はじめに
この記事は、将棋AIを作ってみようという記事です。
目標は、棋譜データを学習させて、実際に対局できる(ルールに違反しない)ようにさせることとします。
環境:
| 環境 | バージョン |
|---|---|
| OS | Windows Pro 64bit |
| CPU | Ryzen 3900X |
| GPU | Geforce RTX2060Super |
| Python | 3.8.5 |
| CUDA | 10.1 |
| cuDNN | 7.6.5 |
| Chainer | 7.7.0 |
| python-shogi | 1.0.10 |
*PC構成を詳しく知りたい方は、以前の記事[『自作PC構成』]をご覧ください。
*NVIDIA製品のNVIDIA Compute Capability 3.0以上を使用してください。
*GCP, Colaboratory, AWSとかでも実現できると思います(たぶん)
また、この記事ではPytorch ではなく Chainerを使用します。
Pytochでも、構築可能です。
また、別の機会があればPytorchで実装したものもご紹介できればと思います。
§0. 環境構築
この章では、環境構築をします。
0.1 Visual Studio ビルドツール 2015のインストール
現状の最新のVisual Studioは、2019ですが、2019では正常に動作しない報告が多いので2015をインストールします。
Microsoft Build Tools 2015 Update 3 から、インストーラをダウンロードできます。
0.2 CUDAのインストール
NVIDIAからインストーラをダウンロードできます。
2020.11.24時点で、最新バージョンは11.1です。
しかし、使用するソフトウェアに対応したバージョンをインストールします。
現状TensorFlowやChainerなどが対応したバージョンは、10.0, 10.1, (10.2)です。
私は、10.1をインストールしました。
0.3 cuDNNのインストール
NVIDIAから、zipファイルをダウンロードできます。
2020.11.24時点で、最新バージョンは8.0.5です。
しかし、使用するソフトウェアに対応したバージョンをダウンロードします。
現状TensorFlowやChainerなどが対応したバージョンは、7.6以前(8.0以降もたぶん大丈夫)です。
私は、7.6.5で動かしています。
ファイルを解凍したら、NVIDIA GPU Computing Toolkitにファイルをコピーします
私の場合は、
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
にファイルをコピーしました。
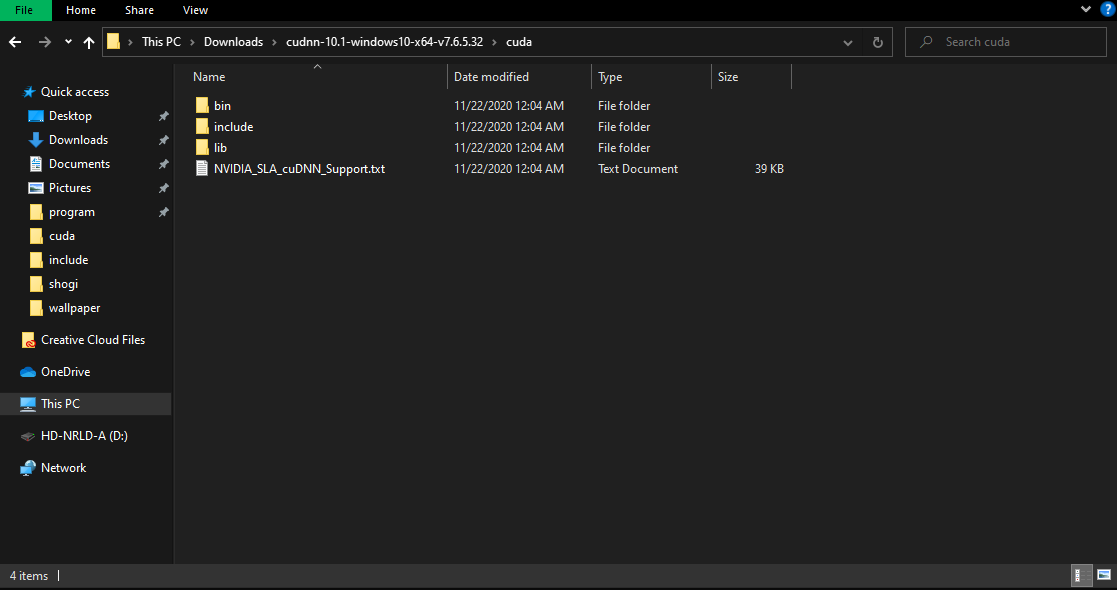
画像にある、ファイル、フォルダをコピーして、上のフォルダに移します。
0.4 Chainerのインストール
Chainerをインストールします。
Chainerは、機械学習のPythonフレームワークです。日本企業の株式会社Preferred Networksが、研究、開発をしました。
現在は、FaceBookのPythonフレームワークである、Pytorchに吸収されました。
0.4.0 Pythonのインストール
Python のインストール
今回は、Pythonは省略します。
Pythonは、3.6以降、3.8までであれば正常に動作します。
Anacondaでも大丈夫です。
0.4.1 その他モジュール
pip install -U pip setuptools
