はじめに
LINEのトーク履歴からチャットボットを作成する方法を誰でもできるようになるべく丁寧に解説します。
マルコフ連鎖の詳細な解説は本記事では行わないため別の参考書等をご参照ください。
実装
以下ではコードの解説を行っていきます。GitHubのレポジトリも載せておくので併せてご活用ください。
LINEのトーク履歴の抽出
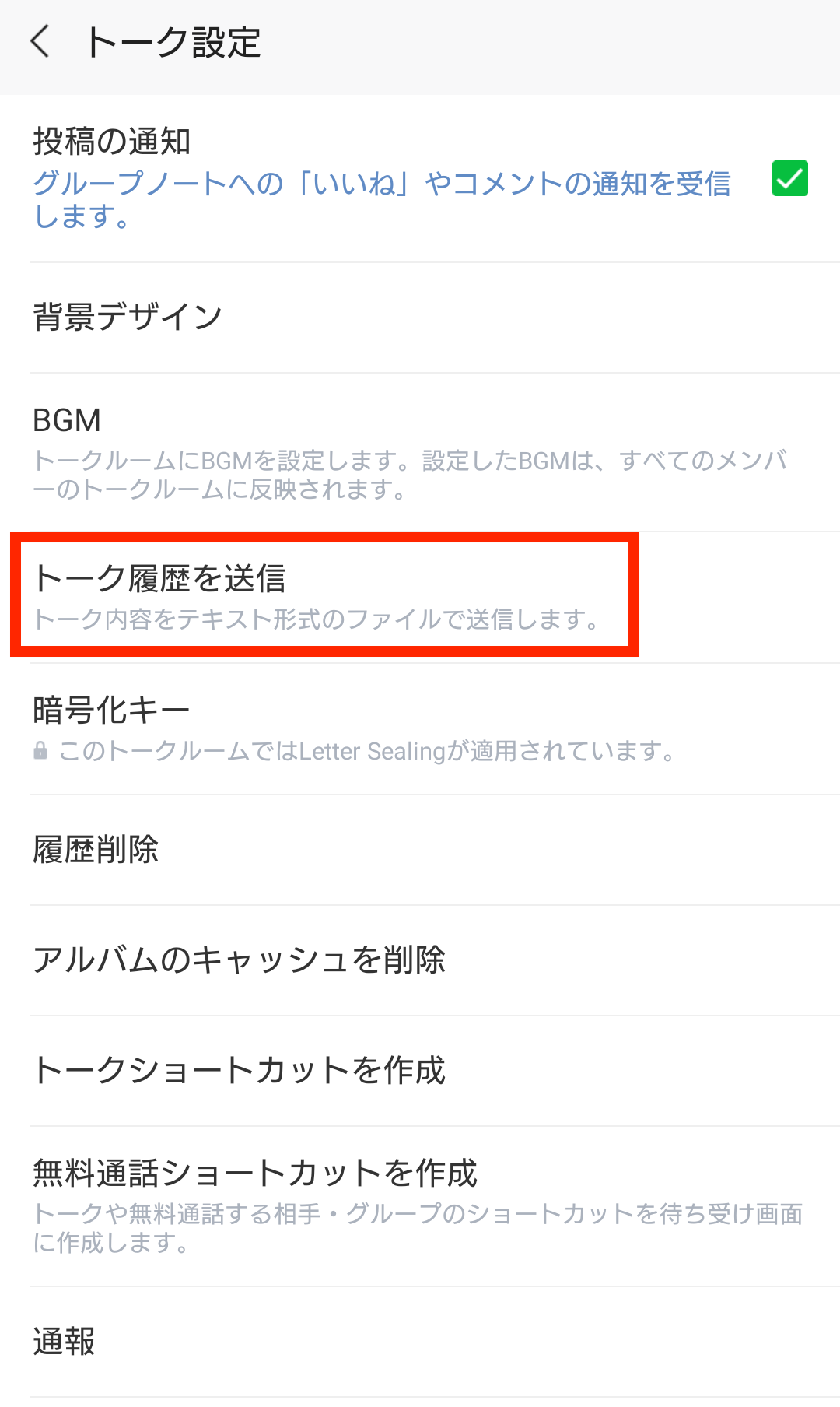
まずはトーク履歴を入手しましょう。トーク画面の右上の矢印をタップし出てきた設定を押してください。(下図参照)

次に,トーク履歴の送信(下図参照)を押します。トーク履歴がテキストファイル.txtでエクスポートされるので適当な場所に保存してください。自分は軽量なファイルはだいたいgmailの下書きに一時保存してPCからダウンロードしています。入手したデータはraw_data.txtとしてdataディレクトリ内に置いておいてください。
データ整形
入手したデータを見てみると以下のような形式になっていると思います。
[LINE] huga子とのトーク履歴
保存日時:2020/2/14 15:15
2018/4/6(金)
22:45 hoge男 こんばんは!今日はありがとうございました!
22:58 huga子 こちらこそありがとうございました😊
2018/4/7(土)
00:40 hoge男 またよろしくお願いします!
