Text2ImageというAI領域
テキストを与えると、その文(章)の内容を描写した画像や、文(章)の内容から連想される画像を描いてくれるAIは、__Text2Image__と呼ばれています。
この領域では、__OpenAIのDALL-E__が有名です。
DALLE-E以外にも、調べてみると、数多くのアルゴリズムに立脚した多くのモデルの実装コードやツールが公開されています。今回は、__Big sleep dream__を取り上げます。
( 解説サイト )
インストールと推論工程の実行方法
- 以下は、英文 "a pyramid made of ice"の連装画像を生成する場合
$ pip install big-sleep
$ dream "a pyramid made of ice"
Big sleep dreamについて
今回、__Text2Imageを行うアルゴリズムの1つであるBig sleep dream__の__学習済みモデル__に__24件の英文を与えた__とき、__どのような画像が描かれるのかを観察して、得られた結果に対する考察__を行いました。
結果を先取りすると、検証を経て、__概ね次の考察__を得ました。
( 結果の概要 )
- 写真のような写実的な画像が出力される。
- 人物を指定した場合は、写真のような綺麗な絵が生成される。
- 抽象的な概念や箴言・格言を入れると、なぜか鳥や昆虫の画像が描画されてしまう(学習データの偏り?)
- sketch調で描け、と文で指定すると、ちゃんとそれらしいテイストの絵が描かれる。
- __マイケル・ジャクソン__と__レディ・ガガ__という__著名人__の名前を与えると、それらしい人物が描画された。
- __アメリカの金門橋(ゴールデン・ブリッジ)__と__フランスのエッフェル塔__は、それらしく描かれた。しかし、フランスの凱旋門は無視されて描かれなかった。
アルゴリズムと学習用データ
学習データについては公的に述べられた記述がなく、またアルゴリズムについても、論文やスライド、ノートといった類の資料の公開がなく、公式サイトに次の記載があるのみです。
- __Big sleep dreamは、clipとBigGAN__の2つを組み合わせたものである。
Ryan Murdock has done it again, combining OpenAI's CLIP and the generator from a BigGAN! This repository wraps up his work so it is easily accessible to anyone who owns a GPU.
-
clip : OpenAIから公開されたツール。引数で渡した画像が、str型のテキストで渡した複数の単語のうち、どの単語に一番近いかのスコア値を返してくれる。Open AIから出た論文Learning Transferable Visual Models From Natural Language Supervisionで提案された。
-
BigGAN : (記載)
論文と実装コードは次の通りです。
幸い、ソースコードの全文はGitHubで公開されているため、コードリーディングを行うことで、アルゴリズムの内実を窺い知ることができます。この作業は、別の機会に譲りたいと思います。
推論に要した時間
以下の条件で、一つの英文を画像に変換するのに2〜3時間かかりました。
- エポック数: 20
- イテレーション数: 1050
- Google Colab+ (定額月額 5,243円)
- GPU: Tesla-NVIDIA V100
- Python ver.: 3.7.11
なお、与えた英文1件に対して、210個の画像ファイルが順次、カレント・ディレクトリに生成されます。時間が経ってから出力される画像が、より高精細な画像ファイルになります。
実行例 (Colab+ Jupyter notebook)
( 入力 )
!dream "The U.S President walking in the garden of the White House with his wife" --save-progress --save-every 100 --save-best
オプションとして、--save-bestを指定すると、以下に説明がある通り、出力される画像を毎回、__clip__でスコア評価を行い、最も良いスコアが与えられた画像ファイルが選択されます。
Due to the class conditioned nature of the GAN, Big Sleep often steers off the manifold into noise. You can use a flag to save the best high scoring image (per CLIP critic) to {filepath}.best.png in your folder.
$ dream "a room with a view of the ocean" --save-best
( 実行中の出力画面 )
- 210枚の画像が生成されて、カレント・ディレクトリに画像ファイルが保存されます。
Starting up... v0.8.5
setting seed of 0
Imagining "The_U.S_President_walking_in_the_garden_of_the_White_House_with_his_wife" ...
