はじめに
本記事はAWS SAMを使おうと思っている・使い始めた人向けに
SAMを利用したサーバーレスアプリケーションの実装について
会社のスカンクワークを利用して社内サービスを実装したときのハマりポイントを踏まえて書きます
AWS SAMとは
AWS CloudFormation (以降 CFn) のサーバーレス拡張です
CloudFormationでLambdaなどを記述しようとすると記述が複雑になってしまうのですが、
SAM記法を使うと比較的簡潔に記述することができます
同様の仕組みとしてserverless framework( https://serverless.com/ )があります
「AWS公式のエコシステムに乗っておいたほうが、後々のメンテナンスに期待できるため、実務で使うならSAMのほうが信用できる。」
とAWSに詳しい会社の先輩が言っていたので、今回は学習のためにSAMを使ってみることにしました
今回作った構成要素
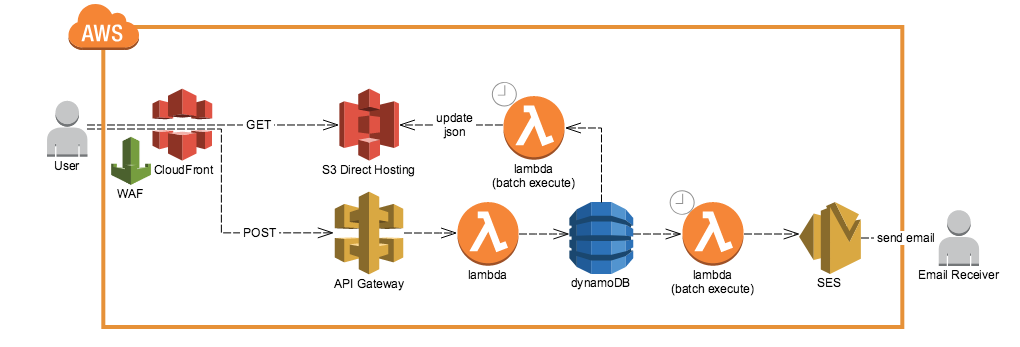
- S3のstatic hostingでフロントページ(React)を表示する
- 動的処理に関してはAPI GatewayでHTTPSアクセスを受け、そこからLambdaが起動してDynamoDBにデータを保存する
- 前段にWAFを紐づけたCloudFrontを置いて、IP制限(社内のみ閲覧)を行う
前提とする環境
- OS: macOSX El Capitan 10.11.6
- terminal: fish 2.6.0
- fishパッケージマネージャ: fisherman 2.12.0
- Lambdaを動かす言語: node 8.10
- jsパッケージマネージャ: yarn 1.7.0
基本的な心構え
- 公式ドキュメントを読む
1次情報を見るようにとはよく言われることですが、AWSの製品を使う利点としてドキュメントがきちんと書いてあることが挙げられます
分かりやすいのでwebの記事を読むことも多いですが、公式ドキュメントの存在を頭に置いておきましょう
(例えばSAMについては下記のページです)
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/with-ct-example-use-app-spec.html
CloudFormationの定義の方法なども「cloudformation dynamodb」などとググればすぐ出てきますので公式ドキュメントを頼りにしていきましょう
デプロイに関して
まずはawscliを最新にする
AWS SAMはawscliに統合されています
最新のawscliをインストールすることで使うことができます
過去にインストールしていた場合でも、バージョンが古い場合はSAM用のコマンドが欠けていてエラーになるため最新にしておきます
pip install --upgrade awscli
完了通知を設定する
これからawscliを使っていくのですが、cloudformationの実行には往々にして時間がかかります
コマンドが終わったことを通知してくれる仕組みがあると便利です
fisher install done
ディレクトリ構成を決める
開発リポジトリのディレクトリ構成は下記のようにしました
cloudformationの複数stackを使うことを想定し、
ソースコードとテンプレートをそれぞれディレクトリごとに分けるようにしています
テンプレートごとにディレクトリをきることで、aws-sam-localを使う際にテストデータを同梱するようにします
(今回の開発ではあまり使いませんでしたが)
※プロジェクトディレクトリ直下にpackage.jsonを置きます
├── script デプロイ用のスクリプトを入れます
├── src sam用のソースコードを入れます
│ └── your_stack_1 cfnテンプレートごとにディレクトリを分けます
├── templates sam記法または普通のcloudformationテンプレートを入れます
│ └── your_stack_1 cfnテンプレートごとにディレクトリを分けます
└── test テストコードを入れます
stackを複数使うことはあるか?
