HadoopにHTTP接続しようと思ったのに全然うまくいかないという人は下の方の”ここからがかなり未知な部分です。”からみて下さい
Opentsdb 使いたい!
そう思った貴方、まずはHadoopを考える所から始めないといけません。私がそうでした。
そしてこのHadoop、つい先日3.0.0が出てきまして、それまで2系でぬくぬくしていた私は精神を削り髪を落としながら悩むことになったのです。
環境説明等
ざっくりいうと、VirtualBoxでArch Linux(EFI)の、openjdk-8です。opensshとか標準的なものは大丈夫だと仮定して話を進めます。ユーザ名は、test という形にしておくので "vagrant" とか好きな名前に置き換えて下さい。また、今回は疑似分散までを説明します。
Arch のインストール
Yesとか任意の文字列とか入れてくれれば流れるように進んでいきます。
#ls /sys/firmware/efi/efivars ;; 中身があることを確認
#parted /dev/sda
() mklabel gpt
() mkpart ESP fat32 1MiB 513MiB
() set 1 boot on
() mkpart primary ext4 513MiB 100%
() quit
# lsblk /dev/sda ;; sda1 と sda2を確認
# mkfs.vfat -F32 /dev/sda1
# mkfs.ext4 /dev/sda2
# mount /dev/sda2 /mnt
# mkdir /mnt/boot && mount /dev/sda1 /mnt/boot
# nano /etc/pacman.d/mirrorlist
;; Japanサーバを一番上に持ってくる
;; C-W Japan / Shift で範囲選択 / C-k でカット / C-u で貼り付け
# pacman -Syyu archlinux-keyring
# pacstrap /mnt base base-devel
# genfstab -U /mnt >> /mnt/etc/fstab
# arch-chroot /mnt
# ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime
# hwclock --systohc --utc
# nano /etc/locale.gen
en_US.UTF-8 UTF-8
ja_JP.UTF-8 UTF-8 を追記
# locale-gen
# echo LANG=en_US.UTF-8 > /etc/locale.conf
# echo localhost >> /etc/hostname ;; hadoopを試した時にこうした方が良かった
# nano /etc/hosts ;; ここ重要
127.0.0.1 localhost.localdomain localhost
192.168.1.31 test.localdomain test に更新!
# mkinitcpio -p linux
# passwd
;; 好きなものに
# pacman -S grub efibootmgr
# grub-install --target=x86_64-efi --efi-directory=/boot --bootloader-id=arch_grub --recheck
# mkdir /boot/EFI/boot
# cp /boot/EFI/arch_grub/grubx64.efi /boot/EFI/boot/bootx64.efi
# grub-mkconfig -o /boot/grub/grub.cfg
# exit
# umount -R /mnt
;; virtualboxメニュー=>isoディスクを取り外す
# reboot
login : root
passwd : ;;さっき入れたもの
# systemctl enable dhcpcd & systemctl start dhcpcd
# systemctl status dhcpcd
;; ちゃんと動いているのを確認
# useradd -m test ;; vagarnt ユーザならvagrant
# paddwd test
;; vagrant ユーザは vagrantにする必要がある...はず
# EDITOR=nano visudo
test ALL=(ALL) NOPASSWD: ALL を任意の箇所に追記
# pacman -S openssh wget
# systemctl enable sshd.service
# systemctl start sshd.service
# systemctl status sshd.service
;; sshd サービスが有効になっていることを確認
# pacman -S emacs git curl jre8-openjdk jdk8-openjdk
# su - test
$ sudo emacs /etc/pacman.conf
[archlinuxfr]
SigLevel = Never
Server = http://repo.archlinux.fr/$arch を追記
[multilib]
Include = /etc/pacman.d/mirrorlist のコメントアウトを削除
$ sudo pacman --sync --refresh yaourt
$ sudo pacman -Syu yaourt
$ sudo emacs /etc/yaourtrc
TMPDIR="/home/test/Downloads" を追記
$ sudo pacman -S virtualbox-guest-modules-arch