pip install -U jupyterlab jupyter jupyter-console jupytext spyder matplotlib numpy
0.4.2 Cupyのインストール
Chainerで、GPUを使用するためには、Cupyをインストールする必要があります。
pip install cupy-cuda101

確認:

エラーが出なければ大丈夫です。
エラーが出た場合、CuPyのインストールがうまくできていないです。
東京大学金子研究室に詳しく書いてあるので、エラーが出て進めない場合は参考にしてください。
0.4.3 Chainerのインストール
pip install chainer==7.7

0.4.4 Chainerの動作確認
ChainerのGithubから、サンプルを落としてきます。
cd chainer-7.7.0
python examples\mniost\train_mnist.py -g 0
オプションは、gpuの番号です。-1で、gpuを使わずに計算できます。
0.5 学習データ
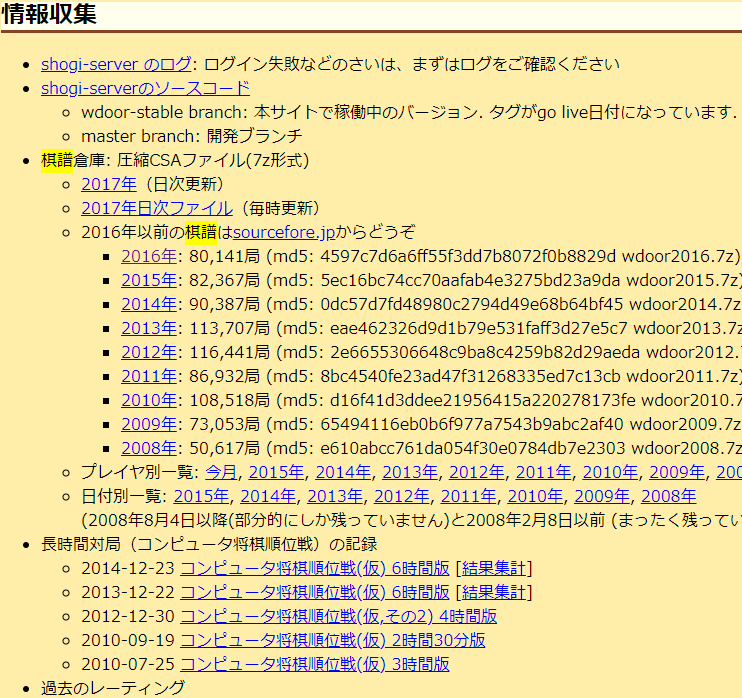
東京大学内のサーバー、将棋コンピュータ対局場(Flood gate)のデータを使います。
後のニューラルネットワークを学習させるための棋譜を用意します。
今回は、『Flood gate』から最新の2020年の全棋譜データをcsa形式で落とします。
http://wdoor.c.u-tokyo.ac.jp/shogi/x/wdoor2017.7z
上は、2017年の棋譜データですが、(webサイト更新されていない),2017→2020にすれば落とせます。(書いていいのか...?)
http://wdoor.c.u-tokyo.ac.jp/shogi/x/wdoor2020.7z
7zipで解凍してください。
全棋譜: 13万件くらい(現状なので、今も増えています)
そのあと、学習データとして適切でないデータもたくさんあるので、手数が50手以上で、レーティングが3000以上のものに限定して、学習データとします。
ここら辺は、どんな方法でもいいです。
§1. ニューラルネットワーク
ここからは、思考部分を実装します。
具体的に、局面から指し手を予測するようにします。
コード構成
\<policynetwork>(root dir)
| setup.py
| train_policy.py
| kifulist_train.txt
| kifulist_test.txt
| kifulist_train_1000.txt
| kifulist_test_100.txt
|- <model>
| | model_policy
|
|- <pydlshogi>
| | common.py
| | features.py
| | read_kifu_.py
| |
| |- <network>
| | policy.py
|
|- <utils>
| | fileter_csa.py
| | make_kifu_list.py
| | plot_log.py
1.1 モジュールインストール
import setuptools
setuptools.setup(
name = 'python-dlshogi',
version = '0.0.1',
author = 'SudaDaisuke', # 名前
packages = ['pydlshogi'],
scripts = [],
)
スクリプトを別のスクリプトから、importできるように登録します。
プロジェクトのルートディレクトリで下のコマンドを打ちます。
pip install --no-cache-dir -e .
