CPUの製作もいよいよゴールが近づいてきた。残る主要な部品は命令デコーダ(instruction decorder)のみ。その前にCPUの全体構造を確認しておきたい。そうすれば命令デコーダをどう作ればいいかがよく分かると思う。その次に命令デコーダを考えよう。
CPUのブロック図と命令デコーダ
CPU(TD4)を入力、処理、出力に分けて考えると次のようなブロック図になると思う。
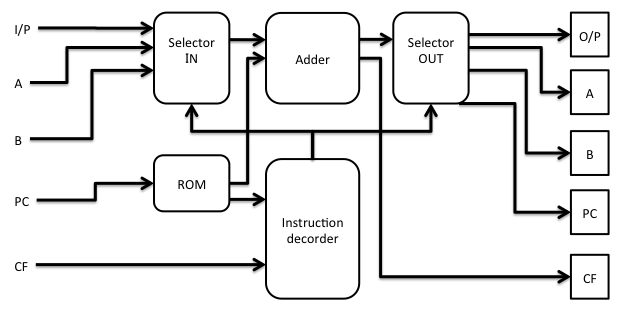
この図では、入力値(入力ポート(I/P)、A,Bレジスタ、直値)は加算器(adder)に入り、結果は全て加算器から出てきて出力ポート(O/P)やレジスタのいずれかへ書き込まれるような構成になっている。前回作った加算器では、入力は二つの4 bit値、出力は一つの4 bit値とcarryフラグだった。ということは、加算器に入れる値をいくつかの候補から選択する必要がある。それが図のSelector INだ。一方、加算結果を書き出す先も選択する必要があるが、これはSelector OUTの仕事だ。
では、どれを足してどこに結果を書くかはどう決まるのかというと、もちろん命令(operation code)で決まるわけだ。ここまでくると命令デコーダのやっていることが見えてくる。このCPU(TD4)においては、「命令を解釈して、どの値を足して、どこへ書き出すかを決める」ということをやっているわけだ。ROMから命令デコーダへ入っている矢印が「命令」を、命令デコーダからSelector IN/OUTへ伸びている矢印がどれを選択するかを表す情報というわけだ。
すべては足し算
さて、上記の図と説明を見て「あれ?」と思っただろうか?そう、TD4の構造では全ての命令(処理)は加算器を通る。それはつまり「足し算しかできない」ということだ。しかしCPUの処理というものは、代入とかポートの入出力とか、ジャンプとかいろいろあるわけで、それはどこへ行ったんだ、となる。
これについては例の本(CPUの創りかた)を読むとよくわかる。一見全く別の命令に見えたものが、実は「全部足し算で表現できる」のだ。次の表を参照してほしい。これは命令コード(opcode)とニーモニック、それに対応する足し算を並べたものだ。
| opcode | mnemonic | equation |
|---|---|---|
| 0000xxxx | ADD A,Im | A ← A + Im |
| 00010000 | MOV A,B | A ← B + 0000 |
| 00100000 | IN A | A ← I/P + 0000 |
| 0011xxxx | MOV A,Im | A ← 0000 + Im |
| 01000000 | MOV B,A | B ← A + 0000 |
| 0101xxxx | ADD B,Im | B ← B + Im |
| 01100000 | IN B | B ← I/P + 0000 |
| 0111xxxx | MOV B,Im | B ← 0000 + Im |
| 10010000 | OUT B | O/P ← B + 0000 |
| 1011xxxx | OUT Im | O/P ← 0000 + Im |
| 1110xxxx | JNC Im | PC ← 0000 + Im (cf=0) |
| 1111xxxx | JMP Im | PC ← 0000 + Im |
確かに全部足し算で表現できている!恥ずかしながら、今までCPUの内部でこういう処理をしているとは知らなかった。。。代入は足し算を使って(片方を0にして)実現しており、出力ポートへの書き出しとは書き込む先がポートになっている、ただの代入だ。ジャンプは飛び先アドレスをPCへ代入しているだけだ。
式中のプラス記号の左と右を比べてほしい。プラス記号の左側はSelector INから来るもの、右側はROMから直接入ってくるものだ。左側には図に書かれていない'0000'もある。これも実際に作るときにはSelector INの入力の一つとしてつくり込む必要がある。一方、右側は直値(Im)か0だ。それをどうやって使い分けているか、は簡単だ。命令コードの下4 bitがそれで、0を入れる時は命令コードの下4 bitが0なのだ。
もちろん一般のCPUはもっと複雑な構造をしているので、こんな単純に全部足し算で処理しているのではなく、ALU内で複雑な処理をしているのだろう。とはいえそれも、加算器とか乗算器とか、論理演算などを処理する部分にどういったものを入力するか、それらから出てくる結果をどこへ書き出すかを命令デコーダが選択すればよいのだろうから、大差無いだろう。
「命令を解釈する」と言われると、なんとなく神秘的でとても高度なことをしているというイメージがあったのだが。今回の製作でその辺のカラクリが見えたのは収穫だ。(知っている人にとっては当たり前すぎて、バカバカしいと思われるだろうが)
命令デコーダ
では、最後の大物(?)にとりかかろう。先述の通り、このCPUの命令デコーダは「命令を解釈してSelector IN/OUTを適切に制御する」ものだ。ではSelectr IN/OUTは何者かということになる。まあ本に書いてあることだが、
- Selector IN: 4chマルチプレクサを4 bit分並べたもの。一つのマルチプレクサで1 bit分が選択できるので4つ必要。
- Selector OUT: どのレジスタやポート(実体はFlip Flop)の
Loadを有効にするかを指定する。実体があるわけではなく命令デコーダの一部と言える。(わかりやすくするためSelector OUTと表現しているが)
