はじめに
記事を修正しました(2020年3月10日)
記事を修正しました(2020年5月4日)
この記事では、以下についてまとめています。
- Flickr APIを利用して画像を収集する
- その画像をVGG16の転移学習によって学習、判別させる
ちなみに、私は機械学習初学者であるため、不適切な表現をしている場合があるかもしれません。その際はどうぞお手数をおかけしますがご指摘頂けると幸甚です。
実行環境は下記になります。
- python 3.7.4
- tensorflow 2.1.0
- matplotlib 3.1.1
- numpy 1.16.5
- opencv 3.4.2
参考にさせて頂いたURLは下記一覧となります。
https://qiita.com/ayumiya/items/e1e87df54c41519be6b4
画像を収集する
今回flickr APIを利用して大量の画像を収集しました。こちらに関しては、下記URLを参考にflickrの登録・API, secret KEYの発行などを行うことで画像を収集させました。
http://ykubot.com/2017/11/05/flickr-api/
収集に関してもpython上で下記プログラムを実行することで自動で画像を集めることができました。300枚収集するのに必要な時間は凡そ今回のケースだと5分程度でした。
下記がプログラム全文になります。
import os
import time
import traceback
import flickrapi
from urllib.request import urlretrieve
import sys
from retry import retry
flickr_api_key = "xxxx" #ここに発行されたAPI KEYを入力
secret_key = "xxxx" #ここに発行されたSECRET KEYを入力
keyword = sys.argv[1]
@retry()
def get_photos(url, filepath):
urlretrieve(url, filepath)
time.sleep(1)
if __name__ == '__main__':
flicker = flickrapi.FlickrAPI(flickr_api_key, secret_key, format='parsed-json')
response = flicker.photos.search(
text='child',#検索したいワードを入力
per_page=300,#何枚収集したいか指定
media='photos',
sort='relevance',
safe_search=1,
extras='url_q,license'
)
photos = response['photos']
try:
if not os.path.exists('./image-data/' + 'child'):
os.mkdir('./image-data/' +'child')
for photo in photos['photo']:
url_q = photo['url_q']
filepath = './image-data/' + 'child' + '/' + photo['id'] + '.jpg'
get_photos(url_q, filepath)
except Exception as e:
traceback.print_exc()
今回、「子供:child」と「老人:elder」を認識すべくそれら画像を300枚ずつ収集しました。
後にも述べますが検索ワードelderは、老人だけでなく植物、若い女性等の画像も収集されたため、それにより認識率が高くなかったものと推定しています。
画像認識プログラムの作成
以下記事にて、画像認識プログラムについて説明します。全体像から私がつまづいてしまったところや、注意すべきポイントに絞って抜粋し、そののちにプログラム全文を記載します。
インポートしたライブラリ、モジュール等
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from keras.utils.np_utils import to_categorical
from keras.layers import Dense, Dropout, Flatten, Input
from keras.applications.vgg16 import VGG16
from keras.models import Model, Sequential
from keras import optimizers
モデル関数を作るうえでの注意
