__DALL-E__の実装コードについて簡単に触れさせてください。
__DALL-E__は、Open AIによって開発・発表されましたが、実装コードは一部しか公開されていません(2021年9月5日現在)。
DALL-Eのうち、すでに公開されている(DALL-Eの)画像圧縮器(Discrerte VAE)と、(DALL-Eを開発したOpenAIから別に公開されている)画像とテキスト文の類似度を定量評価してくれる__CLIP__を連結させた__DALL-Eの再現モデル__のコード実装が、サードパーティのプログラマである@advadnoun氏によって公開されています。
そして、この実装コードにさらに改良の手を加えたコードが、__cedro3__さんによって公開されています。
今回は、この__cedro3__さんが公開してくれている「DALL-EのDiscrerte VAE」と「CLIP」の連携モデルを動かしてみます。このモデルは、英文指示文を受け取って、その文に描かれた内容を描写した画像を自動生成するとき(=推論フェーズ)、次のループ処理を指定されたイテレーション(iteration)回数、繰り返します。
( 以下のループをひたすら回す )
・Discrete VAEにランダムパラメータを与えて、 画像を生成
・テキストと、DALL-E Image Decoderから出力された画像をそれぞれ、clipで特徴ベクトル化
・両ベクトル間の類似度をclipで算出(clipで画像とテキストの類似度評価)
・類似度をさらに高めるために、 ランダムパラメータを更新
・新たなランダムパラメータをDiscrete VAEに入力し、 前回よりもテキストに近い画像を生成
( 前提 )
本記事では、次の記事でメソッド化した「DALL-EのDiscrerte VAE」と「CLIP」の連携モデルを動かしました。
以下をメソッド化
ここから、オリジナルのColaboratory notebookではベタ打ちで実行していたコードを、繰り返し実行しやすいようにメソッドのブロックに包みます。
- メソッド名: draw_image_based_upon_text
- 引数: text (取り扱う英文テキスト。str型オブジェクト)
( 関連記事 )
以下の記事では、人名ではなく、シャネルやiPhoneやジャガー(車)といったブランド名の認識力を検証しました。
( 実験結果 )
今回、次の著名人の顔を試しました。
その結果、「DALL-EのDiscrerte VAE」と「CLIP」の連携モデルは、これらの人物の顔を「学習済み」であると考えられることがわかりました。
- アルバート・アインシュタイン博士
- スティーブ・ジョブズ
- ビル・ゲイツ
- オバマ元大統領
アルバート・アインシュタイン博士
input_text = "a photo of albert einstein"
draw_image_based_upon_text(input_text, 4000)
- アインシュタイン博士らしい顔が出てきました

今度は、イテレーション数を7,000に増やしてみます。
input_text = "a photo of albert einstein"
draw_image_based_upon_text(input_text, 7000)

指示文から__a photo of__を取り除いてみます。
input_text = "albert einstein"
draw_image_based_upon_text(input_text, 7000)
もう1回、実行してみます。

スティーブ・ジョブズ
input_text = "a photo of the face of steve jobs"
draw_image_based_upon_text(input_text, 7000)
- 25✖️50=1250iteration目までは良い感じ
- この時点で、「DALL-EのDiscrete VAE + CLIP」モデルは、スティーブ・ジョブズさんの顔を学習済みだと判断できます

- 28✖️50=1400iteration目以降、顔の左下に別の人物の顔が写り込んでしまう

- 7,000iteration目

input_text = "a photo of steve jobs"
draw_image_based_upon_text(input_text, 7000)
- 27✖️50=1350iteration目以降、顔の左側に別の人物の顔が写り込んでしまう

- 7,000iteration目

input_text = "steve jobs"
draw_image_based_upon_text(input_text, 7000)
- これはNGです。

ビル・ゲイツ
input_text = "a photo of Bill Gates"
draw_image_based_upon_text(input_text, 7000)
- 左右で2人の顔がダブっています
- 左側は、ビルゲイツさんの顔です。右側には髪だけが見えるもう1人の人物がいます。これは若かりし頃のビルゲイツさんの髪に見えなくもないです。
- この時点で、「DALL-EのDiscrete VAE + CLIP」モデルは、ビルゲイツさんの顔を学習済みだと判断できます

input_text = "a photo of the face of bill gates"
draw_image_based_upon_text(input_text, 7000)
- 26✖️50=1300iteration目までは良い感じ

