Text2ImageというAI領域
テキストを与えると、その文(章)の内容を描写した画像や、文(章)の内容から連想される画像を描いてくれるAIは、__Text2Image__と呼ばれています。
この領域では、__OpenAIのDALL-E__が有名です。
DALLE-E以外にも、調べてみると、数多くのアルゴリズムに立脚した多くのモデルの実装コードやツールが公開されています。今回は、__Open-daze Imagine__を取り上げます。
インストールと実行方法については、先行する次の記事をご参照ください。
( 前回の記事 )
Deep-daze Imagineについて
今回、__Text2Imageを行うアルゴリズムの1つであるDeep-daze Imazine__の__学習済みモデル__に__24件の英文を与えた__とき、__どのような画像が描かれるのかを観察して、得られた結果に対する考察__を行いました。
結果を先取りすると、検証を経て、__概ね次の考察__を得ました。
( 結果の概要 )
- __アニメ(comic)調の画風__という英文指示は理解できるが、__写真(photo)調__と__スケッチ調__という指示は理解できなかった。
- 分詞構文__やthat節__を含む複雑な英文に書かれた意味を、おおむね理解できる。
- レディー・ガガやマイケル・ジャクソン、ブレア(英国)首相の__人名を理解__し、似た人物の顔スケッチを描画できる。
- サンフランシスコやニュー・ヨーク、凱旋門、エッフェル塔など、地名や広く知られた建造物は、認識できなかった。
- 人物の体や顔が、完全に描かれず、下半身のみや、__顔の一部が欠落__したり、__他のオブジェクトとつながった不正確な描画__が散見される。
- Never Never Never Give upやBright Future shall comeなど、__抽象的な英文の内容を、イメージとして捉えて画像に反映させる描画を行う能力__を持つ。
- 画面の左側と右側に異なる情景や事物を描け、という英文による指示を正しく理解することができる。
なお、検証を行うに際しては、__Imagine__が採用しているアルゴリズムと、そのアルゴリズムに学ばせた学習用データの双方について、深く知る必要があります。
アルゴリズムと学習用データ
学習データについては公的に述べられた記述がなく、またアルゴリズムについても、論文やスライド、ノートといった類の資料の公開がなく、公式サイトに次の記載があるのみです。
-
Deep Daze Imagine__は。clipとSiren__の2つを組み合わせたものである。
-
clip : OpenAIから公開されたツール。引数で渡した画像が、str型のテキストで渡した複数の単語のうち、どの単語に一番近いかのスコア値を返してくれる。Open AIから出た論文Learning Transferable Visual Models From Natural Language Supervisionで提案された。
-
Siren : 画像や動画、音声などのsignal dataの特徴を捉える精度に優れたニューラル・ネットワークモデル。スタンフォード大学から出たImplicit Neural Representations with Periodic Activation Functionsという表題の論文が初出。
__Sirenは、deep_daze.py__の__10行目__でimportされている。
from siren_pytorch import SirenNet, SirenWrapper
clip__は、deep_daze.py__の__23行目__でimportされている。
from .clip import load, tokenize
論文と実装コードは次の通りです。
幸い、ソースコードの全文はGitHubで公開されているため、コードリーディングを行うことで、アルゴリズムの内実を窺い知ることができます。この作業は、別の機会に譲りたいと思います。
( 実行されるのは、以下の部分 )
class Imagine(nn.Module):
def __init__(
self,
*,
text=None,
img=None,
clip_encoding=None,
lr=1e-5,
batch_size=4,
gradient_accumulate_every=4,
save_every=100,
image_width=512,
num_layers=16,
epochs=20,
iterations=1050,
save_progress=True,
seed=None,
open_folder=True,
save_date_time=False,