model = Model(input=vgg16.input, output=top_model(vgg16.output))
元々、仕様環境はtensorflowをインストールしており、その中のライブラリであるkerasとして、引用していました。
例:from tensorflow.keras.utils import to_categorical
このまま進めるていると、このModel関数を定義するうえで、
('Keyword argument not understood:', 'input')
となるエラーが発生しました。
これはどうもkerasのversionが古いと起こるとのことで、
keras自体のアップデートなども行ったのですが、エラーは出続けました。
従い、keras自体を読み込む書き方をしてみたら、解決しました。
本エラー概要及び、keras自体のアップデート
https://sugiyamayoshiaki.jp/%E3%80%90%E3%82%A8%E3%83%A9%E3%83%BC%E3%80%91typeerror-keyword-argument-not-understood-data_format/
VGG16モデルの概要
今回使用したモデルはVGG16と呼ばれる多層パーセプトロンを元にした学習済みモデルです。
URL:https://arxiv.org/pdf/1409.1556.pdf
作者:Karen Simonyan & Andrew Zisserman
Visual Geometry Group, Department of Engineering Science, University of Oxford
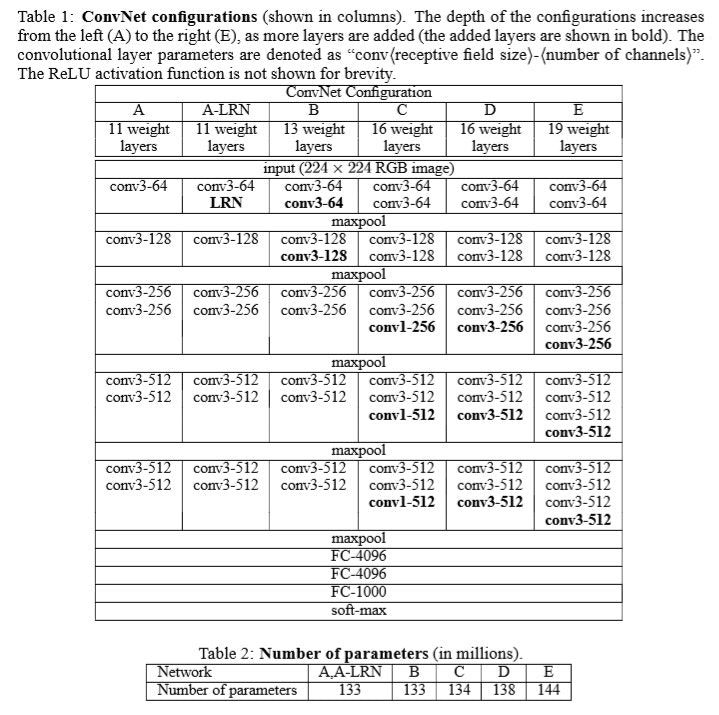
上記画像のDが今回扱うモデルになります。カーネルサイズが3次元である畳み込み13層と全結合層が3層あるニューラルネットワークになります。2015年に発表されたアルゴリズムになりますが、それ以前はカーネルサイズが9や11次元などと非常に大きいサイズであったため、計算負荷が高いものの判別率が低い課題がありました。
そこで、カーネルサイズを3へ小さくして層を深く(13層)させることでこの課題を解決した手法が今回のVGG16になります。
さらにこのモデルのポイントとしては、ImageNetという画像サイトにて大量の画像認識の学習を行った重みづけされたモデルを参照できることです。それによって1000種類の項目として見分けることができます。従って、使い方としては二つあります。
一つは、この学習を行った重みモデルをそのまま使って1000種類の中から一番近いものを探す方法です。二つ目は重みは使わずモデル自体を使って新しく学習させる方法です。今回はこの二つ目の方法を使って子供と老人の見分けをさせたいと思います。
このモデルの中身を見てみます。
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________
**Output shape(次元)を見ると、(None, 244, 244, 3)となっています。これは、(サンプル枚数、縦解像度、横解像度、チャンネル数(≒次元数カラーであればRGB))**を表しています。この値を見ると、畳み込み層の通過後は次元数が64→128→256→512と増えていることが分かります。
転移学習用に修正
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
子供と老人の二種類に分けるためにVGG16層の後に追加をします。
子供か老人かを判別する関数を作る
def child(img):
img = cv2.resize(img, (50, 50))
pred = np.argmax(model.predict(np.array([img])))
if pred == 0:
return 'これは子供です'
else:
return 'これは老人です'
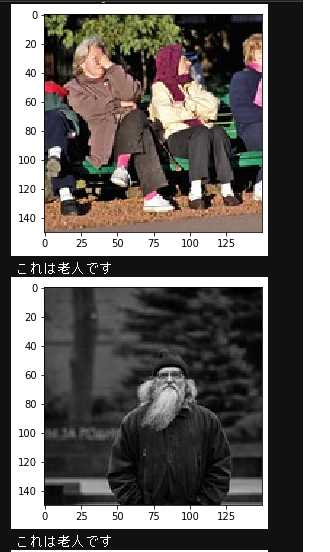
結果、あまり正答率はよくありませんでした。これは、flickrで老人(elder)と探すと老人以外の写真がヒットするため、学習が上手くいっていないものと思います。
下記写真は一例で当たってる場合です。
おわりに
VGG16などの既に学習済のモデルを用いる場合は、その学習された内容を上手く活用できるデータセットを用いることが有効です。
先人の肩にしっかり乗って活用できると良いですね。
プログラム全文は下記に格納しています。
https://github.com/Fumio-eisan/vgg16_child20200310