- 30✖️50=1500iteration目以降、複数の顔が混ざり始めてしまう

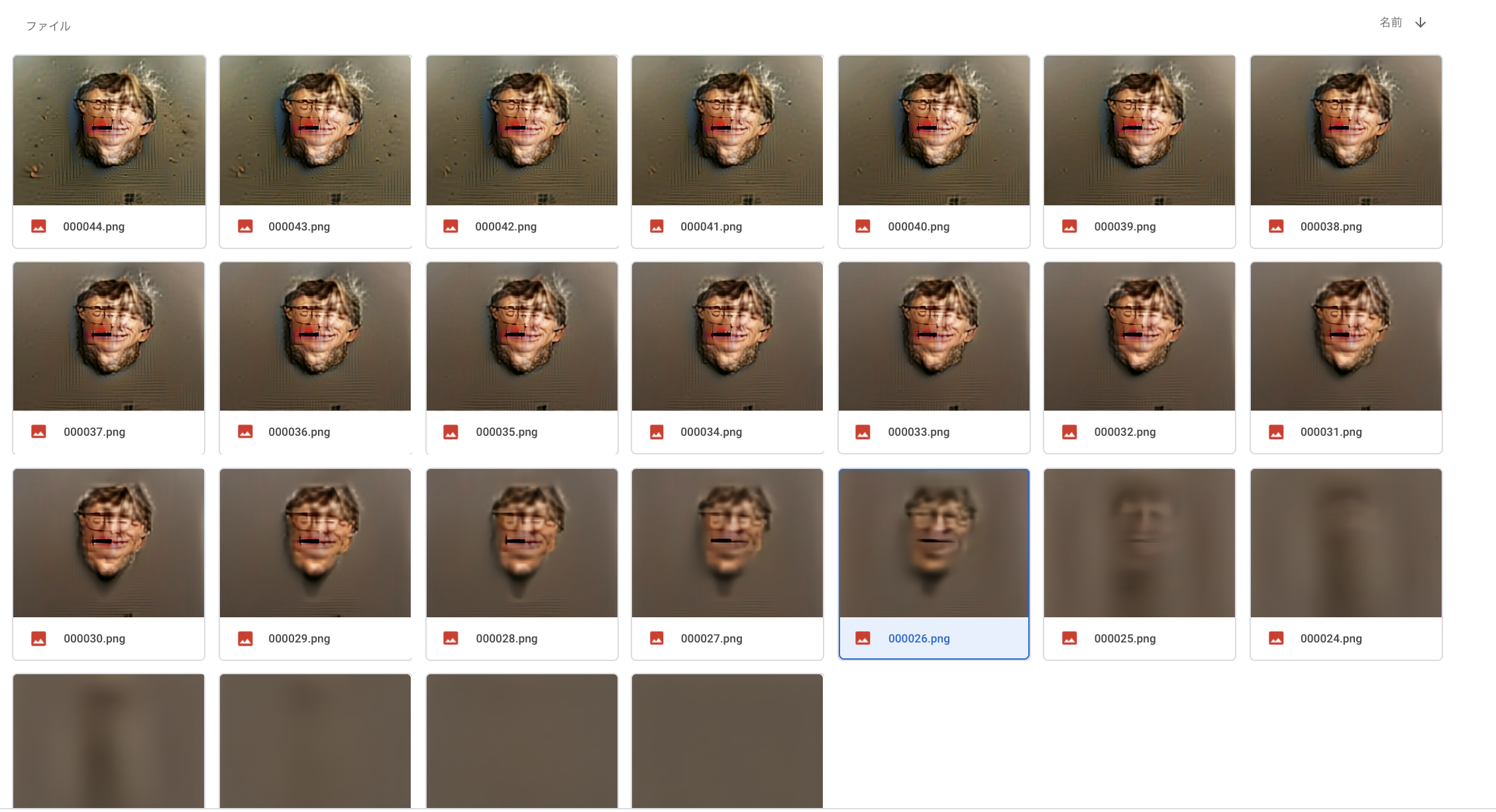
- 7000iteration目

オバマ元大統領
input_text = "barack obama"
draw_image_based_upon_text(input_text, 4000)
- オバマ元大統領らしい顔が出てきた
- でも、裏側に別の人(トランプ元大統領??)らしき顔も描かれている・・・(汗)