start_image_path=None,
start_image_train_iters=10,
start_image_lr=3e-4,
theta_initial=None,
theta_hidden=None,
model_name="ViT-B/32",
lower_bound_cutout=0.1, # should be smaller than 0.8
upper_bound_cutout=1.0,
saturate_bound=False,
averaging_weight=0.3,
create_story=False,
story_start_words=5,
story_words_per_epoch=5,
story_separator=None,
gauss_sampling=False,
gauss_mean=0.6,
gauss_std=0.2,
do_cutout=True,
center_bias=False,
center_focus=2,
optimizer="AdamP",
jit=True,
hidden_size=256,
save_gif=False,
save_video=False,
):
推論に要した時間
以下の条件で、一つの英文を画像に変換するのに2〜3時間かかりました。
- レイヤー数: 32層 (高解像度設定)
- エポック数: 20
- イテレーション数: 1050
- Google Colab+ (定額月額 5,243円)
- GPU: Tesla-NVIDIA V100
- Python ver.: 3.7.11
4. 高度な使用例
真の深層学習の方法では、層が多いほど良い結果が得られます。 デフォルトは16ですが、リソースに応じて32に増やすことができます。
$ imagine "stranger in strange lands" --num-layers 32
実行例 (Colab+ Jupyter notebook)
( 入力 )
!imagine "A photo of French restaurant on the left, a hand-written sketch of the same restaurant on the right and a photo of a British gentle man at the bottom" -num-layers 32
( 実行中の出力画面 )
Setting jit to False because torch version is not 1.7.1.
Starting up...
Imagining "Draw_a_French_restaurant_on_the_left._Draw_a_Japanese_restaurant_on_the_right" from the depths of my weights...
Warning: unknown mime-type for "./" -- using "application/octet-stream"
Error: no "view" mailcap rules found for type "application/octet-stream"
/usr/bin/xdg-open: 851: /usr/bin/xdg-open: www-browser: not found
/usr/bin/xdg-open: 851: /usr/bin/xdg-open: links2: not found
/usr/bin/xdg-open: 851: /usr/bin/xdg-open: elinks: not found
/usr/bin/xdg-open: 851: /usr/bin/xdg-open: links: not found
/usr/bin/xdg-open: 851: /usr/bin/xdg-open: lynx: not found
/usr/bin/xdg-open: 851: /usr/bin/xdg-open: w3m: not found
xdg-open: no method available for opening './'
epochs: 0% 0/20 [00:00<?, ?it/s]
image updated at "./Draw_a_French_restaurant_on_the_left._Draw_a_Japanese_restaurant_on_the_right.jpg"
epochs: 0% 0/20 [00:00<?, ?it/s]
iteration: 0% 0/1050 [00:00<?, ?it/s]
loss: -21.45: 0% 0/1050 [00:00<?, ?it/s]