公式ドキュメントによるとライフライクルと所有権によってstackを分けるかどうか判断すべきとあります
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/best-practices.html#organizingstacks
ただライフライクルと所有権が同一である場合でも、CloudFormationの仕様が及ばない所に対して
awscliのスクリプトをstackの間に挟んで対応する必要がある場合があったりするので
複数stackを使うような構成にしています
デプロイスクリプトを書く
aws samでのデプロイはコマンドラインからコマンドを叩くことになるのですが
引数の処理や前処理など色々やることがあるのでスクリプトを書きたくなると思います
大した処理ではないのでサクッとshellscriptを書いてしまうことにします
下記のようにstack名を指定すれば、そのstackをデプロイできるようになります
sh script/deploy.sh your_stack_1
stackの削除は下記のようにできます
sh script/delete.sh your_stack_1
↓stackを作成または更新します
# !/bin/bash -eu
DIR=$(cd `dirname $0`/../; pwd)
cd $DIR
source script/settings.sh
# package if SAM syntax
if grep 'AWS::Serverless-2016-10-31' ${CFN_TEMPLATE} >/dev/null; then
echo '--- copy src directory and yarn install ---'
sh script/prepare_src.sh $@
echo '--- package ---'
aws cloudformation package \
--template-file ${CFN_TEMPLATE} \
--s3-bucket ${S3_BUCKET_NAME_FOR_SAM_PACKAGE} \
--output-template-file tmp/packaged-template.yml \
--profile ${AWS_PROFILE} \
;
template_file=tmp/packaged-template.yml
else
template_file=${CFN_TEMPLATE}
fi
echo '--- deploy ---'
aws cloudformation deploy \
--template-file ${template_file} \
--stack-name ${CFN_STACK_NAME} \
--capabilities CAPABILITY_IAM \
--profile ${AWS_PROFILE} \
${@:2}\
;
↓stackを削除します
# !/bin/bash -eu
DIR=$(cd `dirname $0`/../; pwd)
cd $DIR
source script/settings.sh
echo '--- delete-stack ---'
aws cloudformation delete-stack \
--stack-name ${CFN_STACK_NAME} \
--profile ${AWS_PROFILE} \
;
aws cloudformation wait stack-delete-complete \
--stack-name ${CFN_STACK_NAME} \
--profile ${AWS_PROFILE} \
;
↓Lambda関数のデプロイ前にnpmプラグインをインストールさせます
# !/bin/bash -eu
DIR=$(cd `dirname $0`/../; pwd)
cd $DIR
mkdir tmp 2>/dev/null
rm -rf tmp/src 2>/dev/null
D=src/${1}
if [ -d "${D}" ]; then
mkdir -p tmp/${D}
# copy target src directory
rsync -vrlpt --progress ${D} tmp/src --exclude node_modules --exclude test
# copy package.json
cp package.json tmp/${D}
# copy yarn.lock
cp yarn.lock tmp/${D}
cd tmp/${D}
yarn install --production
fi
↓変数の読み込みや引数の処理を行います
# !/bin/bash -eu
if [ $# -lt 1 ]; then
echo 'one argument required. input template name (ex site, employee'
exit
fi
if [ -e ../.env ]; then
source ../.env
fi
CFN_STACK_NAME=${CFN_STACK_PREFIX}-${1}
CFN_TEMPLATE=templates/${1}/template.yml
if [ ! -e ${CFN_TEMPLATE} ]; then
echo 'invalid template name.'
