Pythonで大量の文字列のリストから前方一致文字列を見つける際に、すこし早く見つけるための方法を試してみたのでご紹介します。
簡単にまとめると、二分探索の利用による高速化です。
普通のリスト中の前方一致文字列抽出
Pythonのリスト内包表記を使うと、
ans_str_list = [x for x in str_list if (条件)]
とすれば、条件にあてはまる文字列を抽出できます。
例えば、"bcd"と前方一致する文字列を抽出したい場合は、
ans_str_list = [x for x in str_list if x.startswith("bcd")]
と入力すれば、前方一致文字列を抽出できます。
線形探索と二分探索
リスト内包表記を利用して条件にあてはまる文字列を抽出する操作は、リスト中の文字列を最初から最後まで全てについて条件が当てはまるかどうかチェックしています。
これを、線形探索 といいます。
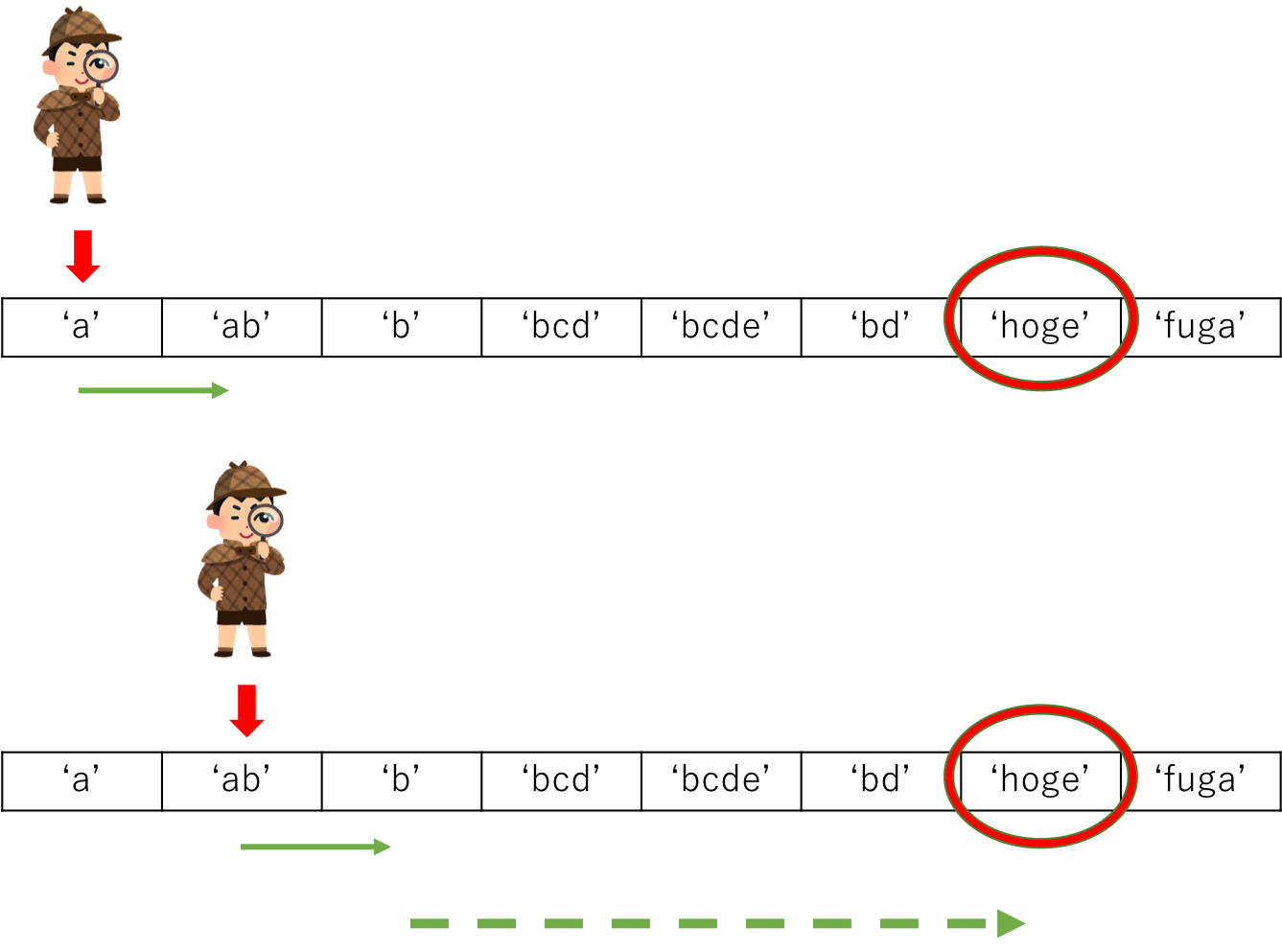
一方、もしもリストがすでに並び替えられている場合、探索する範囲を半分、半分…と狭めていく探索方法があります。これを、二分探索 と言います。
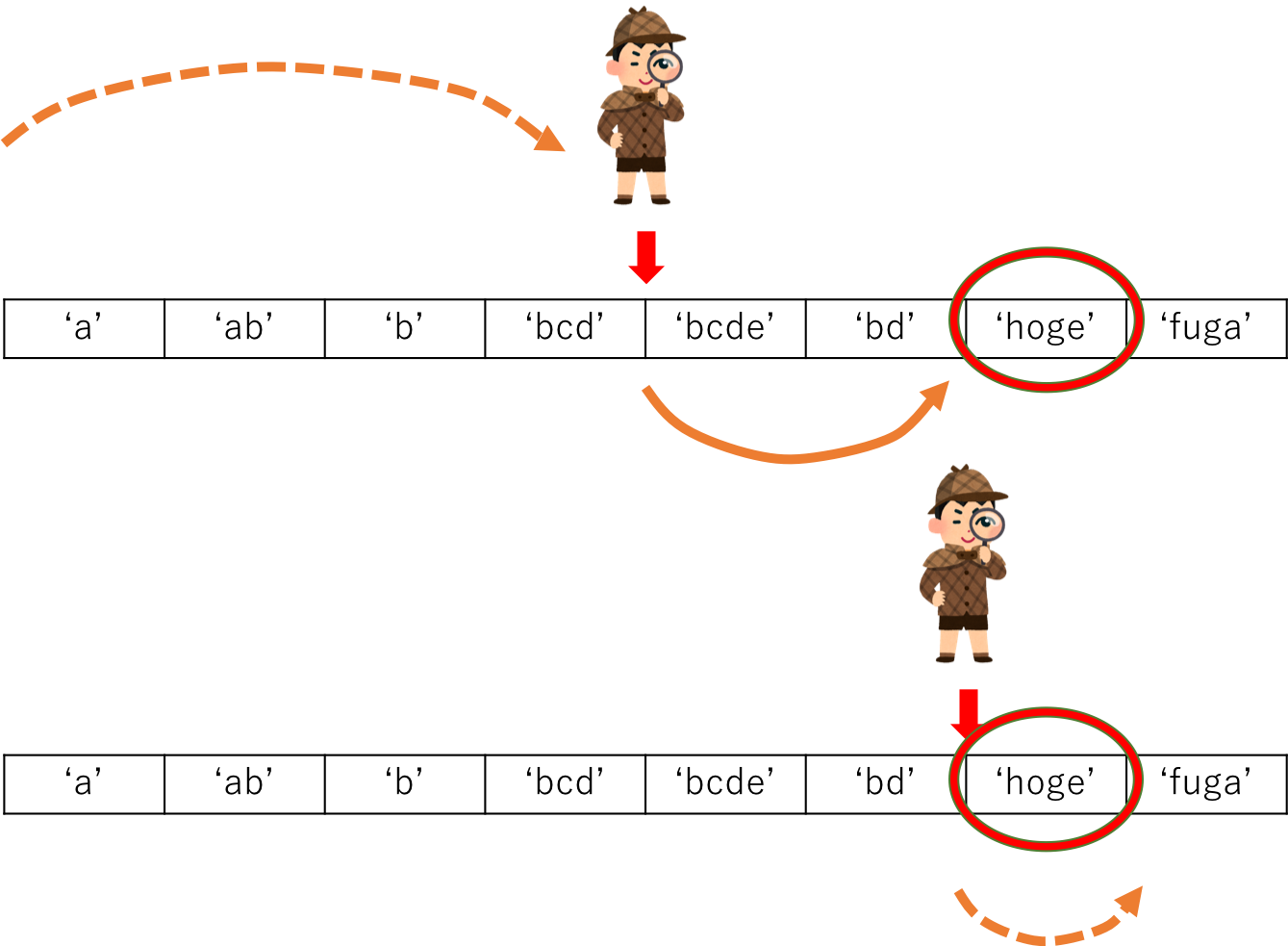