loss: -21.45: 0% 1/1050 [00:00<11:39, 1.50it/s]
loss: -21.54: 0% 1/1050 [00:01<11:39, 1.50it/s]
loss: -21.54: 0% 2/1050 [00:01<10:58, 1.59it/s]
loss: -21.67: 0% 2/1050 [00:01<10:58, 1.59it/s]
loss: -21.67: 0% 3/1050 [00:01<10:43, 1.63it/s]
loss: -21.54: 0% 3/1050 [00:02<10:43, 1.63it/s]
loss: -21.54: 0% 4/1050 [00:02<10:36, 1.64it/s]
loss: -21.54: 0% 4/1050 [00:03<10:36, 1.64it/s]
loss: -21.54: 0% 5/1050 [00:03<10:41, 1.63it/s]
loss: -22.53: 0% 5/1050 [00:03<10:41, 1.63it/s]
loss: -22.53: 1% 6/1050 [00:03<10:44, 1.62it/s]
loss: -22.82: 1% 6/1050 [00:04<10:44, 1.62it/s]
loss: -22.82: 1% 7/1050 [00:04<10:44, 1.62it/s]
loss: -23.34: 1% 7/1050 [00:04<10:44, 1.62it/s]
loss: -23.34: 1% 8/1050 [00:04<10:44, 1.62it/s]
loss: -24.19: 1% 8/1050 [00:05<10:44, 1.62it/s]
( 省略 )
loss: -52.54: 100% 1046/1050 [10:51<00:02, 1.61it/s]
loss: -52.54: 100% 1047/1050 [10:51<00:01, 1.61it/s]
loss: -53.17: 100% 1047/1050 [10:52<00:01, 1.61it/s]
loss: -53.17: 100% 1048/1050 [10:52<00:01, 1.61it/s]
loss: -54.56: 100% 1048/1050 [10:53<00:01, 1.61it/s]
loss: -54.56: 100% 1049/1050 [10:53<00:00, 1.61it/s]
loss: -55.81: 100% 1049/1050 [10:53<00:00, 1.61it/s]
loss: -55.81: 100% 1050/1050 [10:53<00:00, 1.61it/s]
epochs: 100% 20/20 [3:37:57<00:00, 653.88s/it]
image updated at "./A_photo_of_French_restaurant_on_the_left,_a_hand-written_sketch_of_the_same_r.000209.jpg"
【 動作検証 】
今回、__Text2Imageを行うアルゴリズムの1つであるDeep-daze Imazine__の__学習済みモデル__に__24件の英文を与えた__とき、__どのような画像が描かれるのかを観察して、得られた結果に対する考察__を行いました。
結果をまとめた表は次の通りです。
なお、3列目の「英文の出典」に記載のない入力文は。今回、この記事の筆者が作成した文です。
【 考察 】
- 例文 I have a dream that my four little children will one day live in a nation where they will not be judged by the color of their skin but by the content of their character から生成された画像をみると、__that節__のなかの__4人の子供__の顔だけでなく、__主節の主語 *"I"*の人物の顔__も、しっかりと書き込まれているのが秀逸です。
- Never never never give upの例では、卓球をしたり(左下)、何かの運動競技や作業(上段中央)をしたりと、人物が何かに夢中になって取り組んでいる様子が見て取れます。ハードな身体作業に従事しているけど、決して諦めないぞ、といった情景が描かれているのかもしれません。
- *It is a mistake to look too far ahead・・・"*では、人生の中で起きる出来事の連鎖(chain of destiny)、__「運命の糸(鎖)」__というくだリが、__抽象的な「鎖」ではなく、具体的な「鎖」として解釈__されています。
