はじめに
「for ループを行列の計算に直せば速くなる」
MATLAB を使ったことがある方は一度は聞いたことがあると思います。最近 @t--shin さんが投稿された記事(MatlabやPythonのループは遅いって聞くけど本当?)でも for ループを使わないほうが処理が速いとの結果が報告されています。
ただ、R2015b から JIT (Just-in-Time) コンパイル機能(公式ページ)が刷新されたこともあり状況が変わりつつあります。
どれくらい違いがあるかのかな?と @t--shin さんの記事の勝手な補足として、バージョンによる違いをまとめてみました。計算内容は MatlabやPythonのループは遅いって聞くけど本当? を確認ください。
2020/10/16 追記
本記事で使用している例はベクトル化に不利な条件であり誤解を招いているとのご指摘を頂きました。指摘の通りで "ベクトル化は for 文より遅い" という点ではなく、最近 for ループが速く実行できるようになっているという点をお伝えする内容である点ご留意ください。FDTDの式はconv2やimfilterで書いた方が良さそうです。参照:https://twitter.com/yatabe_/status/1316911716236742656
追記終わり
やったこと
コードは最後 Appendix に纏めましたが、@t--shin さんの波動方程式の差分解法のコードを少しだけ改変して、差分の評価に for ループを使った場合とベクトル化した場合で処理時間を以下のバージョンで調査しました。Windows 10 Intel(R) Core(TM) i7-8650U CPU @ 1.90GHz です。
- R2015a
- R2015b
- R2017b
- R2019b
- R2020b(執筆時点での最新版)
こちらが一例ですが・・
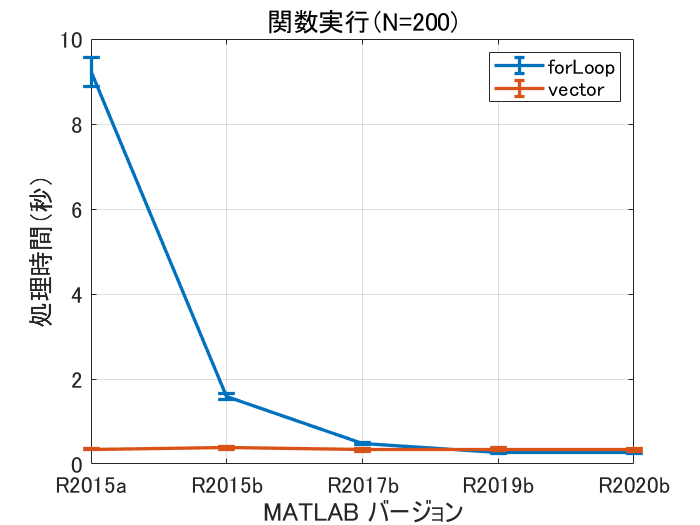
いや、最後の方 for ループの方が速いがな!
R2015a -> R2020b で 34 倍。
R2015a 以降 for ループを使った場合の処理時間がかなり高速化され、このケースだとR2019b の時点で逆転(!)していることが分かります。
JIT コンパイルの成果が出やすいループだったという事もあるのかと思いますが、コードをこねくり回して+可読性を犠牲にしてまで処理をベクトル化する必要性は必ずしもないのかもしれません。ただあくまで1例でありすべてのケースで for ループで実装したほうが速いというわけではない点にはご注意ください。
数値にすると以下の通り(単位は秒)
| forLoop(平均) | vector(平均) | forLoop(std) | vector(std) | |
|---|---|---|---|---|
| R2015a | 9.21 | 0.35 | 0.34 | 0.015 |
| R2015b | 1.59 | 0.38 | 0.07 | 0.034 |
| R2017b | 0.48 | 0.33 | 0.016 | 0.032 |
| R2019b | 0.27 | 0.34 | 0.023 | 0.039 |
| R2020b | 0.27 | 0.33 | 0.020 | 0.045 |
使用したコードはすべて最後の Appendix に纏めていますが比較した for ループ版と vector 版の違い以下の通り。
u2(2:xmesh-1,2:ymesh-1) = 2*u1(2:xmesh-1,2:ymesh-1)-u0(2:xmesh-1,2:ymesh-1)+c*c*dt*dt*(diff(u1(:,2:ymesh-1),2,1)/(dx*dx)+diff(u1(2:xmesh-1,:),2,2)/(dy*dy));
for j = 2:ymesh-1
for i = 2:xmesh-1
u2(i,j) = 2*u1(i,j)-u0(i,j) + c*c*dt*dt*((u1(i+1,j)-2*u1(i,j)+u1(i-1,j))/(dx*dx) +(u1(i,j+1)-2*u1(i,j)+u1(i,j-1))/(dy*dy) );
end
end
考慮すべきポイント
そもそもなんでベクトル化が推奨されるの?
