パン屋のアルゴリズムを理解する
パン屋のアルゴリズムとは、並行プログラミングにおいて、安全に相互排除を行うためのアルゴリズムです。
特に、アトミック処理を前提としていない場合用いられます。。
並行プログラミング 入門を読んでいて、詰まったので自分なりに整理します。
アトミック処理
アトミック処理とは、別スレッドからの干渉を受けずに実行することのできる処理です。
例えば、以下のようなcompare_and_swap関数を考えたときに、この処理はアトミック処理でしょうか?
うまくいかないコード
# include<stdint.h>
bool compare_and_swap(uint64_t *p, uint64_t val, uint64_t newval) {
if(*p != val) {
return false;
}
*p = newval;
return true;
}
//x86-64 gcc
compare_and_swap(unsigned long*, unsigned long, unsigned long):
push rbp
mov rbp, rsp
mov QWORD PTR [rbp-8], rdi
mov QWORD PTR [rbp-16], rsi
mov QWORD PTR [rbp-24], rdx
mov rax, QWORD PTR [rbp-8]
mov rax, QWORD PTR [rax]
cmp QWORD PTR [rbp-16], rax
je .L2
mov eax, 0
jmp .L3
.L2:
mov rax, QWORD PTR [rbp-8]
mov rdx, QWORD PTR [rbp-24]
mov QWORD PTR [rax], rdx
mov eax, 1
.L3:
pop rbp
ret
一般的には、違うみたいです。
C言語で記した処理は、コンパイラ(gcc)でアセンブリコードにコンパイルすると、実際は複数の操作を組み合わせて実現されています。
従って、別スレッドからの干渉を受けずに実行できる処理ではない為、アトミック処理とは一般的には言えません。
うまくいくコード
しかし、最近のプログラミング言語ではアトミックに処理する機構が多く用意されています。
例えば、上のcompare_and_swapをアトミック処理する組み込み関数、__sync_bool_compare_and_swapが用意されています。
https://gcc.gnu.org/onlinedocs/gcc-4.1.0/gcc/Atomic-Builtins.html
# include<stdint.h>
bool compare_and_swap(uint64_t *p, uint64_t val, uint64_t newval) {
return __sync_bool_compare_and_swap(p, val, newval);
}
//x86-64 gcc
compare_and_swap(unsigned long*, unsigned long, unsigned long):
push rbp
mov rbp, rsp
mov QWORD PTR [rbp-8], rdi
mov QWORD PTR [rbp-16], rsi
mov QWORD PTR [rbp-24], rdx
mov rdx, QWORD PTR [rbp-8]
mov rax, QWORD PTR [rbp-16]
mov rcx, QWORD PTR [rbp-24]
lock cmpxchg QWORD PTR [rdx], rcx
sete al
pop rbp
ret
lock cmpxchg
lock を用いて、cmpxchg命令を行うことで、アトミック処理を行います。
https://docs.microsoft.com/ja-jp/windows-hardware/drivers/debugger/x86-instructions
ミューテックス
ミューテックスは、並行プログラミングの際に同時に実行されているプログラム間で、リソースの排他制御、同期を行う仕組みの一つ。
クリティカルセクションを高々一つしか持たない。
うまくいかないコード
以下のコードだと、クリティカルセクションを同時に実行してしまう可能性があり、排他制御ができない。
bool lock = false;
void some_func() {
retry:
if(!lock) {
lock = true;
} else {
goto retry;
}
lock = false;
}
//x86-64 gcc
lock:
.zero 1
some_func():
push rbp
mov rbp, rsp
.L2:
movzx eax, BYTE PTR lock[rip]
xor eax, 1
test al, al
je .L2
mov BYTE PTR lock[rip], 1
mov BYTE PTR lock[rip], 0
nop
pop rbp
ret
うまくいくコード
以下のコードだと、クリティカルセクションを同時に実行してしまう可能性がなく、排他制御できる。
bool lock = false;
void some_func() {
retry:
if(!__sync_lock_test_and_set(&lock, 1)) {
lock = true;
} else {