- Photo ofと指示を与えても、実写写真のテイスト感のある絵は得られなたった(残念)。
| No. | 出力画像 | 入力した英文 | 備考 |
|---|---|---|---|
| 1 |  |
The U.S President walking in the garden of the White House with his wife | |
| 2 |  |
A naked Italian beautiful girl without clothes standing in fromt of the hotel | |
| 3 |  |
I have a dream that my four little children will one day live in a nation where they will not be judged by the color of their skin but by the content of their character | キング牧師の有名な演説 |
| 4 |  |
Inspire the next | 日立のスローガン |
| 5 |  |
Never never never give up | 英首相チャーチルの言葉 |
| 6 |  |
It is a mistake to look too far ahead. Only one link of the chain of destiny can be handled at a time | 英首相チャーチルの言葉 |
| 7 |  |
The price of greatness is responsibility | 英首相チャーチルの言葉 |
| 8 |  |
The bright future shall come to the 21st Century | |
| 9 |  |
Draw a French restaurant on the left. Draw a Japanese restaurant on the right | |
| 10 |  |
A photo of French restaurant on the left, a hand-written sketch of the same restaurant on the right and a photo of a British gentle man at the bottom | |
| 11 |  |
a photo of a British gentle man | |
| 12 |  |
a sketch of a British gentle man | |
| 13 |  |
Having forgotten to bring my wallet, I had to go back to home to get it | |
| 14 |  |
Every spirit builds itself a house; and beyond its house, a world; and beyond its world a heaven. Know then, that the world exists for you: build, therefore, your own world | エマソンの言葉 |
| 15 |  |
Stay hungry, stay foolish | スティーブ・ジョブズの言葉 |
| 16 |  |
I don't know whether or not you want to work for the company or not |
地名や著名人の固有名詞の認識力(学習済みか検証)
| No. | 出力画像 | 入力した英文 | 備考 |
|---|---|---|---|
| 17 |  |
"U.K. Prime mInister Tony Blair and U.S. President George W.Bush shake hands in front of the UK Parliament" |
- 顔がブッシュJr.元大統領っぽい

- 髪型や顔の形が、ブレア元首相の面影を感じさせる

- 最終的に出力された画像は209回目の生成結果。これより前の50回目の画像がこれ。この時点の顔は、ブレア首相のそれにずっっと近かった。
( 実物の画像 )
- 以下、米ブッシュ(元)大統領も英ブレア(元)首相も、いずれも現職在任当時の画像
| No. | 実際の画像1 | 実際の画像2 | 実際の画像3 |
|---|---|---|---|