ということだ。結局命令デコーダは、Selector IN/OUTに必要な「選択するための情報」を作り出せばいいのだ。
さて、命令デコーダの入力は命令コード(上4 bit、OP0-OP3)とcarryフラグ(CF)だ。Select INへは(SA、SBの)2 bit、4種類の情報を与えてやれば良い。Selector OUTについては、4つある出力先(Flip Flop)のどれか一つの'Load'を有効に、それ以外を無効にする必要があるので、4 bitの情報で表す(LD0-LD3)。まとめると、入力は5 bit(OP0-OP3,CF)、出力が6 bit(SA,SB,LD0-LD3)だ。
SA,SBの値と、選択される入力値の対応は下表のとおり。
| SA | SB | input |
|---|---|---|
| 0 | 0 | A register |
| 1 | 0 | B register |
| 0 | 1 | input port |
| 1 | 1 | value '0000' |
LD0-LD3と出力先の対応は下表のとおり。
| LOAD | output |
|---|---|
| LD0 | A register |
| LD1 | B register |
| LD2 | output port |
| LD3 | program counter |
これらを踏まえ入出力を真理値表にまとめたものがp.242にある。さらにカルノー図などで分析した結果、各出力は次のように表現できる。
$
S_A = OP_0 + OP_3
$
$
S_B = OP_1
$
$
LD_0 = OP_2 + OP_3
$
$
LD_1 = \overline{OP_2} + OP_3
$
$
LD_2 = OP_2 + \overline{OP_3}
$
$
LD_3 = \overline{OP_2} + \overline{OP_3} + \overline{OP_0} \cdot CF
$
非常に簡潔になった、素晴らしい。もちろん偶然ではなく、この本の著者はこういう単純な回路になるように綿密に考えて、命令コードを割り振っているわけだ。ここまでくればコードに落とすのは簡単だ。
{- |
instruction decorder
IN : [OP0,OP1,OP2,OP3,CF]
OUT: [SA,SB,LD0,LD1,LD2,LD3]
OPn: operation code (upper 4 bit)
CF : carry flag
SA : Select A
SB : Select B
LDn: LOAD0 - LOAD3
-}
lc_inst_decorder :: LogicCircuit
lc_inst_decorder (op0:op1:op2:op3:c:_) = [sa, sb, l0, l1, l2, l3]
where
sa = op0 |> op3
sb = op1
nop0 = (!>) op0
nop2 = (!>) op2
nop3 = (!>) op3
l0 = op2 |> op3
l1 = nop2 |> op3
l2 = op2 |> nop3
l3 = nop2 |> nop3 |> (nop0 &> c)
なんと命令デコーダの小さいことか!わずか12行だ!
各opcodeについてテストを書いてみる。
>>> toStr $ lc_inst_decorder $ toBits "00000" -- ADD A,Im
"000111"
>>> toStr $ lc_inst_decorder $ toBits "10000" -- MOV A,B
"100111"
>>> toStr $ lc_inst_decorder $ toBits "01000" -- IN A
"010111"
>>> toStr $ lc_inst_decorder $ toBits "11000" -- MOV A,Im
"110111"
>>> toStr $ lc_inst_decorder $ toBits "00100" -- MOV B,A
"001011"
>>> toStr $ lc_inst_decorder $ toBits "10100" -- ADD B,Im
"101011"
>>> toStr $ lc_inst_decorder $ toBits "01100" -- IN B
"011011"
>>> toStr $ lc_inst_decorder $ toBits "11100" -- MOV B,Im
"111011"
>>> toStr $ lc_inst_decorder $ toBits "10010" -- OUT B
"101101"
>>> toStr $ lc_inst_decorder $ toBits "11010" -- OUT Im
"111101"
>>> toStr $ lc_inst_decorder $ toBits "01110" -- JNC(C=0) Im
"111110"
>>> toStr $ lc_inst_decorder $ toBits "01111" -- JNC(C=1) Im
"111111"
>>> toStr $ lc_inst_decorder $ toBits "11110" -- JMP Im
"111110"
ちゃんとテストも全部通る。これは嬉しい。(本の真理値表とはビット順序がいくらか違っているので混乱しないように)
さあ、部品が出揃った!いよいよCPUとして全体を組み上げる頃合いだ!が、続きは次回。
まとめ
今回は最後の重要なモジュールである命令デコーダを作った。次回はCPUを組み上げて簡単な命令の実行を試そう。うまく動くかな?
(ここまでのソース)