もしもリスト全体の長さが$2^n$だったときに、線形探索する場合は比較の回数が$2^n$になるのに対し、二分探索を使えばn回の比較計算で済みます。つまり、線形探索で約100万回する必要がある比較が、二分探索ではたったの約20回でできるのです。
これをオーダー表記すると、リストの長さを$n$とおくと、線形探索の計算量は$O(n)$、二分探索の計算量は$O(\log n)$であると表すことができます。
二分探索による前方一致文字列検索
pythonには、bisectという二分探索用のライブラリが標準的に用意されています。
並び替え済み(ソート済み)文字列リストsorted_str_listから文字列search_strを前方一致検索したいとした場合、
手順としては、
-
bisectというライブラリを使ってソート済み文字列リストsorted_str_listにsearch_strを挿入できる場所を二分探索を用いて探す。 - 同様に、
sorted_str_listに、search_strの末字が「1だけ大きい」文字列search_str[:-1]+chr(ord(search_str[-1])+1)を挿入できる場所を二分探索を用いて探す。 - 1.の場所と2.の場所の間の範囲を答えとする。
ということを行います。
コードで示すと、
import bisect
# 開始点
top_point = bisect.bisect_left(sorted_str_list, search_str)
# 終了点
end_point = bisect.bisect_left(sorted_str_list, search_str[:-1]+chr(ord(search_str[-1])+1))
# 前方一致文字列リスト
print(sorted_str_list[top_point:end_point])
で行うことができます。
文字列リストのソート(並び替え)
上記の二分探索による文字列リスト検索は、ソート済み文字列リストにしか使えません。
文字列のリストのソートは、
sorted_str_list = sorted(str_list)
とするとできます。Pythonでは文字列の大小比較は辞書順で行われるので、
['a', 'ab', 'b', 'bcd', 'bcde', 'bd', 'hoge', ...]
Pythonのリストのソートは、ドキュメントを見ると、
Python では Timsort アルゴリズムが利用されていて、効率良く複数のソートを行うことができます、これは現在のデータセット中のあらゆる順序をそのまま利用できるからです。
と書いてあります。
Timsortは聞きなれない手法ですが、Wikipedia先生に聞くと
平均計算量:$O(n\log n)$
最良計算量:$O(n)$
最悪計算量:$O(n\log n)$
...