exit
fi
↓変数を記述します
## basic
# aws profile name that you resister through aws-configure command `aws configure --profile PROFILE_NAME`
AWS_PROFILE=
# stack prefix of cloudformation
CFN_STACK_PREFIX=
# s3 bucket name that is used to deploy lambda functions
S3_BUCKET_NAME_FOR_SAM_PACKAGE=
Lambdaの開発に関して
npmが使える
Lambdaパッケージの中にnode_modulesを入れることでLambdaの中でnpmパッケージを使うことができます
今回のデプロイスクリプトではscript/prepare_src.shのyarn install --productionにて
一時ディレクトリにproductionインストールをしています
(複数stackで別々のパッケージを使う場合でも、全てのパッケージがそれぞれに入ってしまいますが今回は許容することとします
必要最小限のパッケージにしたい場合は、stackごとのディレクトリの中にpackage.jsonを入れたほうが良さそうです)
ramda.jsが便利
ramda.jsとは下記の記事で分かりやすく紹介されています
https://tech.recruit-mp.co.jp/front-end/post-16249/
平たく言うと JavaScript 標準 API である map や filter といったコレクション操作系と Object.assign のような値の不変性担保という二つのパラダイムを併せ持ったライブラリです。
Lambdaで扱うデータは入出力共にコレクションとなる事が多く、活用機会が多いです
例えば下記のコードのように、コレクション操作を関数型チックに簡潔に書くことができます
(下記の場合は、入力がLambdaへのeventで出力がDynamoDBへの書き込みです)
'use strict';
const { timeToStr, year } = require('./lib/time_utils');
const { authGoogle } = require('./lib/auth');
const R = require('ramda');
const { put } = require('dynamodb-doc-client-wrapper');
const uniqid = require('uniqid');
function isAllFilled(columns, data) {
const notNil = R.pipe(R.prop(R.__, data), R.isNil, R.not);
return R.all(notNil)(columns);
}
function buildOriginRecord(now, uid, body) {
if (!isAllFilled(['sender_token', 'receiver_email', 'content'], body)) {
throw '400 error, input invalid';
}
return R.pipe(
R.pick(['sender_token', 'receiver_email', 'receiver_name', 'content']),
(d) => R.assoc('receiver_email', R.pipe(R.prop('receiver_email'), R.toLower)(d), d),
R.assoc('create_time', timeToStr(now)),
R.assoc('year', year(now)),
R.assoc('id', uid),
)(body);
}
async function buildAuthRecord(body) {
const userData = await authGoogle(R.prop('sender_token', body));
return R.pipe(
R.dissoc('sender_token'),
R.assoc('sender_email', R.toLower(R.prop('email', userData))),
R.assoc('sender_name', R.prop('name', userData)),
)(body);
}
exports.put = (event, context, callback) => {
Promise.resolve(buildOriginRecord(Date.now(), uniqid(), event))
.then(buildAuthRecord)
.then(i => Promise.all([
put({
TableName: process.env.TABLE_MESSAGES,
Item: i
}),
put({
TableName: process.env.TABLE_UNSENT_MESSAGES,
Item: i
}),
]))
.then(_ => callback(null, { status: '200' }))
.catch(e => {
console.log(e);
callback(e);
})
;
};
ramda.jsのドキュメントは下記ですが、しっかり書いてあって読みやすいです
https://ramdajs.com/docs/
CloudWatch Logsをローテートさせる
CloudWatchのLogGroupの定義がない場合、Lambdaでログが書き出されたときにログが作られるのですがデフォルトでローテートされません
どんどんログが溜まっていってしまうので、ローテートさせる日数を入れるためにLogGroupを定義します
詳しくは下記の記事が分かりやすいです
https://dev.classmethod.jp/cloud/aws/should-create-cloudwatch-logs-log-group-when-creating-lambda-with-aws-sam/