実際に 公式ページ:ベクトル化(公式ページ) でもベクトル化が推奨されています。
インタープリタ言語だと入力引数の検証など関数呼び出しのオーバーヘッドが避けられないため、ループを使って関数呼び出し回数が増えれば処理に時間がかかります。また、要素単位で処理するより行列単位で計算する方が行列演算ライブラリ(MATLAB における LAPACK、公式ページ)の良さが活きるからだろうとざっくり理解しています。(この点詳しい方からのコメントお待ちしています)
JIT (Just-in-Time) コンパイル?
MATLAB コードは実行時に Just-In-Time コンパイルが使用されていますが、特に R2015b で JIT (Just-in-Time) コンパイル機能(公式ページ)が刷新されました。結果として
- 関数呼び出しのオーバーヘッド軽減
- オブジェクト指向の処理速度向上
- 要素単位の演算の処理速度向上
などが期待できます。ただ、もちろん関数・スクリプトの初回実行時には 2 回目以降より時間がかかるという点は忘れてはいけません。
スクリプト vs 関数
ある処理を実行する際にスクリプトの状態で比較されることが多いと思いますが、関数化すると状況が異なる場合があります。今回のケースだと関数化したほうが for ループ版は早く実行される傾向にあります。
比較方法詳細
さて、今回の具体的な検証内容ですが、使用したコードはすべて最後の Appendix に纏めていますので興味のある方は是非試してみてください。グラフ描画などは R2020b でやりました。
@t--shin さんの記事では N = 400 で実施していましたが、時間がかかるので以下の比較を分割数 N = 100 と N = 200 で実施してみました。
- 関数同士の比較(for ループ vs ベクトル処理)
- スクリプト同士の比較(for ループ vs ベクトル処理)
具体的には 20 回処理時間を計測し、平均値と標準偏差をプロットします。 N = 400 ではまた異なる傾向があるかもしれません。
nchecks = 20;
T_forLoop = zeros(nchecks,1);
T_vector = zeros(nchecks,1);
for ii = 1:nchecks
tic
tmp1 = wave_forLoop_function(N);
T_forLoop(ii) = toc;
tic
tmp2 = wave_vector_function(N);
T_vector(ii) = toc;
end
vNumber = version('-release');
save(vNumber+"N"+string(N)+"_function.mat","T_forLoop", "T_vector");
こんな感じの関数(speedcheck.m, Appendix 参照)を作りました。
各バージョン開いて実行するのは面倒くさい+処理時間だけできるだけ純粋に比較できるようにコマンドプロンプトから以下のコマンドでそれぞれのバージョンで実行させました。
> "C:\Program Files\MATLAB\R2020b\bin\matlab" -batch "speedcheck(200)"
> "C:\Program Files\MATLAB\R2020b\bin\matlab" -batch "speedcheck(100)"
> "C:\Program Files\MATLAB\R2017b\bin\matlab" -nodesktop -nojvm -nosplash -r "speedcheck(200)"
.
.