1.2 Policy Network
将棋の指し手を予測するための、ニューラルネットワークを構成します。
Alpha Goでは、打ち手を探索する「Policy Network」と局面を評価する「Value Network」という2つの深層ニューラルネットワークで構成されています。
将棋の指し手を予測するために、Alpha Goで採用された方法を改良して、13層の畳み込みニューラルネットワークを構成します。
ニューラルネットワークの仕様
| 項目 | 値 |
|---|---|
| フィルターサイズ | 3x3 |
| 中間層のフィルターサイズ | 192 |
| ストライド | 1 |
| パディング層 | 1 |
| ブーリング層 | 1 |
| 活性化関数 | ReLU |
1.3 Policy Network 実装
上の設計をもとに実装していきます。
pydlshogi\network\policy.py
from chainer import Chain
import chainer.functions as F
import chainer.links as L
from pydlshogi.common import *
ch = 192
class PolicyNetwork(Chain):
def __init__(self):
super(PolicyNetwork, self).__init__()
with self.init_scope():
self.l1=L.Convolution2D(in_channels = 104, out_channels = ch, ksize = 3, pad = 1)
self.l2=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l3=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l4=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l5=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l6=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l7=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l8=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l9=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l10=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l11=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l12=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l13=L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1, nobias = True)
self.l13_bias=L.Bias(shape=(9*9*MOVE_DIRECTION_LABEL_NUM))
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
h3 = F.relu(self.l3(h2))
h4 = F.relu(self.l4(h3))
h5 = F.relu(self.l5(h4))
h6 = F.relu(self.l6(h5))
h7 = F.relu(self.l7(h6))
h8 = F.relu(self.l8(h7))
h9 = F.relu(self.l9(h8))
h10 = F.relu(self.l10(h9))
h11 = F.relu(self.l11(h10))
h12 = F.relu(self.l12(h11))
h13 = self.l13(h12)
return self.l13_bias(F.reshape(h13, (-1, 9*9*MOVE_DIRECTION_LABEL_NUM)))