PutMessageFunc:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub ${NameTagPrefix}-PutMessage
Handler: put_message.put
Runtime: nodejs8.10
Policies: AmazonDynamoDBFullAccess
CodeUri: ../../tmp/src/site
Environment:
Variables:
TABLE_MESSAGES: !Ref TableMessages
TABLE_UNSENT_MESSAGES: !Ref TableUnsentMessages
Events:
PostResource:
Type: Api
Properties:
RestApiId: !Ref SiteApi
Path: /messages
Method: post
PutMessageLogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub /aws/lambda/${PutMessageFunc}
RetentionInDays: 14
Lambdaはバッチ処理には向かない
Lambdaには300秒の実行時間制限がありますので、日次処理のようなデータを一度にたくさん処理する使い方には本来向いていません
DynamoDBなどへのアクセスがあると処理時間が伸びてしまいます
基本的には順次処理させるような形にして、仕様上日次処理になってしまうものに関してはSQSやKinesis StreamなどをLambdaの間に挟んで処理を分配するLambdaとDBアクセス処理を行うLambdaを細かく切り分けることになると思います
(今回の用途では大したアクセスにならない前提で全部Lambdaで処理しています)
どれくらいのバッチ処理でどれくらいの時間がかかっていて、設定したLambdaの制限時間に対してどれくらい余裕があるかを把握しておいたほうが良いと思います
DynamoDBの使い方に関して
RDBとは使い方が異なる
DynamoDBの基礎に関しては下記の記事が分かりやすいです
https://qiita.com/hshimo/items/e5ad98b21786d796f1da
基本的にKVSですのでjoinが無く、keyとして指定したカラムをすべて指定してはじめて値が返る等RDBとは異なる使い方になります
今回のケースではそこまで複雑なデータ構造ではないのでDynamoDBで扱えましたが、
要件によってはRDBを使うこともあると思います
(サーバーレスな世界にRDBを持ち込むときはKinesis Streamを使うといいって同僚が言っていました)
Capacity Unitが足りない場合エラーになる
DynamoDBを作る際には、あらかじめCapacity Unitを指定してアクセス可能な頻度を宣言することになります(過剰に超えるとエラーになります)
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/HowItWorks.ProvisionedThroughput.html
https://dev.classmethod.jp/cloud/aws/optimize-costs-of-dynamodb/
DynamoDBがエラーを返す場合に対して、Lambda側で考慮しておく必要があります
(例外処理を出したり、リトライさせたり)
また、特に前述したバッチ処理等の場合では時間あたりの処理量が多くなってしまいますので、Lambda側の設計と共に考慮に入れる必要があります
API Gatewayの記述に関して
概要
CloudformationにてAPI Gatewayを作成するために、APIを表現するための規格であるswagger(OpenAPI)を用います
swaggerは下記の通りAWS公式でサポートされています
※2018年10月現在、swaggerの最新versionはver3系が出ていますが、API Gatewayが対応していないため、古いver2.0を使います
構成ファイルの作成
まずはswagger構成を別のymlファイルとして作成します。
構成ファイルの仕様に関して、公式ドキュメントを御覧ください
- basic
- parameters
構成ファイルの確認
いくつかの方法で正しいsyntaxであるか確認することができます
- swaggerhubにアクセス
- dockerで確認環境をローカルに構築
- エディタのプラグインで確認
awscliの実行前に正しいsyntaxであることを確認しておきましょう
構成ファイルのsamテンプレートへのinclude
https://dev.classmethod.jp/cloud/aws/understanding-aws-serverless-application-model-and-swagger/
上記記事に従い、作成したswagger定義をCloudFormationテンプレートにincludeさせます
aws固有拡張の追加
swaggerによるAPI共通定義だけではApiGatewayを実際に動かすことはできません
aws拡張記法で細かい設定を行う必要があります
困ったら公式リポジトリのサンプルを参考にしましょう
https://github.com/awslabs/serverless-application-model/tree/master/examples/2016-10-31/api_swagger_cors
api gateway integrationの追加
api gatewayからlambdaを起動するためにはintegrationを追加する必要があります
公式ドキュメントに従い、該当部分を追加します
http://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/api-gateway-swagger-extensions-integration.html
cors許可の追加
異なる生成元からのajaxアクセスを受け取るためには、受け取り側のサーバーにてcors設定が必要です