/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
Warning: unknown mime-type for "./" -- using "application/octet-stream"
Error: no "view" mailcap rules found for type "application/octet-stream"
/usr/bin/xdg-open: 851: /usr/bin/xdg-open: www-browser: not found
/usr/bin/xdg-open: 851: /usr/bin/xdg-open: links2: not found
/usr/bin/xdg-open: 851: /usr/bin/xdg-open: elinks: not found
/usr/bin/xdg-open: 851: /usr/bin/xdg-open: links: not found
/usr/bin/xdg-open: 851: /usr/bin/xdg-open: lynx: not found
/usr/bin/xdg-open: 851: /usr/bin/xdg-open: w3m: not found
xdg-open: no method available for opening './'
epochs: 0% 0/20 [00:00<?, ?it/s]
iteration: 0% 0/1050 [00:00<?, ?it/s]
loss: -6.49: 0% 0/1050 [00:00<?, ?it/s]
loss: -6.49: 0% 1/1050 [00:00<03:56, 4.43it/s]
loss: -7.64: 0% 1/1050 [00:00<03:56, 4.43it/s]
loss: -7.64: 0% 2/1050 [00:00<03:49, 4.57it/s]
loss: -8.33: 0% 2/1050 [00:00<03:49, 4.57it/s]
loss: -8.33: 0% 3/1050 [00:00<03:42, 4.70it/s]
loss: -11.97: 0% 3/1050 [00:00<03:42, 4.70it/s]
loss: -11.97: 0% 4/1050 [00:00<03:39, 4.77it/s]
( 省略 )
loss: -49.28: 100% 1046/1050 [03:38<00:00, 4.84it/s]
loss: -49.03: 100% 1046/1050 [03:38<00:00, 4.84it/s]
loss: -49.03: 100% 1047/1050 [03:38<00:00, 4.85it/s]
loss: -48.44: 100% 1047/1050 [03:38<00:00, 4.85it/s]
loss: -48.44: 100% 1048/1050 [03:38<00:00, 4.86it/s]
loss: -49.37: 100% 1048/1050 [03:39<00:00, 4.86it/s]
loss: -49.37: 100% 1049/1050 [03:39<00:00, 4.85it/s]
loss: -49.21: 100% 1049/1050 [03:39<00:00, 4.85it/s]
loss: -49.21: 100% 1050/1050 [03:39<00:00, 4.79it/s]
epochs: 100% 20/20 [1:13:17<00:00, 219.90s/it]
image update: 95% 200/210.0 [1:13:17<03:39, 21.99s/it]
【 動作検証 】
今回、__Text2Imageを行うアルゴリズムの1つであるDeep-daze Imazine__の__学習済みモデル__に__24件の英文を与えた__とき、__どのような画像が描かれるのかを観察して、得られた結果に対する考察__を行いました。
結果をまとめた表は次の通りです。
なお、3列目の「英文の出典」に記載のない入力文は。今回、この記事の筆者が作成した文です。
| No. | 出力画像 | 入力した英文 | 備考 |
|---|---|---|---|
| 1 |  |
The U.S President walking in the garden of the White House with his wife | |
| 2 |  |
A naked Italian beautiful girl without clothes standing in fromt of the hotel | |
| 3 |  |
I have a dream that my four little children will one day live in a nation where they will not be judged by the color of their skin but by the content of their character | キング牧師の有名な演説 |
| 4 |  |
Inspire the next | 日立のスローガン |
| 5 |  |
Never never never give up | 英首相チャーチルの言葉 |
| 6 |  |
It is a mistake to look too far ahead. Only one link of the chain of destiny can be handled at a time | 英首相チャーチルの言葉 |
| 7 |  |
The price of greatness is responsibility | 英首相チャーチルの言葉 |
| 8 |  |
The bright future shall come to the 21st Century | |
| 9 |  |
Draw a French restaurant on the left. Draw a Japanese restaurant on the right | |
| 10 |  |
A photo of French restaurant on the left, a hand-written sketch of the same restaurant on the right and a photo of a British gentle man at the bottom | |
| 11 |  |
a photo of a British gentle man | |
| 12 |  |
a sketch of a British gentle man | |
| 13 |  |
Having forgotten to bring my wallet, I had to go back to home to get it | |
| 14 |  |
Every spirit builds itself a house; and beyond its house, a world; and beyond its world a heaven. Know then, that the world exists for you: build, therefore, your own world | エマソンの言葉 |
| 15 | 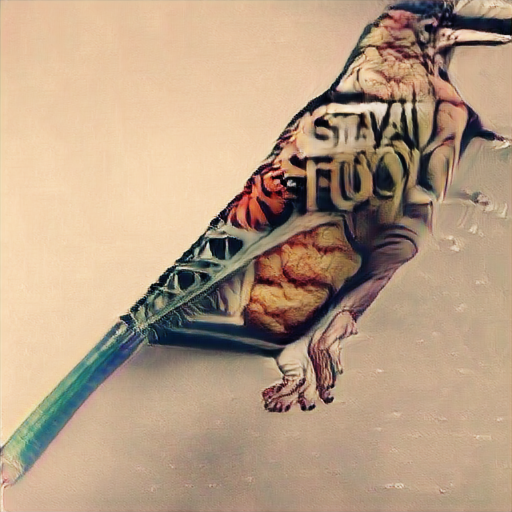 |
Stay hungry, stay foolish | スティーブ・ジョブズの言葉 |
| 16 |  |
I don't know whether or not you want to work for the company or not |
地名や著名人の固有名詞の認識力(学習済みか検証)
| No. | 出力画像 | 入力した英文 | 備考 |
|---|---|---|---|
| 17 |  |
™U.K. Prime mInister Tony Blair and U.S. Presiden George W.Bush shake hands in front of the UK Parliament" |
( 実物の画像 )
- 以下、米ブッシュ(元)大統領も英ブレア(元)首相も、いずれも現職在任当時の画像
| No. | 実際の画像1 | 実際の画像2 | 実際の画像3 |
|---|---|---|---|
| 18 |  |
 |
 |
今度は、レディ・ガガとマイケル・ジャクソンで検証してみます。
- レディガガ(左)とマイケルジャクソン(右)に見えなくもない
| No. | 出力画像 | 入力した英文 | 備考 |
|---|---|---|---|
| 19 |  |
Michael Jackson and ady Gaga are dancing at the building of SONY Music Inc. located at New York city |
今度は、広く知られた地名と建物物が学習済みか、検証してみます。
| No. | 出力画像 | 入力した英文 | 備考 |
|---|---|---|---|
| 20 |  |
The Eiffel Tower on the left side and the triumphal arch on the right side | |
| 21 |  |
A Photo of the Golden Gate Bridge at San Francisco in winter |