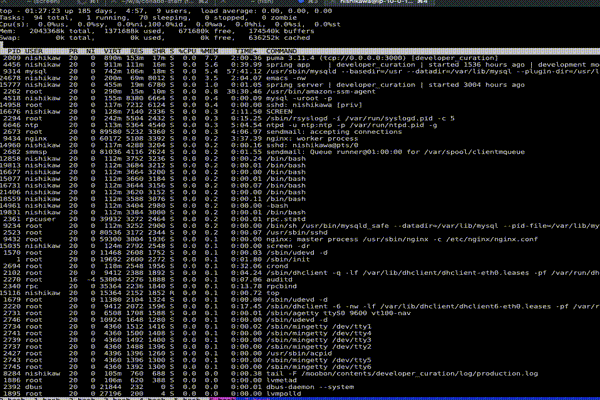
少し早くてわかり辛いかもしれないが、プロセスの実行起点が分かるため原因追求に役立つ。
top コマンドはまだまだ続く。ここでようやくサーバ過負荷の原因となっているプロセス追求に向かう。以下の2つを押し比べてみよう。
shift+p CPU使用率順(デフォルト)
shift+m メモリ使用率順
shift+p CPU使用率順(デフォルト)
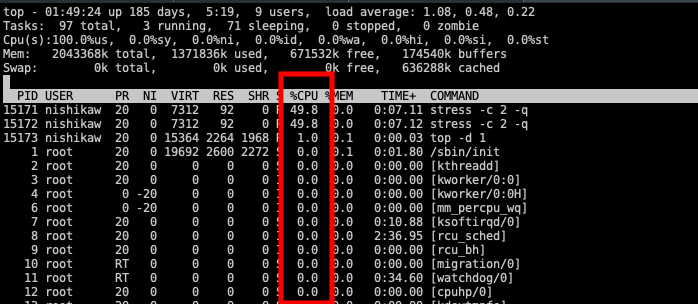
上の例では CPU使用率が49.8%という異常なプロセスが2つ存在している事が容易に確認できる。
shift+m メモリ使用率順
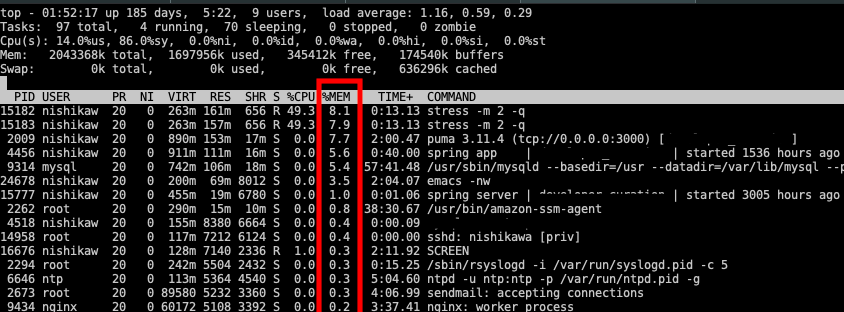
メモリ使用率順にしても同様に %MEM 列を見ると上位2つのプロセスが確認できる。
(上の例では同様にCPU使用率が高いこともわかる。)
4. df
report file system disk space usage
$ df -h
基本的には 3.top でWebサーバ過負荷障害はある程度原因特定できる事が多数だが、未解決時は df を実行してみよう。 -h オプションで人間が読みやすい結果表示にしてくれる。
-h, --human-readable
print sizes in human readable format (e.g., 1K 234M 2G)
$ df -h
ファイルシス サイズ 使用 残り 使用% マウント位置
devtmpfs 988M 56K 988M 1% /dev
tmpfs 998M 0 998M 0% /dev/shm
/dev/xvda1 20G 4.2G 16G 22% /
残りがほぼない状態だったら disk full 状態に陥り、Webサーバプロセスがログファイルに書き込みできない OR MySQL 等でレコード生成できない障害発生等が起こる原因になる。
5. tail
output the last part of files
$ sudo tail -200 /var/log/messages | more
ここまで来たら、あとはもうログを探ろう。
/var/log/messages はミドルウェア等が吐き出す特定ログが多数書き込まれる。最新200行くらいをmoreを使ってゆっくりと流し読みしていこう。よーく見ていくと
Mar 22 9:01:22 fuga kernel: Out of Memory: Killed process 11231 (mysqld).
のような異常らしき行が見つかりやすい。
6. sar
Collect, report, or save system activity information.
$ sar -ubrq -s '11:00:00' -e '12:00:00'
| オプション | 説明 |
|---|---|
| u | CPU使用状況 |
| b | I/O |
| r | メモリ使用状況 |
| q | ロードアベレージ |
Linux 2.6.32-642.el6.x86_64 (ip-10-0-1-10) 10/09/2019 _x86_64_ (1 CPU)
11:00:01 AM CPU %user %nice %system %iowait %steal %idle
11:10:01 AM all 4.32 0.00 0.60 0.14 0.03 94.92
11:20:01 AM all 0.58 0.00 0.10 0.10 0.01 99.21
11:30:01 AM all 0.62 0.00 0.10 0.03 0.01 99.24
11:40:01 AM all 0.23 0.00 0.06 0.04 0.02 99.66
11:50:01 AM all 0.44 0.00 0.09 0.04 0.01 99.42
Average: all 1.24 0.00 0.19 0.07 0.02 98.49
11:00:01 AM tps rtps wtps bread/s bwrtn/s
11:10:01 AM 1.66 0.37 1.29 8.92 26.12
11:20:01 AM 1.39 0.27 1.12 54.13 22.35
11:30:01 AM 1.09 0.01 1.08 0.25 21.85
11:40:01 AM 1.10 0.00 1.09 0.01 21.78
11:50:01 AM 1.17 0.04 1.13 1.47 23.08
Average: 1.28 0.14 1.14 12.96 23.03
11:00:01 AM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit
11:10:01 AM 128060 890272 87.42 83180 241328 1821260 58.46
11:20:01 AM 110400 907932 89.16 84056 257372 1819680 58.41
11:30:01 AM 110260 908072 89.17 84784 257396 1819676 58.41
11:40:01 AM 108600 909732 89.34 85556 257424 1822788 58.51
11:50:01 AM 107556 910776 89.44 86304 257732 1822788 58.51
Average: 112975 905357 88.91 84776 254250 1821238 58.46
11:00:01 AM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15
11:10:01 AM 0 179 0.29 0.24 0.13
11:20:01 AM 0 176 0.03 0.10 0.11
11:30:01 AM 0 177 0.00 0.03 0.07
11:40:01 AM 0 179 0.00 0.01 0.05
11:50:01 AM 0 179 0.00 0.02 0.05
Average: 0 178 0.06 0.08 0.08