1.2 学習処理
1.2.1 実装
train_policy.py
import numpy as np
import chainer
from chainer import cuda, Variable
from chainer import optimizers, serializers
import chainer.functions as F
from pydlshogi.common import *
from pydlshogi.network.policy import PolicyNetwork
from pydlshogi.features import *
from pydlshogi.read_kifu import *
import argparse
import random
import pickle
import os
import re
import logging
parser = argparse.ArgumentParser()
parser.add_argument('kifulist_train', type=str, help='train kifu list')
parser.add_argument('kifulist_test', type=str, help='test kifu list')
parser.add_argument('--batchsize', '-b', type=int, default=32, help='Number of positions in each mini-batch')
parser.add_argument('--test_batchsize', type=int, default=512, help='Number of positions in each test mini-batch')
parser.add_argument('--epoch', '-e', type=int, default=1, help='Number of epoch times')
parser.add_argument('--model', type=str, default='model/model_policy', help='model file name')
parser.add_argument('--state', type=str, default='model/state_policy', help='state file name')
parser.add_argument('--initmodel', '-m', default='', help='Initialize the model from given file')
parser.add_argument('--resume', '-r', default='', help='Resume the optimization from snapshot')
parser.add_argument('--log', default=None, help='log file path')
parser.add_argument('--lr', type=float, default=0.01, help='learning rate')
parser.add_argument('--eval_interval', '-i', type=int, default=1000, help='eval interval')
args = parser.parse_args()
logging.basicConfig(format='%(asctime)s\t%(levelname)s\t%(message)s', datefmt='%Y/%m/%d %H:%M:%S', filename=args.log, level=logging.DEBUG)
model = PolicyNetwork()
model.to_gpu()
optimizer = optimizers.SGD(lr=args.lr)
optimizer.setup(model)
# Init/Resume
if args.initmodel:
logging.info('Load model from {}'.format(args.initmodel))