R2017b 以前は -batch オプションが無いのでコマンドが少し異なりますが、これでバージョン毎に結果が mat ファイルに保存されるので plotResuts.m (Appendix 参照) でプロットした結果が以下の通り。
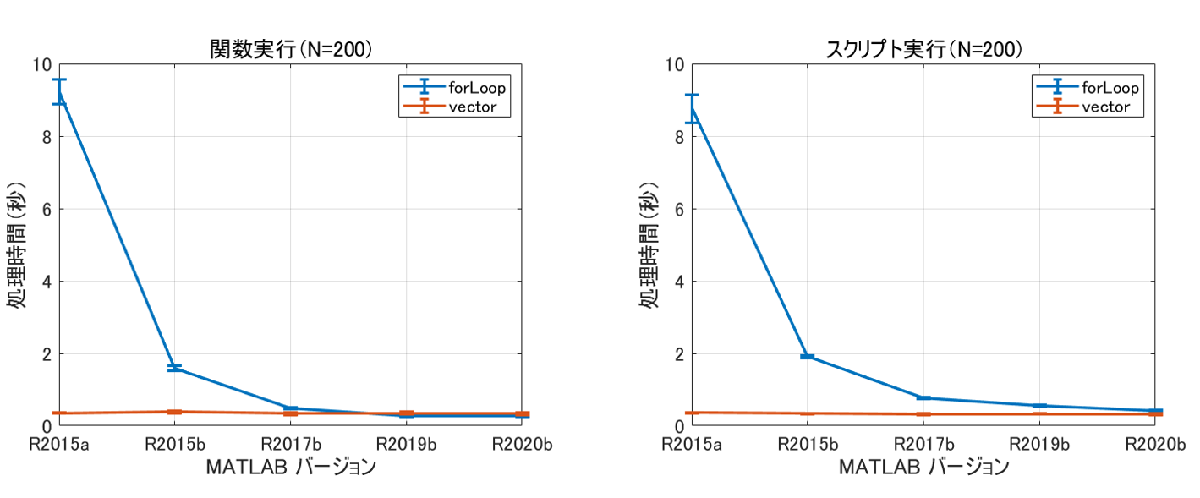
分割数 N = 200 での比較
関数での実行では R2019b 辺りで逆転現象が発生していますね。
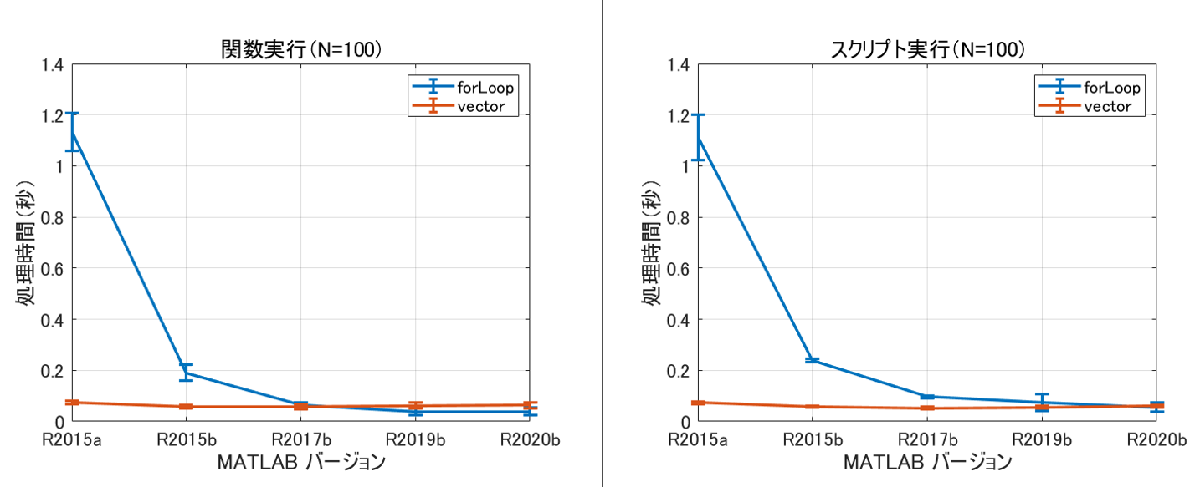
分割数 N = 100 での比較
N = 200 のケースと比較すると for ループの方が有利そうです。
まとめ
for ループもそんなに悪くないね。
可読性を犠牲にしてまで避けるべきでもないものになってきているかと感じました。ただ繰り返しになりますが、あくまで1例でありすべてのケースで for ループで実装したほうが速いというわけではない点にはご注意ください。
もしベクトル化した方が遅い他のケースがあれば是非教えてください!
