目的
anacondaの仮想環境内でtesseractとPyOCRを使い、画像から文字を認識できるようにします。
今回は画像の文字を認識し、ターミナルへ出力できるところまでの行います。
こんな感じ↓
環境
python 3.6
tesseract 4.1.1
PyOCR 0.8
手順
ツールのインストール
anacondaの仮想環境に下記2つをインストールします。
・文字認識のためのOCRエンジンであるTesseract OCRをインストール
https://anaconda.org/conda-forge/tesseract
conda install -c conda-forge tesseract
・PythonからOCRエンジンを使用するためのPyOCRをインストール
https://anaconda.org/conda-forge/pyocr
conda install -c conda-forge pyocr
文字認識を試す
確認用にテスト用の画像を準備します(ファイル名はmoji_en.pngとしています)。
※デフォルトは日本語未対応です。

pythonコードは以下になります。
from PIL import Image
import pyocr
# OCRエンジンを取得
engines = pyocr.get_available_tools()
engine = engines[0]
# 画像の文字を読み込む
txt = engine.image_to_string(Image.open('moji_en.png'), lang="eng")
print(txt) # 「Test Message」が出力される
実行結果に画像内のテキストが出力されていればOKです。
日本語対応化
次に、日本語も認識できるようにします。
下記から言語ファイルjpn.traineddataダウンロードします。
https://github.com/tesseract-ocr/tessdata
ダウンロードした言語ファイルをanacondaの仮想環境にある指定の場所へ配置してください。
配置先:C:\Users\user\anaconda3\envs\<仮想環境名>\Library\bin\tessdata\
言語ファイルを配置したら、pythonコードのengine.image_to_string()の第2引数をlang="jpn"のように修正します。
ついでに対応言語も出力しておきます。
from PIL import Image
import pyocr
# OCRエンジンを取得
engines = pyocr.get_available_tools()
engine = engines[0]
# 対応言語取得
langs = engine.get_available_languages()
print("対応言語:",langs) # ['eng', 'jpn', 'osd']
# 画像の文字を読み込む
txt = engine.image_to_string(Image.open('jugemu.png'), lang="jpn") # 修正点:lang="eng" -> lang="jpn"
print(txt)
これで日本語化は完了です。
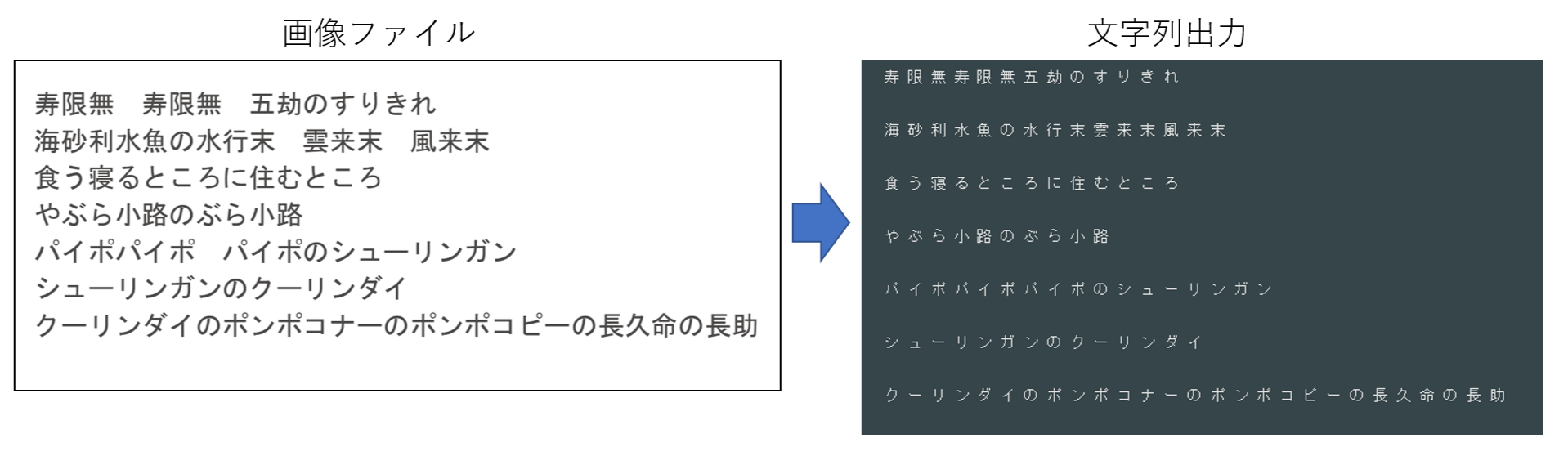
動作確認してみましょう。使う画像はみんな大好き寿限無です。

対応言語: ['eng', 'jpn', 'osd']
寿 限 無 寿 限 無 五 劫 の す り き れ
海 砂 利 水 魚 の 水 行 末 雲 来 末 風 来 末
食 う 寝 る と こ ろ に 住 む と こ ろ
や ぶ ら 小 路 の ぶ ら 小 路
パ イ ポ パ イ ポ パ イ ポ の シ ュ ー リ ン ガ ン
シ ュ ー リ ン ガ ン の ク ー リ ン ダ イ
ク ー リ ン ダ イ の ポ ン ポ コ ナ ー の ポ ン ポ コ ピ ー の 長 久 命 の 長 助
対応言語にjpnが含まれており、出力も問題なさそうですね。
ちなみにosdは文字の識別を行うための特殊ファイルみたいなものです。
まとめ
pythonのツールと数行のコードだけで画像から文字を認識することが出来ました。
日本語対応なども一度設定してしまえばOKなので、低コストでここまで出来るのは素晴らしいです。
データ入力の自動化など、様々なことに応用できそうですね。