はじめの前のおねがい
できれば「いいね♡」をお願いします。励みになります。
はじめに
言語学をやっていると避けて通れないのが樹形図(句構造木)作りです。樹形図を作成する方法としては、PowerPoint(もしくはKeynote)を使用したり、AdobeのIllustratorやInDesignを作成するというのが手っ取り早い方法ですが、よほどバランス感覚が優れていなければ、やはりLaTeXを使わざるを得ません。というのもLaTeXにはforestパッケージという非常に強力な樹形図作成ツールが存在しているからです。
とはいえ、forestの記法は非常に面倒です。[と]をひたすらネストさせて、
ベタ打ち (1)
\begin{forest}
wherenchildren=0{tier=word}{}
[VP[DP[John]][V’[V[sent]][DP[Mary]][DP[D[a]][NP[letter]]]]]
\end{forest}
みたいに記述しなければいけないわけで、公式ドキュメントでも
タブ挿入 (2)
\begin{forest}
wherenchildren=0{tier=word}{}
[VP
[DP
[John]
]
[V’
[V
[sent]
]
[DP
[D
[a]
]
[NP
[letter]
]
]
]
]
\end{forest}
のように適宜タブを使用して記述することが推奨というか対応されていて、そうでなければ分かりにくくなってしまいます。
しかし、いちいち[と]をひたすらネストさせることは変わらないわけで、書いているうちにわけが分からなくなります。
そのようなこともあり、「オフサイドルール」つまりタブによる階層のみでツリーの深度を表現して、より可視性を高めたいと考えました。
つまり
オフサイドルール (3)
VP
DP
John
V’
V
sent
DP
Mary
DP
D
a
NP
letter
と打ち込めば、それをforestパッケージ用に変換してくれるコードがあれば、便利なのではないかと考えました。
導入方法
LaTeXのforestパッケージ
LaTeXのforestパッケージのインストールに関しては、長くなってしまうので省かせていただきたく思います……こちらをご参照ください。
Pythonの必要なモジュール
Pythonに関して必要なモジュールは“json”と“pyperclip”のみです。
json
pip install json
pyperclip
pip install pyperclip
手順
- 下記のソースコードを保存
- オフサイドルールで記述されたテキストをクリップボードにコピー
- ソースコードを実行
- forest形式に整形されたテキストがクリップボードに再コピーされる
- LaTeXの
\begin{forest}と\end{forest}の間にペースト - タイプセット
ソースコード
Tab_Forest_Converter.py
import json
import pyperclip
# 基幹クラス
class TreeConverter:
def __init__(self, tree_str):
self.tree_str = tree_str
# クリップボード内をインデントルールに従ってJSON形式の階層化
def convert_to_json(self):
lines = self.tree_str.strip().split('\n')
tree_json = {}
stack = [tree_json]
for line in lines:
indent_level = len(line) - len(line.lstrip('\t'))
node = line.strip()
while len(stack) > indent_level + 1:
stack.pop()
current_dict = stack[-1]
current_dict[node] = {}
stack.append(current_dict[node])
return tree_json
# JSON形式からLaTeXのforest形式に変換
def json_to_forest(self, tree_json):
root_node = list(tree_json.keys())[0]
forest_str = '[{}\n'.format(root_node)
def traverse(node, indent_level=0):
nonlocal forest_str
for key, value in node.items():
forest_str += '\t' * (indent_level + 1) + '[' + key
if value:
forest_str += '\n'
traverse(value, indent_level + 1)
forest_str += '\t' * (indent_level + 1)
forest_str += ']\n'
traverse(tree_json[root_node])
forest_str += ']'
return forest_str
# 本処理
def convert(self):
tree_json = self.convert_to_json()
forest_str = self.json_to_forest(tree_json)
return forest_str
# クリップボードの内容を取得
tree_str = pyperclip.paste()
# 変換
converter = TreeConverter(tree_str)
forest_output = converter.convert()
# 出力
pyperclip.copy(forest_output)
print(forest_output)
例
挿入用LaTeXサンプル
sample.tex (1)
\documentclass[dvipdfmx,uplatex]{jarticle}
\usepackage{forest}
\useforestlibrary{linguistics}
\begin{document}
\begin{forest}
% “,tier=word”を単語の末尾につけることで同列化が可能。
sn edges % 三角形状に閉じた線を引くときにはこれを宣言。開いた線を引くときは%でコメントアウト
% ここの部分に挿入。なおforest環境は空行がある場合はエラーが出力するので注意!