goto retry;
}
__sync_lock_release(&lock);
}
//x86-64 gcc
lock:
.zero 1
some_func():
push rbp
mov rbp, rsp
.L2:
mov eax, 1
xchg al, BYTE PTR lock[rip]
test al, al
sete al
test al, al
je .L2
mov BYTE PTR lock[rip], 1
mov eax, 0
mov BYTE PTR lock[rip], al
nop
pop rbp
ret
セマフォ
ミューテックスは、並行プログラミングの際に同時に実行されているプログラム間で、リソースの排他制御、同期を行う仕組みの一つ。
クリティカルセクションをN個持つ。
Lamport's bakery algorithm
参考1
参考2
Lamport's bakery algorithm は、アトミック命令をサポートしない場合の同期処理手法です。
上に出てきた、アトミック処理をベースとしたミューテックス、セマフォ、RWロック等の手法が採用できない場合に用います。
実際にちゃんと動くソースコードは、著者様の参考1を確認して下さい。
今回は、メモリバリアを行わないで動かしてみた場合の結果を見てみようと思います。
unsafeなパン屋アルゴリズムと実行結果
use std::ptr::{read_volatile, write_volatile};
use std::thread;
const NUM_THREADS: usize = 4;
const NUM_LOOP: usize = 100000;
struct BakeryLock {
entering: [bool; NUM_THREADS],
tickets: [Option<u64>; NUM_THREADS],
}
impl BakeryLock {
fn lock(&mut self, idx: usize) -> LockGuard {
unsafe { write_volatile(&mut self.entering[idx], true)};
let mut max = 0;
for i in 0..NUM_THREADS {
if let Some(t) = unsafe { read_volatile(&self.tickets[i])} {
max = max.max(t);
}
}
let ticket = max + 1;
unsafe { write_volatile(&mut self.tickets[idx], Some(ticket))};
unsafe { write_volatile(&mut self.entering[idx], false)};
for i in 0..NUM_THREADS {
if i == idx {
continue;
}
while unsafe { read_volatile(&self.entering[i])} {}
loop {
match unsafe { read_volatile(&self.tickets[i])} {
Some(t) => {
if ticket < t || (ticket == t && idx < i) {
break;
}
}
None => {
break;
}
}
}
}
LockGuard { idx }
}
}
struct LockGuard {
idx: usize,
}
impl Drop for LockGuard {
fn drop(&mut self) {
unsafe { write_volatile(&mut LOCK.tickets[self.idx], None)};
}
}
static mut LOCK: BakeryLock = BakeryLock {
entering: [false; NUM_THREADS],
tickets: [None; NUM_THREADS],
};
static mut COUNT: u64 = 0;
fn main() {
let mut v = Vec::new();
for i in 0..NUM_THREADS {
let th = thread::spawn(move || {
for _ in 0..NUM_LOOP {
let _lock = unsafe { LOCK.lock(i) };
unsafe {
let c = read_volatile(&COUNT);
write_volatile(&mut COUNT, c + 1);
}
}
});
v.push(th);
}
for th in v {
th.join().unwrap();
}
println!(
"COUNT = {} (expected = {})",
unsafe { COUNT },
NUM_LOOP * NUM_THREADS
);
}
このコードでは、参考1と比べて、
- メモリバリアをしない
- read_volatile, write_volatileをマクロ化しない
ことをしています。
実際に、cargo run --release してみると、実行結果が不安定になります。
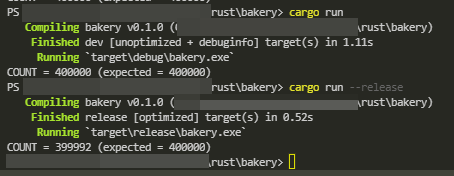
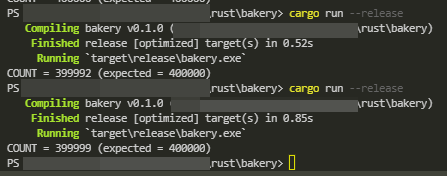
参考