$ sudo modprobe -a vboxguest vboxsf vboxvideo
$ sudo emacs /etc/modules-load.d/virtualbox.conf
vboxguest
vboxsf
vboxvideo を書き込む
$ sudo pacman -S virtualbox-guest-utils
$ sudo systemctl enable vboxservice
$ sudo systemctl start vboxservice
$ sudo systemctl status vboxservice
$ sudo reboot
login : test
password : ;;さっき入れたもの
$ ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ sudo emacs /etc/ssh/sshd_config
# AuthorizedKeysFile .ssh/authorized_keys をコメントアウト
$ ssh localhost
$ exit
$ sudo pacman -S xorg xorg-server deepin
$ sudo pacman -S deepin-extra
$ sudo systemctl enable deepin-desktop
$ sudo emacs /etc/lightdm/lightdm.conf
greeter-session=lightdm-deepin-greeter に変更
;; greeter-session= を検索して、その部分を書き換える(コメントされていればコメントを外す)
$ sudo systemctl start lightdm
;; ここでGUIが起動する、はず
;; 起動したら、デスクトップを右クリックして、terminalを開く
;; deepin desktop の使い方については、ここでは扱わない
$ sudo systemctl enable lightdm
$ sudo shutdown -h now
以上!(スナップショットを取ってきおきましょう)
Hadoop のインストール
今回はhadoopユーザを新しく作らず、そのままインストールしていきます。新しくユーザを作りたければ、sudo useradd hadoop sudo passwd hadoop などとしてhadoopユーザを作って、そちらにログイン (su - hadoop) して下さい。こちらでも test というユーザ名で進めていきます。
Hadoopのパス
詳しく調べてはいないんですが、恐らくhadoopなどは直リンクすると怒られるので、hadooopのwget先のパスは以下のようにして入手して下さい。
- http://www.apache.org/dyn/closer.cgi/hadoop/common/ にアクセスする
- httpの日本サーバを適当に選択する (tsukubaとか)
- hadoop-3.0.0を選択する
- hadoop-3.0.0.tar.gzを右クリック
- リンク先をコピーする
これで、virtualboxのクリップボードの共有ができていれば、簡単にwgetすることが出来る。
Hadoop のインストール
作ったArchLinuxを立ち上げて(ここでvirtualboxの設定からクリップボードの共有が出来るようにしておく)
$ cd ~/Downloads
$ wget <had-pass> ;; さっき取ってきたパス
$ tar zxfv hadoop-3.0.0.tar.gz
$ sudo cp -r ./hadoop-3.0.0 /usr/local/hadoop
$ sudo chown -R test /usr/local/hadoop
$ sudo mkdir /usr/local/hadoop_tmp
$ sudo chown -R test /usr/local/hadoop_tmp
$ cd /usr/local/hadoop
$ ls
;; 色々あることを確認(bin,etc,sbinなど)
$ sudo emacs ~/.bashrc
### HADOOP PATHES ###
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export PATH=$PATH:/usr/local/hadoop/bin/
######################### を末尾に追記する
$ source ~/.bashrc
$ sudo emacs ./etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk/ を追記
$ sudo emacs ./etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration> にする
$ sudo emcas ./etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
$ sudo emcas ./etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
$ sudo emacs ./etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
$ cd ~
$ hdfs namenode -format
;; なんやかんやして、
;; SHUTDOWN_MSG: Shutting down NameNode at localhost/127.0.0.1 と帰ってくるはず...(192.168.1.11と返ってくることもある...?)