Timsortは適応ソートである。
と書いてあります。つまり、比較的速めのアルゴリズムで、適応ソートであることから元のリストがソートされているほど計算量が少なくなるみたいです。
理論的な計算量
上記で述べた線形探索と二分探索にかかる時間を比べてみたいと思います。
線形探索は、ソートされていない文字列リストの中の各文字列が前方一致するか調べていきます。
- 線形探索一回の計算量は、$O(n)$です。
二分探索は、ソートされている文字列リストから効率的に前方一致する文字列を検索します。
ソートされていない文字列リストに適用する場合は、まずソートを行う必要があります。
- ソートの計算量は、$O(n\log n)$です。
- 二分探索一回の計算量は、$O(\log n)$です。
そのため、未ソート文字列リストの大きさを$n$、検索する文字列の数を$x$とすると、線形探索・二分探索を用いた場合のリスト中の文字列検索時間はそれぞれ
| 探索方法 | 計算量 |
|---|---|
| 線形探索 | $O(x) O(n)$ |
| 二分探索 | $O(n\log n)+O(x)O(\log n)$ |
となります。もし、$x$が10回とかの定数とみなせる場合は、
O(x)O(n)\simeq O(n)
O(n\log n)+O(x)O(\log n) \simeq O(n\log n)+O(\log n) \simeq O(n\log n)
より、線形探索のほうが二分探索よりも普通は早いです。
もし$x$が$n/10$などnの一次関数とみなせる場合は、
O(x)O(n)\simeq O(n)O(n) \simeq O(n^2)
O(n\log n)+O(x)O(\log n) \simeq O(n\log n)+O(n)O(\log n) \simeq O(n\log n)
となるので、二分探索の方が一般的に早くなります。
まとめ
まとめると、未ソート文字列リストから前方一致する文字列を検索する場合、検索したい前方一致文字列の種類が少ない場合は線形探索の方が早くなるものの、検索したい文字列の種類が多い場合は二分探索の方が早くなります。
(二分探索では、検索したい文字列の種類が多いほどソートにかかるコストを取り返せるというイメージです。)
実験
環境
Macbook Pro(2017)
CPU: 2.3 GHz Intel Core i5
メモリ: 8 GB
Python: 3.6.4
実験方法
| 変数 | 説明 |
|---|---|
| 検索対象文字列リスト(str_list) | アルファベット小文字26種からなる100字の文字列1,000,000個のリスト |
| 検索文字列リスト(search_list) | アルファベット小文字26種からなる3字の文字列$x$個のリスト |
線形探索(L)の場合
- 検索文字列の数$x$回、線形探索をします。
二分探索(B)の場合
- str_listをソートします。
- 検索文字列の数$x$回、二分探索をします。
結果
| 検索文字列数$x$ | ソート時間(線形探索L)[s] | 検索時間(L)[s] | 合計時間(L)[s] | ソート時間(二分探索B)[s] | 検索時間(B)[s] | 合計時間(B)[s] |
|---|---|---|---|---|---|---|
| 1 | - | 0.170 | 0.170 | 1.04 | 3.98e-05 | 1.04 |
| 5 | - | 0.810 | 0.810 | 1.03 | 8.82e-05 | 1.03 |
| 10 | - | 1.63 | 1.63 | 1.04 | 1.39e-04 | 1.04 |
| 100 | - | 16.9 | 16.9 | 1.04 | 1.29e-03 | 1.04 |
| 1000 | - | 171 | 171 | 1.03 | 1.08e-02 | 1.06 |
ということで、検索する文字列の数が多い場合(約10回以上)は、二分探索の方が早いとわかりました。
応用
後方一致文字列検索の場合
二分探索は後方一致文字列検索の場合にも応用できます。
ケースとしては、ファイルのリストからある拡張子のファイル名を全て抽出する場合が考えられます
まず、
inv_str_list = [x[::-1] for x in str_list]
s_str = search_str[::-1]
として文字列をそれぞれひっくり返してから、前方一致と同じように
# 並び替え
sorted_inv_str_list = sorted(inv_str_list)
import bisect
# 開始点
top_point = bisect.bisect_left(sorted_inv_str_list, s_str)
# 終了点
end_point = bisect.bisect_left(sorted_inv_str_list, s_str[:-1]+chr(ord(s_str[-1])+1))
# (倒置)前方一致文字列リスト
temp_str_list = sorted_inv_str_list[top_point:end_point])
として二分探索による検索を行い、
ans_str_list = [x[::-1] for x in temp_str_list]
と戻せば後方一致文字列リストを得ることができます。
ただし、前方一致か後方一致以外への応用はぱっとは難しいです。。。
補足
もしもリストを頻繁に書き換える必要がある場合は、文字列のソートの結果をリストとして持つよりも二分探索木もしくは平衡木として持っておいた方がよさそうです。