cors設定の構成を手動で構築するのは困難なタスクなので、webコンソールからcors設定を付加し、デプロイしたものをymlに出力します
参考:http://www.bokukoko.info/entry/2017/03/27/191830
https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/how-to-cors.html
https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/enable-cors-for-resource-using-swagger-importer-tool.html
マッピングテンプレートの追加
htmlのformにてpost送信された情報はrequest bodyにquery形式で格納されますが、
lambdaはjsonしか読めないためmappingが必要となります
https://dev.classmethod.jp/cloud/aws/sugano-013-api-gateway/
CloudFrontの記述に関して
通過させるHeaderを明示的に指定する
HTTPS接続でCloudFrontから別ドメイン(今回はAPI Gateway)にアクセスさせる場合
通過させるHeaderを適当にAllとしてしまいがちですが、Hostヘッダーを通してはいけないという罠があります
https://qiita.com/kaojiri/items/4e2d2f112acfca14970e
API GatewayにAPI Keyを要求させる
今回作ったのは社内限定のシステムなのでWAFを紐づけたCloudFrontでIP制限をかけているのですが
API Gatewayに直でアクセスするとアクセスできてしまうので、API Keyを要求させるようにします
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/aws-resource-apigateway-apikey.html
CloudFrontにはCustomHeaderという仕組みがあり、指定したHeaderに特定の値を挿入して転送先にアクセスさせることができます
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-cloudfront-distribution-origincustomheader.html
これでCloudFormationからAPI Keyの作成と、CloudFrontへの紐付けができると思いきや、
CloudFormationからはAPI Keyのkey要素が取り出せないために紐付けができません
いい回避策がないかサポートに問い合わせたのですがawscliをAPI Gatewayを作成した後と
CloudFrontを作成する前の間に実行させることで取得するほかないとの答えが帰ってきました
(このような都合があるため、CloudFront用のstackは切り分けてあります)
(stackoverflowでも同じような質問があって、AWSの中の人っぽい人が今は回避策しかないけどいずれなんとかしたいみたいなことを言っていました)
下記のようなシェルスクリプトをstack作成の間に挟むことになりそうです
id=`aws cloudformation list-exports --profile ${AWS_PROFILE} | jq -r '.Exports | map(select(.Name == "YOUR_STACK_PREFIX-SiteApiKeyId"))[] | .Value'`
key=`aws apigateway get-api-key --api-key ${id} --include-value --profile ${AWS_PROFILE} | jq -r '.value'`
こちらで取得したAPI Keyをdeployコマンドの--parameter-overridesとして渡すことでCloudFrontにAPI Keyを紐付けることができます
ただCloudFormationの権限があれば、stackの変数を見ることでAPI Keyを見れてしまうので注意してください
権限管理をきちんとするならKMSを使うのではないかと思います
参考にしたその他のリンク
CloudFormation
(2017年12月時点) 私的 CloudFormation ベストプラクティス - https://qiita.com/yasuhiroki/items/8463eed1c78123313a6f
aws-sam-localだって!?これは試さざるを得ない! - https://qiita.com/Mic-U/items/0e631029ae4ef41c0f3f
SES
ses-template-mailer - npm - https://www.npmjs.com/package/ses-template-mailer
JavaScriptのテンプレートエンジンHandlebars入門 - Qiita - https://qiita.com/sassy_watson/items/f9947624876bf75a9eff
まとめ
AWS SAMによってサーバーレスアプリケーションを実装してみました
CloudFormationによるInfrastructure as Codeにより、構成の再現性を得ることができ、
将来的に設定を忘れる等の運用上の問題を防いだり、構成の再利用によって開発が捗ったりする恩恵が得られます
またAWSのサービスに乗っかることの利点として、ドキュメントがしっかりしている、サポートが得られる、web上に記事が多いなどのメリットがあり、開発が捗りそうです
さらにec2を常時立てるより費用が抑えられることが見込め、お財布にも優しいです
一方でCloudFormationも万能でなく、機能が届かない部分があったり、単純にwebUIから操作するより時間がかかってしまうなど便利な半面、大変な部分もありました
コンテナ技術も使いやすくなっており、システムをコンテナで自前で作ってしまう選択肢も取りやすくなっていると思います
利点と欠点を理解した上でサーバーレスアプリケーションを実用していければと思います