Appendix: 評価に使った関数
speedcheck.m
計算処理時間計測用の関数。for ループ版、ベクトル化版をそれぞれ関数、スクリプトとして 20 回ずつ計測します。プロットには平均値と標準偏差を使用します。結果はバージョン毎に異なる名前を付けた mat ファイルに保存されます。
function speedcheck(N)
% 処理時間計測用関数(Nはグリッド数)
% 20 回計測し平均値と標準偏差を使用します
nchecks = 20;
% スクリプトでの実行
T_forLoop = zeros(nchecks,1);
T_vector = zeros(nchecks,1);
for ii = 1:nchecks
tic
wave_forLoop_script;
T_forLoop(ii) = toc;
tic
wave_vector_script;
T_vector(ii) = toc;
end
% バージョン毎に結果保存
vNumber = version('-release');
save([vNumber,'N',num2str(N),'_script.mat'],'T_forLoop', 'T_vector');
% 関数での実行
T_forLoop = zeros(nchecks,1);
T_vector = zeros(nchecks,1);
for ii = 1:nchecks
tic
tmp1 = wave_forLoop_function(N);
T_forLoop(ii) = toc;
tic
tmp2 = wave_vector_function(N);
T_vector(ii) = toc;
end
% バージョン毎に結果保存
vNumber = version('-release');
save([vNumber,'N',num2str(N),'_function.mat'],'T_forLoop', 'T_vector');
wave_forLoop_script.m
@t--shin さんが投稿された記事 MatlabやPythonのループは遅いって聞くけど本当? に掲載されているコード(for ループ版)です。分割数だけ自由に設定できるように変更しました。
c = 1.0;
xmin = 0.;
ymin = 0.;
xmax = 1.;
ymax = 1.; % 計算領域は[0,1],[0,1]
xmesh = N;
ymesh = N; % 分割数はx,y軸ともに N
dx = (xmax-xmin)/xmesh;
dy = (ymax-ymin)/ymesh;
dt = 0.2*dx/c;
u0 = zeros(xmesh,ymesh); % u^{n-1}
u1 = zeros(xmesh,ymesh); % u^n
u2 = zeros(xmesh,ymesh); % u^{n+1}
idx1 = round(0.25*N);
idx2 = round(0.75*N);
u1(idx1:idx2,idx1:idx2)=1e-6;% 一定領域に初速を与えている。
x = xmin+dx/2:dx:xmax-dx/2;
y = ymin+dy/2:dy:ymax-dy/2;
t=0.;
% tic %tic tocで時間を計測できる便利なやつ
while t<1.0
for j = 2:ymesh-1
for i = 2:xmesh-1
u2(i,j) = 2*u1(i,j)-u0(i,j) + c*c*dt*dt*((u1(i+1,j)-2*u1(i,j)+u1(i-1,j))/(dx*dx) +(u1(i,j+1)-2*u1(i,j)+u1(i,j-1))/(dy*dy) );
end
end
u0=u1;
u1=u2;
t = t+dt;
%ディリクレ条件を与える
for i=1:xmesh
u1(i,1)=0.;
u1(i,ymesh)=0.;
end
for j=1:ymesh
u1(1,j)=0.;
u1(xmesh,j)=0.;
end
end
wave_vector_script.m
@t--shin さんが投稿された記事 MatlabやPythonのループは遅いって聞くけど本当? に掲載されているコード(ベクトル化版)です。分割数だけ自由に設定できるように変更しました。
c = 1.0;
xmin = 0.;
ymin = 0.;
xmax = 1.;
ymax = 1.; % 計算領域は[0,1],[0,1]
xmesh = N;
ymesh = N; % 分割数はx,y軸ともに N
dx = (xmax-xmin)/xmesh;
dy = (ymax-ymin)/ymesh;
dt = 0.2*dx/c;
u0 = zeros(xmesh,ymesh); % u^{n-1}
u1 = zeros(xmesh,ymesh); % u^n
u2 = zeros(xmesh,ymesh); % u^{n+1}
idx1 = round(0.25*N);
idx2 = round(0.75*N);
u1(idx1:idx2,idx1:idx2)=1e-6;% 一定領域に初速を与えている。
x = xmin+dx/2:dx:xmax-dx/2;
y = ymin+dy/2:dy:ymax-dy/2;
t=0.;