serializers.load_npz(args.initmodel, model)
if args.resume:
logging.info('Load optimizer state from {}'.format(args.resume))
serializers.load_npz(args.resume, optimizer)
logging.info('read kifu start')
# 保存済みのpickleファイルがある場合、pickleファイルを読み込む
# train date
train_pickle_filename = re.sub(r'\..*?$', '', args.kifulist_train) + '.pickle'
if os.path.exists(train_pickle_filename):
with open(train_pickle_filename, 'rb') as f:
positions_train = pickle.load(f)
logging.info('load train pickle')
else:
positions_train = read_kifu(args.kifulist_train)
# test data
test_pickle_filename = re.sub(r'\..*?$', '', args.kifulist_test) + '.pickle'
if os.path.exists(test_pickle_filename):
with open(test_pickle_filename, 'rb') as f:
positions_test = pickle.load(f)
logging.info('load test pickle')
else:
positions_test = read_kifu(args.kifulist_test)
# 保存済みのpickleがない場合、pickleファイルを保存する
if not os.path.exists(train_pickle_filename):
with open(train_pickle_filename, 'wb') as f:
pickle.dump(positions_train, f, pickle.HIGHEST_PROTOCOL)
logging.info('save train pickle')
if not os.path.exists(test_pickle_filename):
with open(test_pickle_filename, 'wb') as f:
pickle.dump(positions_test, f, pickle.HIGHEST_PROTOCOL)
logging.info('save test pickle')
logging.info('read kifu end')
logging.info('train position num = {}'.format(len(positions_train)))
logging.info('test position num = {}'.format(len(positions_test)))
# mini batch
def mini_batch(positions, i, batchsize):
mini_batch_data = []
mini_batch_move = []
for b in range(batchsize):
features, move, win = make_features(positions[i + b])
mini_batch_data.append(features)
mini_batch_move.append(move)
return (Variable(cuda.to_gpu(np.array(mini_batch_data, dtype=np.float32))),
Variable(cuda.to_gpu(np.array(mini_batch_move, dtype=np.int32))))
def mini_batch_for_test(positions, batchsize):
mini_batch_data = []