今度は、イテレーション数を7,000に増やしてみます。
input_text = "a photo of barack obama"
draw_image_based_upon_text(input_text, 7000)
- 今度も、裏側に別の人(トランプ元大統領??)らしき顔も描かれている・・・(汗)

もう1回、実行してみます。
- 今度は裏側にいる人も、オバマさんっぽい(?)です。
- しかし、裏側にもう1人の顔が映ってしまう事象は解消されませんでした。

【 実験対象 】 「DALL-EのDiscrete VAE + CLIP」の連携モデル
冒頭で触れた__DALL-E__の実装コードについて、詳しく解説します。
__DALL-E__は、Open AIによって開発・発表されましたが、実装コードは一部しか公開されていません(2021年9月5日現在)。
公開されているのは、画像データの次元数を圧縮して、データサイズが小さい画像特徴ベクトルを作り出す部分だけです(この画像次元数を圧縮する部分は、__Discrete VAE(離散変分オートエンコーダ)__という手法が採用されています)。
( DALL-E実装コードの公開部分 )
###Overview
This is the official PyTorch package for the discrete VAE used for DALL·E. The transformer used to generate the images from the text is not part of this code release.
###Installation
Before running the example notebook, you will need to install the package usingpip install DALL-E
DALL-Eの中で、テキスト文を入力値として受け取り、受け取った文に描かれている場面・情景や概念をうまく表現するイメージ画像を、出力値として出す部分は、未公開の状況です(2021年9月5日現在)。
OpenAIの公式GitHubに掲げられている次の文でそのことが述べられています。
The transformer used to generate the images from the text is not part of this code release.
実装コードが公開されていないこの部分は、120億個のパラメータを持つTransformerモデルです。Open AIはウェブ空間から2億5千万件の画像とテキストのペアを集めて、このTransformerモデルを学習させたと発表しています。
残念ながら、テキストを画像に変換する肝心の部分が未公開のため、Open AIから公開されている実装コードだけでは、DALL-Eモデルを動かすことはできません。
ところで、Open AIからは、テキストと画像の類似度を数値で評価してくれる__CLIP__モデルも公開されています。__CLIP__に画像ファイルを1枚と、任意個の英単語を引数として渡して実行すると、その画像が任意個ある各英単語に対応する確率を小数(確率値)で返してくれます。全単語の小数(確率値)の総和をとると1になります。
例えば、ドラえもんの画像ファイルと、単語リスト ["dog", "cat", "human", "melon", "ice cream", "car"]を渡して、返り値として[0.200, 0.700, 0.035, 0.025, 0.015, 0.025]が得られたとしましょう。
この例では、画像が"cat"に該当する確率値が"0.700" (=70%)ともっとも高いので、ドラえもんの画像は、指定した単語リストの中では、"cat"である確率が最も高いとCLIPが判断したことになります("cat"の次に該当確率が高い単語ラベルは、"dog"になる。"dog"の該当確率は0.200 (=20%)です)。
この__CLIP__に、次の2つのベクトルを入力データとして入れることで、テキストと画像が__どれだけ似ているか__の__正解率を得る__ことができます。
- 【 入力1 】 ユーザから入力されたテキスト文を特徴ベクトルに変換した文ベクトル
- 【 入力2 】 低次元の画像ベクトル。DALL-Eの構成部品としてすでに公開されている画像データの次元圧縮器(Discrete VAE)から出力された画像ベクトル
この__CLIPから出力され正解率(類似度)を、誤差逆伝播で最大化する__ことで、__与えられたテキスト文に対応する適切な画像を「生成」する__ことができます。
この「公開済みのDALL-Eの画像圧縮器」と、「(DALL-Eを開発したOpenAIから別に公開されている)CLIP」を連結させた__DALL-Eの再現モデル__のコード実装が、サードパーティのプログラマである@advadnoun氏によって公開されています。そして、この実装コードにさらに改良の手を加えたコードが、__cedro3__さんによって公開されています。(このコードをこの記事では、「擬似DALL-Eモデル」と呼ぶことにしたのでした)。