% tic %tic tocで時間を計測できる便利なやつ
while t<1.0
u2(2:xmesh-1,2:ymesh-1) = 2*u1(2:xmesh-1,2:ymesh-1)-u0(2:xmesh-1,2:ymesh-1)+c*c*dt*dt*(diff(u1(:,2:ymesh-1),2,1)/(dx*dx)+diff(u1(2:xmesh-1,:),2,2)/(dy*dy));
u0=u1;
u1=u2;
t = t+dt;
%ディリクレ条件を与える
u1(:,1)=0.;
u1(:,ymesh)=0.;
u1(1,:)=0.;
u1(xmesh,:)=0.;
end
wave_forLoop_function.m
関数版です。お行儀悪いですが分かりやすいよう内部でスクリプトを呼び出しています。
function u1 = wave_forLoop_function(N)
wave_forLoop_script;
end
wave_vector_function.m
関数版です。お行儀悪いですが分かりやすいよう内部でスクリプトを呼び出しています
function u1 = wave_vector_function(N)
wave_vector_script;
end
plotResults.m
結果の描画用スクリプト
nversion = ["2015a","2015b","2017b","2019b","2020b"];
T_script100 = zeros(5,4);
T_function100 = zeros(5,4);
T_script200 = zeros(5,4);
T_function200 = zeros(5,4);
for ii=1:5
load(nversion(ii) + "N100_script.mat");
T_script100(ii,1) = mean(T_forLoop);
T_script100(ii,2) = mean(T_vector);
T_script100(ii,3) = std(T_forLoop);
T_script100(ii,4) = std(T_vector);
load(nversion(ii) + "N100_function.mat");
T_function100(ii,1) = mean(T_forLoop);
T_function100(ii,2) = mean(T_vector);
T_function100(ii,3) = std(T_forLoop);
T_function100(ii,4) = std(T_vector);
load(nversion(ii) + "N200_script.mat");
T_script200(ii,1) = mean(T_forLoop);
T_script200(ii,2) = mean(T_vector);
T_script200(ii,3) = std(T_forLoop);
T_script200(ii,4) = std(T_vector);
load(nversion(ii) + "N200_function.mat");
T_function200(ii,1) = mean(T_forLoop);
T_function200(ii,2) = mean(T_vector);
T_function200(ii,3) = std(T_forLoop);
T_function200(ii,4) = std(T_vector);
end
array2table(T_function200,'VariableNames',["forLoop(mean)","vector(mean)","forLoop(std)","vector(std)"])
%%
hf = figure(1);
hf = plotResults(hf,T_function100,"関数実行(N=100)");
hf = figure(2);
hf = plotResults(hf,T_function200,"関数実行(N=200)");
hf = figure(3);
hf = plotResults(hf,T_script100,"スクリプト実行(N=100)");
hf = figure(4);
hf = plotResults(hf,T_script200,"スクリプト実行(N=200)");
function hf = plotResults(hf,data,figureTitle)
nversion = ["R2015a","R2015b","R2017b","R2019b","R2020b"];
errorbar(data(:,1),data(:,3),'LineWidth',2,'CapSize',10)
hold on
errorbar(data(:,2),data(:,4),'LineWidth',2,'CapSize',10)
hold off
legend('forLoop','vector');
title(figureTitle)
set(gca,'XTick',[1,2,3,4,5]);
set(gca,'XTickLabel',nversion)
ylabel('処理時間(秒)');
xlabel('MATLAB バージョン');
set(gca,'FontSize',14);
grid on
end