mini_batch_move = []
for b in range(batchsize):
features, move, win = make_features(random.choice(positions))
mini_batch_data.append(features)
mini_batch_move.append(move)
return (Variable(cuda.to_gpu(np.array(mini_batch_data, dtype=np.float32))),
Variable(cuda.to_gpu(np.array(mini_batch_move, dtype=np.int32))))
# train
logging.info('start training')
itr = 0
sum_loss = 0
for e in range(args.epoch):
positions_train_shuffled = random.sample(positions_train, len(positions_train))
itr_epoch = 0
sum_loss_epoch = 0
for i in range(0, len(positions_train_shuffled) - args.batchsize, args.batchsize):
x, t = mini_batch(positions_train_shuffled, i, args.batchsize)
y = model(x)
model.cleargrads()
loss = F.softmax_cross_entropy(y, t)
loss.backward()
optimizer.update()
itr += 1
sum_loss += loss.data
itr_epoch += 1
sum_loss_epoch += loss.data
# print train loss and test accuracy
if optimizer.t % args.eval_interval == 0:
x, t = mini_batch_for_test(positions_test, args.test_batchsize)
y = model(x)
logging.info('epoch = {}, iteration = {}, loss = {}, accuracy = {}'.format(optimizer.epoch + 1, optimizer.t, sum_loss / itr, F.accuracy(y, t).data))
itr = 0
sum_loss = 0
# validate test data
logging.info('validate test data')
itr_test = 0
sum_test_accuracy = 0
for i in range(0, len(positions_test) - args.batchsize, args.batchsize):
x, t = mini_batch(positions_test, i, args.batchsize)
y = model(x)
itr_test += 1
sum_test_accuracy += F.accuracy(y, t).data
logging.info('epoch = {}, iteration = {}, train loss avr = {}, test accuracy = {}'.format(optimizer.epoch + 1, optimizer.t, sum_loss_epoch / itr_epoch, sum_test_accuracy / itr_test))
optimizer.new_epoch()
logging.info('save the model')
serializers.save_npz(args.model, model)
logging.info('save the optimizer')
serializers.save_npz(args.state, optimizer)
上のコードは、学習部分を実装しています。
具体的に、
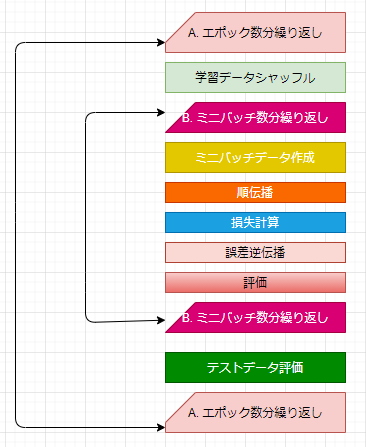