名前や日付など無駄な文章が入ってしまっていますね。まずはこれを取り除きましょう。以下の作業はGoogle Colaboratory上またはJupyter Notebook上で行うと行いやすいと思います。コードの全文はGitHub上のdata_shaping.ipynbをご参照ください。
使用する外部ライブラリは,neologdn (文章の表現を正規化するライブラリ) とemoji (絵文字を除去するライブラリ) です。以下のコマンドでインストールできますが,使わなくてもまともな出力になるようなので面倒な方は使わなくても大丈夫です。
pip install neologdnpip install emoji
import neologdn
import emoji
for i, line in enumerate(lines):
# 西暦の行を削除
if ('2018' in line) or ('2019' in line) or ('2020' in line):
line = ''
# 会話でないものを削除
elif ('[スタンプ]' in line) or ('[ファイル]' in line) or ('[写真]' in line) or ('[動画]' in line) or ('アルバム' in line) or ('ノートに' in line) or ('通話' in line) or ('http' in line):
line = ''
# 時刻を削除
if len(line) >= 4:
if line[1] == ':':
line = line[4:]
elif line[2] == ':':
line = line[5:]
# 表現を正規化
line = neologdn.normalize(line)
# 絵文字を除去
line = ''.join(['' if c in emoji.UNICODE_EMOJI else c for c in line])
# リストから空の文字列を削除
lines = list(filter(lambda a: a != '', lines))
次に発言を自分のものと相手のものに分けます。hoge男とhuge子は自分と相手の名前に変えてください。
# どちらの発言かを判定しリストに格納
my_name='hoge男'
partner_name='huge子'
my_remarks=[]
partner_remarks=[]
for line in lines:
if line[0:3]==my_name[0:3]:
speaker=my_name
my_remarks.append(line.replace(my_name,''))
elif line[0:3]==partner_name[0:3]:
speaker=partner_name
partner_remarks.append(line.replace(partner_name,''))
else:
if speaker==my_name:
my_remarks.append(line.replace(my_name,''))
else:
partner_remarks.append(line.replace(partner_name,''))
最後に発言をtxtファイルに書き込みます。
my_remarks_file_path = './../data/my_remarks.txt'
partner_remarks_file_path = './../data/pa_remarks.txt'
# 自分の発言をtxtファイルに書き込み
with open(my_remarks_file_path, mode='w') as f:
f.write('\n'.join(my_remarks))
# 相手の発言をファイルに書き込み
with open(partner_remarks_file_path, mode='w') as f:
f.write('\n'.join(partner_remarks))
以上でデータの整形は終わりです。お疲れ様でした。あと少しです。
マルコフ連鎖
いよいよ用意したデータを用いて文章を自動生成します。
使用する外部ライブラリはmarkovify (マルコフ連鎖用ライブラリ) とMeCab (分かち書き用ライブラリ) です。以下のコマンドでインストールできます。今回は必ずインストールしてください。
pip install mecab-python3pip install markovify
import markovify
import MeCab
my_remarks_file_path = './../data/my_remarks.txt'
partner_remarks_file_path = './../data/partner_remarks.txt'
with open(my_remarks_file_path) as f:
text = f.read()
parsed_text = MeCab.Tagger('-Owakati').parse(text)
text_model = markovify.Text(parsed_text, state_size=3)
for _ in range(10):
sentence = text_model.make_short_sentence(100, 20, tries=20).replace(' ', '')
print(sentence)
以下に自分が試した際の出力例を示します。一応文章っぽくなっていますね。
そんなことないんですよね...
ほぼ週1だと思う?って思ったけど昨日の夕飯焼き肉だった...
これからどうなるんだろう嫌とかでは.......?
エラー(むしろ本題)
実は自分の発言データでは正常に学習できたのですが,相手の発言データを使うと以下のエラーが出てしまっています......使用できない文字が含まれているのかと思い色々と試したのですが一向に解決しません.......
どなたか原因が分かる方がいらっしゃれば教えていただければと思います。
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-6-776ef0b0de18> in <module>()
10
11 parsed_text = MeCab.Tagger('-Owakati').parse(text)
---> 12 text_model = markovify.Text(parsed_text, state_size=3)
13
/usr/local/lib/python3.6/dist-packages/markovify/text.py in __init__(self, input_text, state_size, chain, parsed_sentences, retain_original, well_formed, reject_reg)
48 # Rejoined text lets us assess the novelty of generated sentences
49 self.rejoined_text = self.sentence_join(map(self.word_join, self.parsed_sentences))
---> 50 self.chain = chain or Chain(self.parsed_sentences, state_size)
51 else:
52 if not chain:
/usr/local/lib/python3.6/dist-packages/markovify/chain.py in __init__(self, corpus, state_size, model)
51 self.compiled = (len(self.model) > 0) and (type(self.model[tuple([BEGIN]*state_size)]) == list)
52 if not self.compiled:
---> 53 self.precompute_begin_state()
54
55 def compile(self, inplace = False):
/usr/local/lib/python3.6/dist-packages/markovify/chain.py in precompute_begin_state(self)
97 begin_state = tuple([ BEGIN ] * self.state_size)
---> 98 choices, cumdist = compile_next(self.model[begin_state])
99 self.begin_cumdist = cumdist
100 self.begin_choices = choices
KeyError: ('___BEGIN__', '___BEGIN__', '___BEGIN__')
おわりに
読んで頂きありがとうございました。
次はLSTM等を用いた対話型チャットボットを作成したいと考えていますが,自前の1対1の対話型のデータセットを作成するのは大変そうですね...自然言語処理は素人なので何か良いアイデアがあったら教えていただけたらと思います。