;; INFO ではなく ERROR が帰ってきている部分があったら質問サイトやその手の場所を巡ったほうが良いです
$ start-all.sh
$ jps
XXXX SecondaryNameNode
XXXX NameNode
XXXX ResourceManager
XXXX NodeManager
XXXX Jps
XXXX DataNode となっていたら正しい
さて、これでHadoopを大体セットアップできました。
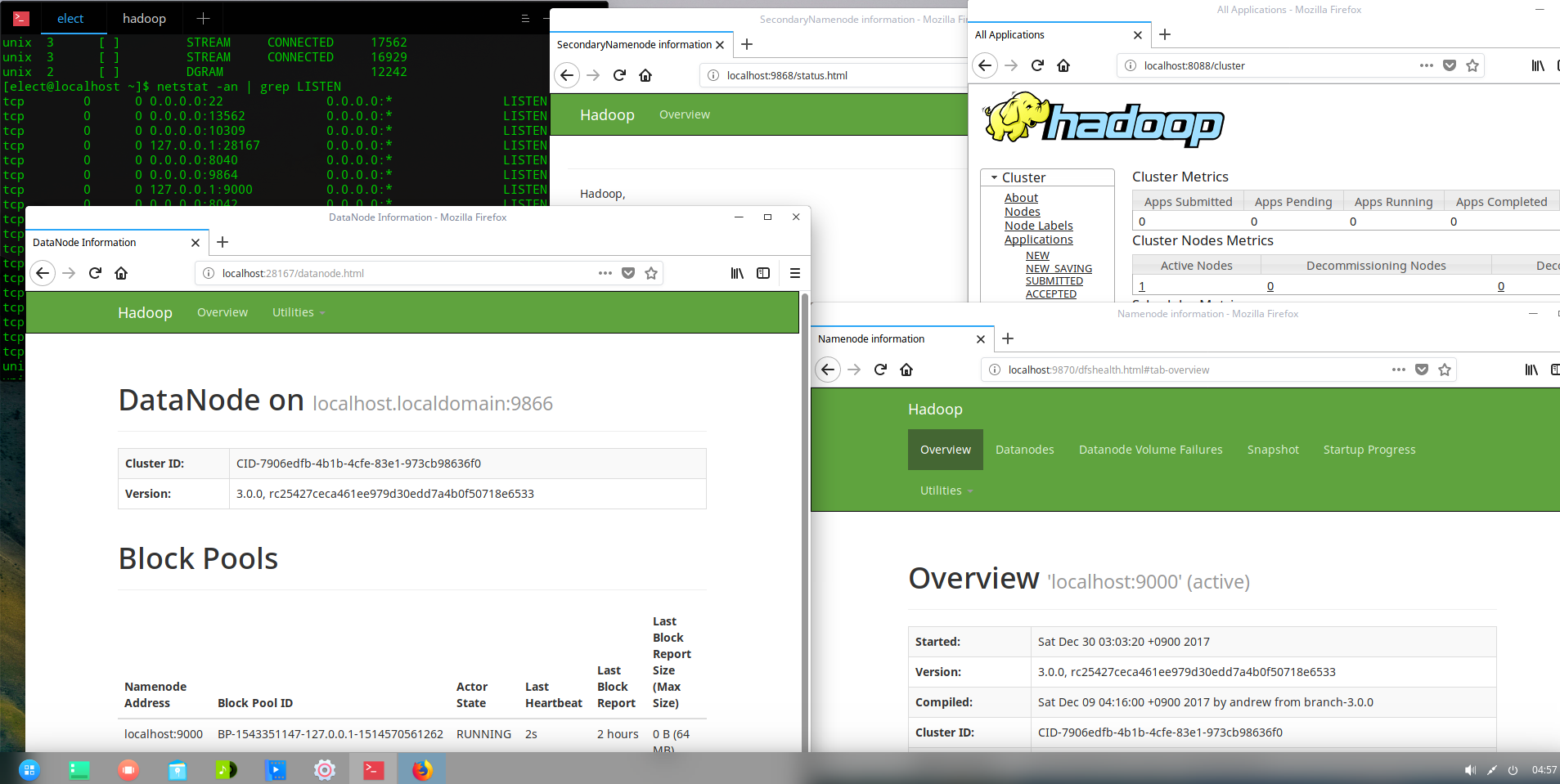
ここからがかなり未知な部分です。
普通はここから、「ではhttp://localhost:50070 にアクセスしてみましょう!」となるんですが、なぜかこれが上手く行きません。理由はよくわからないのですが、空いているポート番号が違うようです。以下のように確認して、片っ端から「http://localhost:[hogehoge]」 して下さい。私の環境では、0.0.0.0:8XXXや、0.0.0.0:9XXX, 127.0.0.1:28XXX が書き換わった先に該当していました。また、localhost:8088 はそのまま接続することが出来ました。
$ netstat -an | grep LISTEN ;; <==ここかなり重要
tcp 0 0 0.0.0.0:22 ..... LISTEN
tcp 0 0 0.0.0.0:13562 ..... LISTEN
tcp 0 0 127.0.0.1:9000 .... LISTEN
tcp 0 0 ::::8088 .......... LISTEN