__擬似DALL-Eモデル__は、英文指示文を受け取って、その文に描かれた内容を描写した画像を自動生成するとき(=推論フェーズ)、次のループ処理を指定されたイテレーション(iteration)回数、繰り返します。
( 以下のループをひたすら回す )
・Discrete VAEにランダムパラメータを与えて、 画像を生成
・テキストと、DALL-E Image Decoderから出力された画像をそれぞれ、clipで特徴ベクトル化
・両ベクトル間の類似度をclipで算出(clipで画像とテキストの類似度評価)
・類似度をさらに高めるために、 ランダムパラメータを更新
・新たなランダムパラメータをDiscrete VAEに入力し、 前回よりもテキストに近い画像を生成
# CLIPのモデル化
! pip install ftfy regex
import clip
model, preprocess = clip.load('ViT-B/32', jit=True)
model = model.eval()
# DALL-Eのモデル化
! pip install DALL-E
from dall_e import map_pixels, unmap_pixels, load_model
dec = load_model("https://cdn.openai.com/dall-e/decoder.pkl", 'cuda')
( 中略 )
# テキスト入力
text_input = text
iteration_number = iteration_num
# テキストを特徴ベクトルに変換
token = clip.tokenize(text_input)
text_v = model.encode_text(token.cuda()).detach().clone()
( 中略 )
# 学習ループ
for iteration in range(iteration_number):
# --- 順伝播 ---
# パラメータから画像を生成
out = unmap_pixels(torch.sigmoid(dec(latent())[:, :3].float()))
# 画像をランダム切り出し・回転
into = augment(out)
# 画像を正規化
into = nom((into))
# 画像から特徴ベクトルを取得
image_v = model.encode_image(into)
# テキストと画像の特徴ベクトルのCOS類似度を計算
loss = -torch.cosine_similarity(text_v, image_v).mean()
実装コードのうち、コアとなる部分は次の2つの部分です
【 コードを読む1 】
パラメータからdiscrete VAE(DALL-E)で画像を生成する部分
- パラメータは最初はランダム値です。
- ループ処理の1周目では、このランダム・パラメータが使われる
# パラメータリセット latent = Pars().cuda()
# DALL-Eのモデル化
! pip install DALL-E
from dall_e import map_pixels, unmap_pixels, load_model
dec = load_model("https://cdn.openai.com/dall-e/decoder.pkl", 'cuda')
( 中略 )
# パラメータリセット
latent = Pars().cuda()
( 中略 )
# 学習ループ
for iteration in range(1001):
# --- 順伝播 ---
# パラメータから画像を生成
out = unmap_pixels(torch.sigmoid(dec(latent())[:, :3].float()))
【 コードを読む2 】
生成された画像(の特徴ベクトル)と、テキスト(の特徴ベクトル)の類似度をCLIPで評価し、CLIPによる類似度を最大化する方向に、パラメータを誤差逆伝播修正する部分
# テキスト入力
text_input = 'an armchair in the shape of an avocado'
( 中略 )
# テキストを特徴ベクトルに変換
token = clip.tokenize(text_input)
# 学習ループ
for iteration in range(1001):
( 中略 )
# 画像から特徴ベクトルを取得
image_v = model.encode_image(into)
# テキストと画像の特徴ベクトルのCOS類似度を計算
loss = -torch.cosine_similarity(text_v, image_v).mean()
# 逆伝播
optimizer.zero_grad()
loss.backward()
optimizer.step()
今回は、この__cedro3__さんの実装コードをGoogle Colab+で動かしました。
なお、次のウェブサイトでも、この「DALL-Eのdiscrete VAE + CLIP」の組み合わせが採用されています。