こんな感じに実装されています。
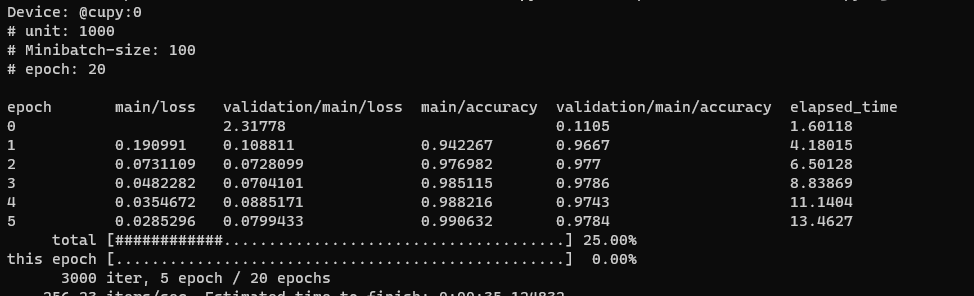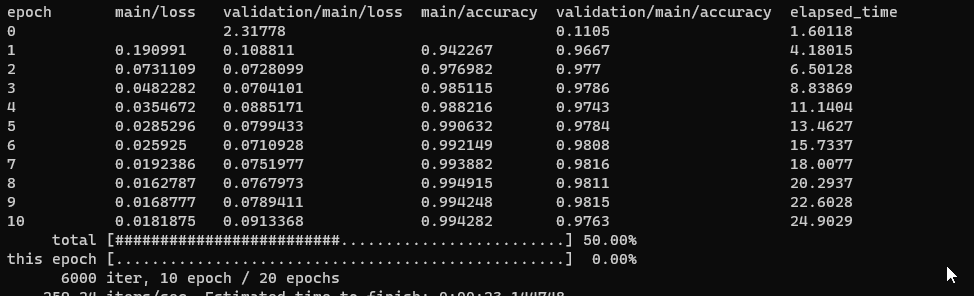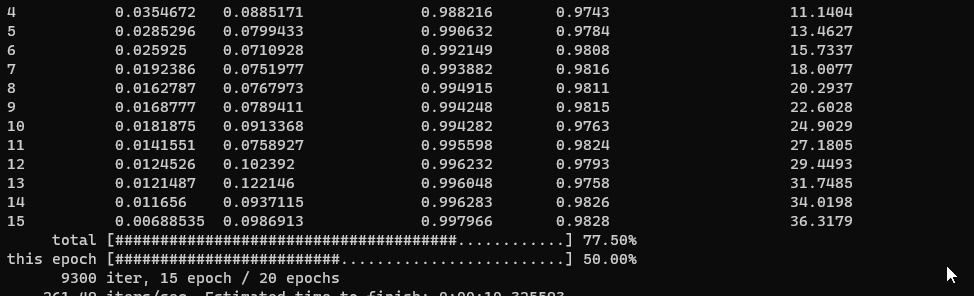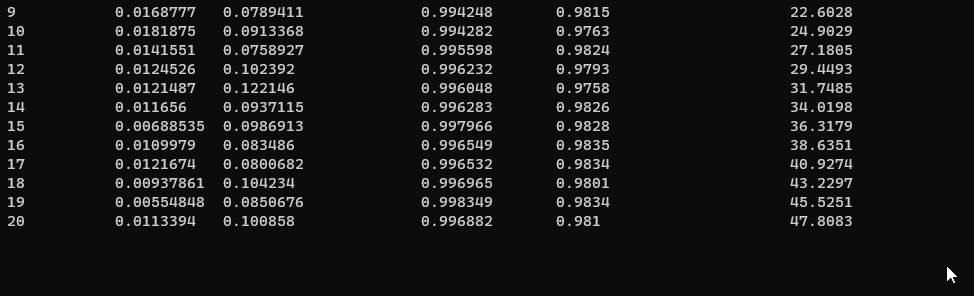
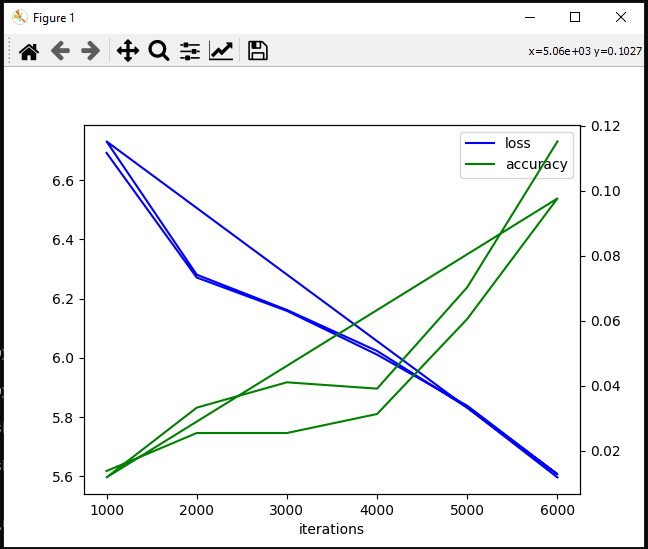
1.2.2 学習実行
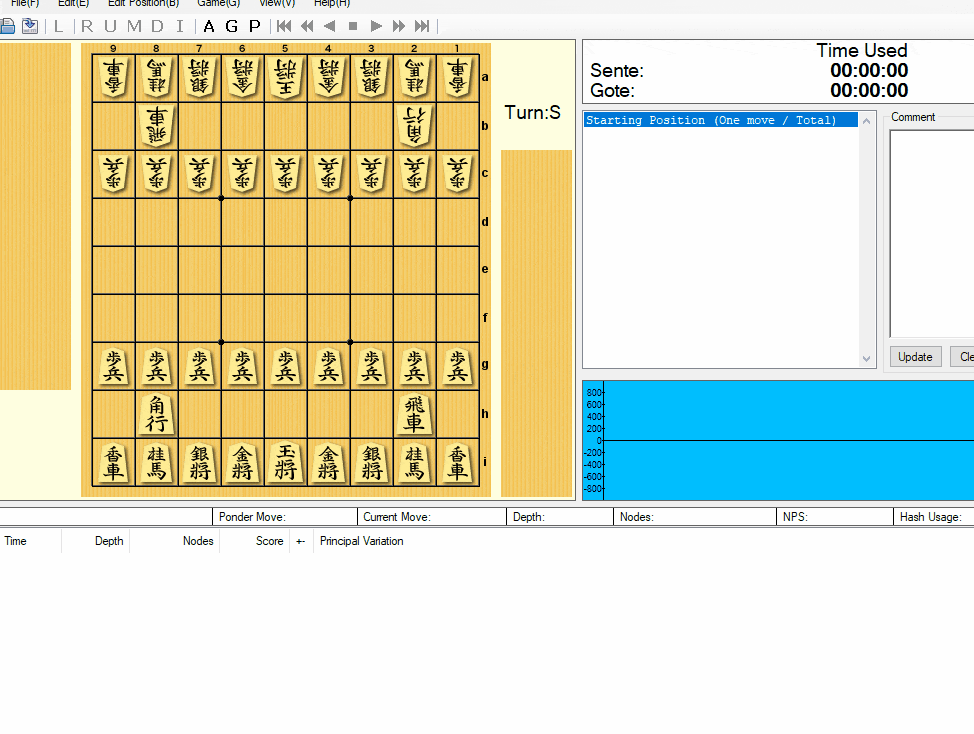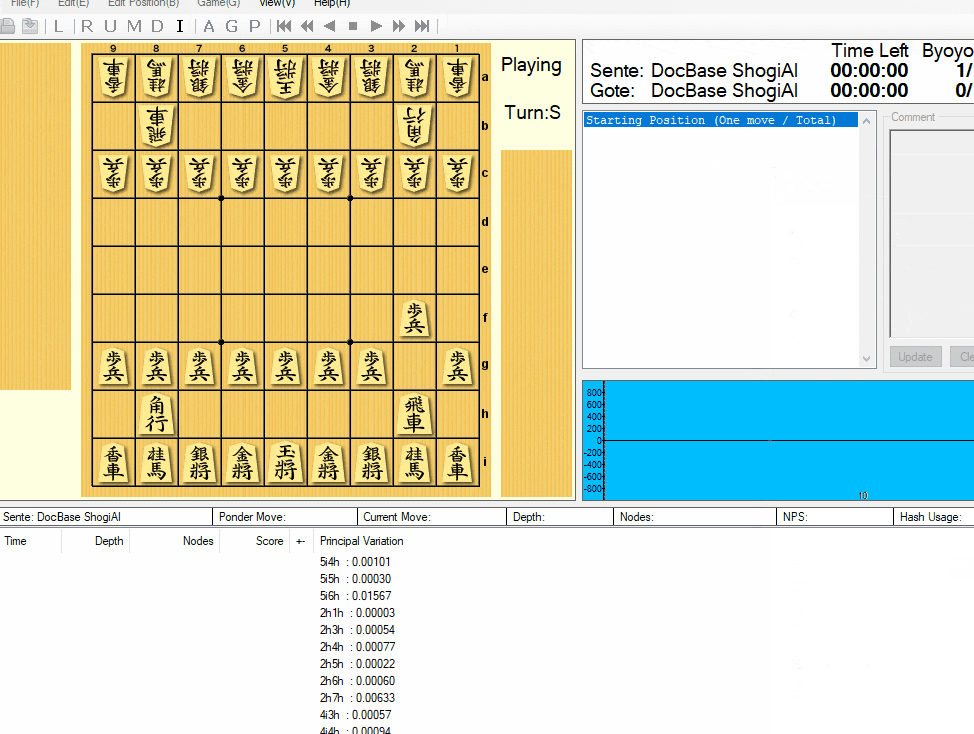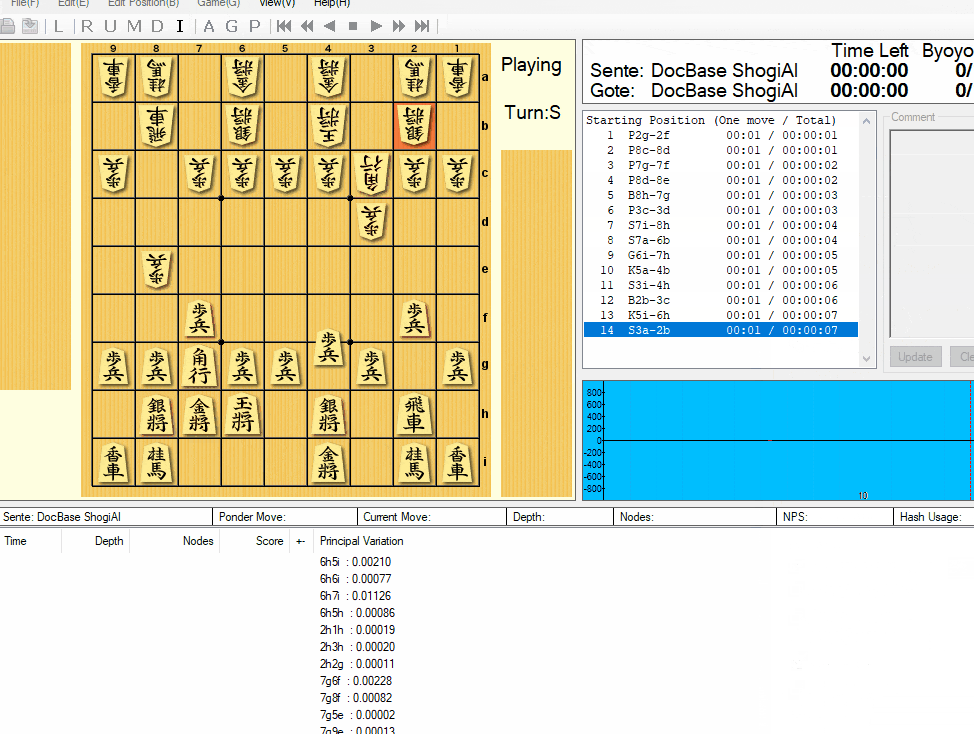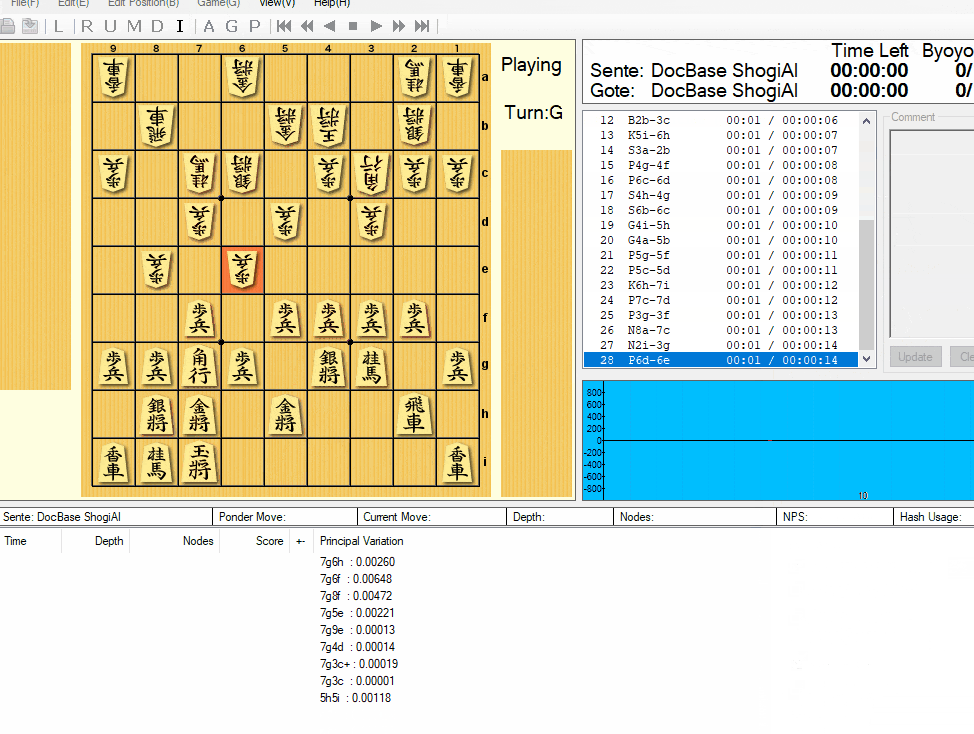
実際に学習を実行すると、こんな感じで、損失計算と、学習データから得られた結果との精度です。
§2. 将棋AI実装
ニューラルネットワークで、学習を終えたモデルを使って対局できるように、USIエンジンにします。
USI(Universal Shogi Interface)プロトコルとは、将棋GUIソフトと思考エンジンが通信をするために、Tord Romstad氏によって考案された通信プロトコルです。
http://shogidokoro.starfree.jp/usi.html
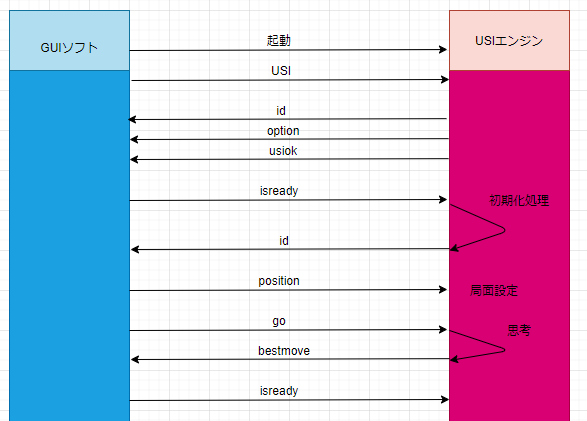
上のように、USIプロトコルをもとに通信することで、将棋AIをGUI上で動かします。
フォルダ構成
\<policynetwork>(root dir)
|- <bat>
| | Docbase.bat
|
|- <pydlshogi>
| |- <player>
| | base_player.py
| | Docbase_player.py
| |
| |- <usi>
| | usi.py
| | usi_Docbase_player.py
import numpy as np
import chainer
from chainer import serializers
from chainer import cuda, Variable
import chainer.functions as F
import shogi
from pydlshogi.common import *
from pydlshogi.features import *
from pydlshogi.network.policy import *
from pydlshogi.player.base_player import *
def greedy(logits):
return logits.index(max(logits))
def boltzmann(logits, temperature):
logits /= temperature
logits -= logits.max()
probabilities = np.exp(logits)
probabilities /= probabilities.sum()
return np.random.choice(len(logits), p=probabilities)
class PolicyPlayer(BasePlayer):
def __init__(self):
super().__init__()
self.modelfile = r'学習したモデルのパス'
self.model = None
def usi(self):
print('id name DocBase ShogiAI')
print('option name modelfile type string default ' + self.modelfile)
print('usiok')
def setoption(self, option):
if option[1] == 'modelfile':
self.modelfile = option[3]
def isready(self):
if self.model is None:
self.model = PolicyNetwork()