| 18 |  |
 |
 |
今度は、レディ・ガガとマイケル・ジャクソンで検証してみます。また、英国国会議事堂という場所が認識されるかも併せて確認します。(Parliament: 英国国会議事堂)
| No. | 出力画像 | 入力した英文 | 備考 |
|---|---|---|---|
| 19 |  |
Michael Jackson and Lady Gaga are dancing at the building of SONY Music Inc. located at New York city |
- レディガガ(左)とマイケルジャクソン(右)に見えなくもない

今度は、広く知られた地名と建物物が学習済みか、検証してみます。
| No. | 出力画像 | 入力した英文 | 備考 |
|---|---|---|---|
| 20 |  |
The Eiffel Tower on the left side and the triumphal arch on the right side | |
| 21 |  |
A Photo of the Golden Gate Bridge at San Francisco in winter |
下書きの画像を指定する
Imagineモデルに画像を描画させる上で、初期値となる画像を指定することができます。
6. Priming
Mario Klingemannによって最初に考案され共有された手法であり、テキストに向けて操作される前に、開始画像でジェネレーターネットワークをプライミングすることができます。
使用する画像へのパスと、オプションで初期学習ステップの数を指定するだけです。
$ imagine 'a clear night sky filled with stars' --start-image-path ./cloudy-night-sky.jpg
初期値に指定した画像

Current directory
渡した画像を初期値として、処理が開始される
!imagine "a photo of a British gentle man" --start-image-path ./british_man_1.jpg
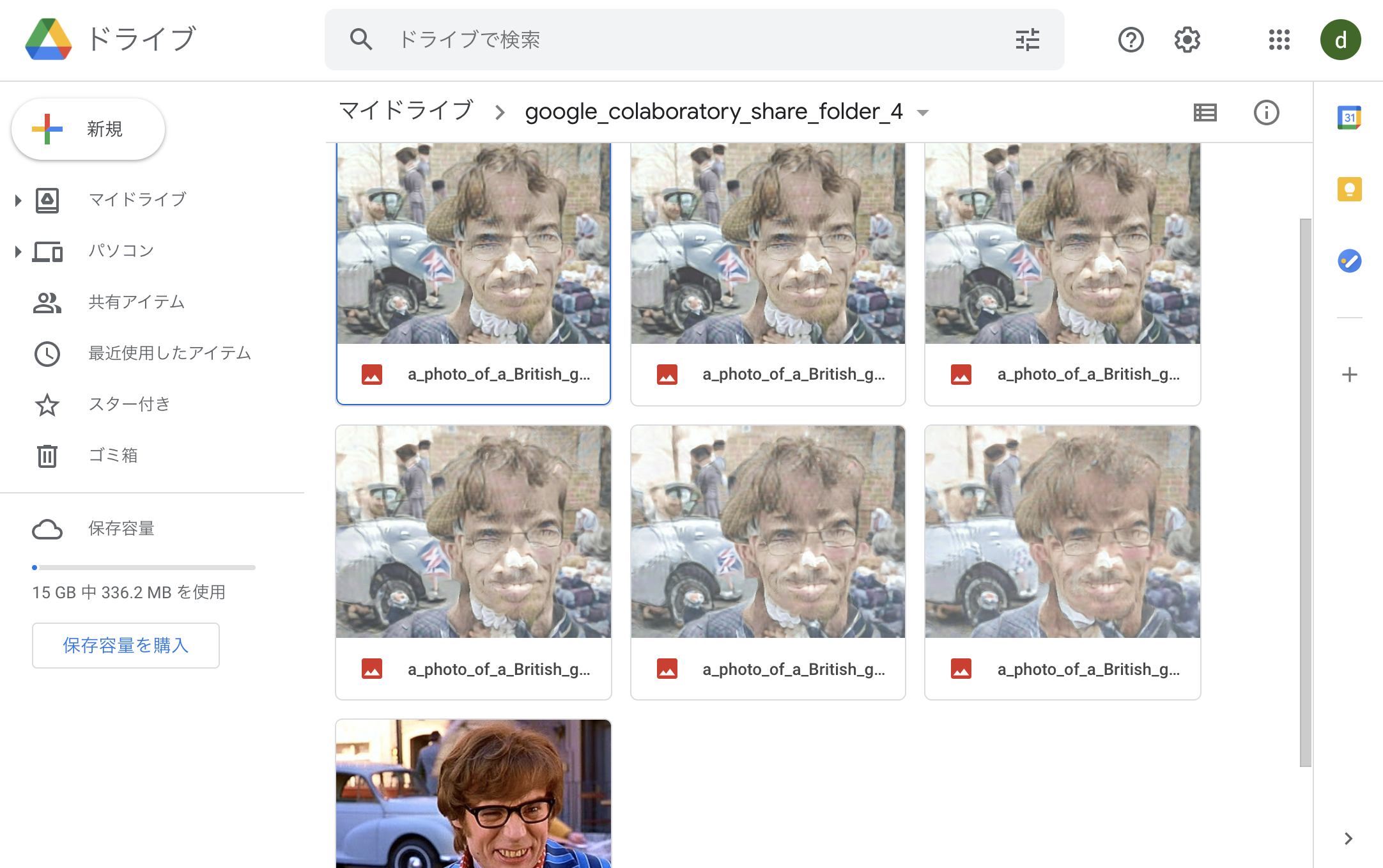
出力された画像

| No. | 出力画像 | 入力した英文 | 備考 |
|---|---|---|---|
| 22 | |
a photo of a British gentle man |
同じ画像を下敷きにして、もう1つ他の文を与えてみます。
先ほどは、下敷きとなる画像と、与えた文の内容が同じでした。次は、__与えられた人物の画像にはない、「赤い壊れたメガネ」と「風にたなびく髪」__という要素を__文で与えて__みます。
!imagine "a photo of a British gentle man with his hair blowing in the wind. and with his red glasses broken" --start-image-path ./british_man_1.jpg
出力された画像
- 髪が風にたなびいていて、という分詞構文のくだりが汲み取られて、表現されていない
- 赤い壊れたメガネ、という分詞構文の下りが、十分に表現されていない。画像を見ると、メガネは壊れていない。さらに、赤いのはメガネであるべきところ、別の部分が赤く塗られている。

| No. | 出力画像 | 入力した英文 | 備考 |
|---|---|---|---|
| 23 | |
a photo of a British gentle man |
次は、文の中でさらに、__「アニメーションのイラストのような筆致」__という注文を投げてみます。
!imagine "draw pictures like in comics a British gentle man with his hair blowing in the wind. and with his red glasses broken" --start-image-path ./british_man_1.jpg
出力された画像
- 髪はたなびいている
- メガネが壊れていない
- 赤いのはメガネであるべきところ、別の部分が赤く塗られている。

| No. | 出力画像 | 入力した英文 | 備考 |
|---|---|---|---|
| 24 | |
draw pictures like in comics a British gentle man with his hair blowing in the wind. and with his red glasses broken |