\end{forest}
\end{document}
クリップボードにコピーするテキスト
クリップボードにコピーするテキスト(2)
VP
DP
John
V’
V
sent
DP
Mary
DP
D
a
NP
letter
コード実行後のテキスト
コード実行後のテキスト(3)
[VP
[DP
[John]
]
[V’
[V
[sent]
]
[DP
[D
[a]
]
[NP
[letter]
]
]
]
]
挿入後LaTeXサンプル
sample.tex (4)
\documentclass[dvipdfmx,uplatex]{jarticle}
\usepackage{forest}
\useforestlibrary{linguistics}
\begin{document}
\begin{forest}
%“,tier=word”を単語の末尾につけることで同列化が可能。
sn edges
[VP
[DP
[John]
]
[V’
[V
[sent]
]
[DP
[D
[a]
]
[NP
[letter]
]
]
]
]
\end{forest}
\end{document}
結果1
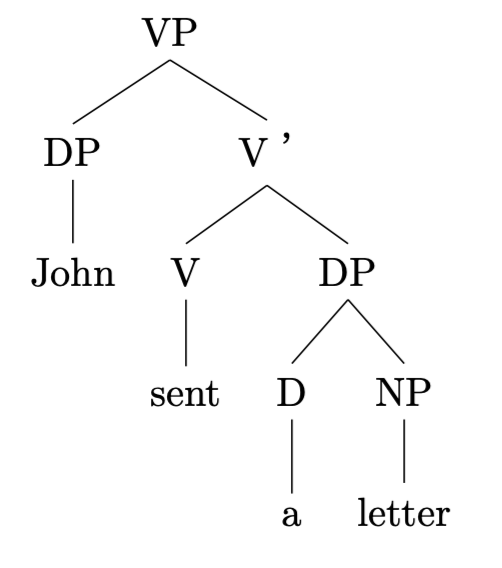
その後、手打ちで,tier=wordを単語の末尾にペーストした例。
sample.tex (5)
\documentclass[dvipdfmx,uplatex]{jarticle}
\usepackage{forest}
\useforestlibrary{linguistics}
\usepackage{cancel}
\usepackage{pxrubrica}
\begin{document}
\begin{forest}
%“,tier=word”を単語の末尾につけることで同列化が可能。
sn edges
[VP
[DP
[John,tier=word]
]
[V’
[V
[sent,tier=word]
]
[DP
[D
[a,tier=word]
]
[NP
[letter,tier=word]
]
]
]
]
\end{forest}
\end{document}
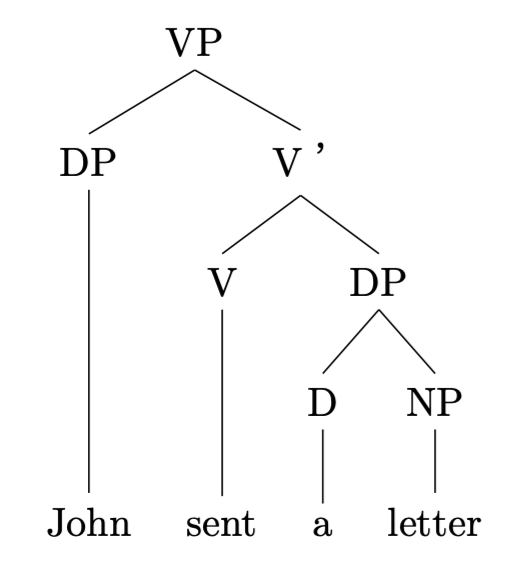
以上です。