self.model.to_gpu()
serializers.load_npz(self.modelfile, self.model)
print('readyok')
def go(self):
if self.board.is_game_over():
print('bestmove resign')
return
features = make_input_features_from_board(self.board)
x = Variable(cuda.to_gpu(np.array([features], dtype=np.float32)))
with chainer.no_backprop_mode():
y = self.model(x)
logits = cuda.to_cpu(y.data)[0]
probabilities = cuda.to_cpu(F.softmax(y).data)[0]
# 全ての合法手について
legal_moves = []
legal_logits = []
for move in self.board.legal_moves:
# ラベルに変換
label = make_output_label(move, self.board.turn)
# 合法手とその指し手の確率(logits)を格納
legal_moves.append(move)
legal_logits.append(logits[label])
# 確率を表示
print('info string {:5} : {:.5f}'.format(move.usi(), probabilities[label]))
# 確率が最大の手を選ぶ(グリーディー戦略)
selected_index = greedy(legal_logits)
# 確率に応じて手を選ぶ(ソフトマックス戦略)
selected_index = boltzmann(np.array(legal_logits, dtype=np.float32), 0.5)
bestmove = legal_moves[selected_index]
print('bestmove', bestmove.usi())
上のように、AIの情報や局面ごとの最善手を計算していきます。
§3. GUIソフトで動かす
上で作ったモデルと実際に対局します。
GUIソフトはいくつかありますが、将棋所を使用します。

上のように、登録することができます。
§4. 参考
| 参考 | URL |
|---|---|
| 将棋AIで学ぶディープラーニング | https://book.mynavi.jp/ec/products/detail/id=88752 |
| Alpha Goの論文 | https://www.nature.com/articles/nature16961 |
§5. 終わりに
いかがでしょうか?
私は、ボードゲームが趣味で将棋、囲碁、チェス等ももちろん好きです。
チェスは、1997年に、当時のチャンピオン Гaрри Каспaров さんが、IBM社のディープブルーに敗れました。
私がまだ生まれていない時代から、AI vs 人間の戦いが始まっていたことを知ったときは、驚愕しました。
そして、あと10年は人間に勝てないといわれていた、囲碁も2016年に李 世乭 さんが、Google傘下のDemis Hassabis さんが率いるDeepMind社のAlpha Goに敗れました。
今回の、将棋AIもAlpha Goを参考にしています。
そして、将棋も2010年代からずっと、Bonanzaといわれる将棋ソフトの強さは注目されていました。
Bonanzaには、モンテカルロ法が採用されていました。
当時から、将棋プロでさえ、Bonanzaを一目おいていて、当時の竜王である渡辺明さんとBonanzaの公開対局が催されたりしました。(渡辺明竜王(当時)の逆転勝ち)
2016年,Alpha Goの論文が公開されると、すぐにAlpha Zeroと呼ばれる将棋AIが誕生しました。
現在の、将棋界は藤井聡太2冠をはじめとして、若年世代を筆頭に、世代を問わず将棋AIを用いた研究が盛んになっています。
コンピュータ将棋大会も、開かれていて、将棋AIの強さを競う大会もあります。
ぜひ、AI、機械学習等に興味を持ってもらえると嬉しいです。