機械学習をきちんと学ぼう 第一弾
今回の趣旨
今までtensorflowなどを使用して簡単なアプリケーションを構築したりしていたのですが,ほとんど理解せずに使用していたため,自分で考えて微妙な調整をするなどは全くできない状態でした. これではよくないと考え, 機械学習を行う際の手順を0から学びたいと思い, この記事を書いています. ちなみに, 今後の記事は以下の書籍を参考に書いていきます.
ここでいう機械学習は, PCがデータを元にデータを処理するためのモデルの選択, 作成から, モデルの使用, 評価までをさすこととします.

また, この書籍で使用されているデータは以下のGithub上に上がっているので, そちらをダウンロードして使用してください.
https://github.com/wrichert/BuildingMachineLearningSystemsWithPython
機械学習アプリケーションの構築(初歩)
今回の内容
機械学習システムで用意されている[1時間ごとのwebのトラフィック量に関するデータ]を利用して, 1時間のトラフィック量が500000トラフィックを超えるのはいつになるのかを予測してみたいと思います.
用意されているデータはダウンロードしたディレクトリ内のch01/data/web_traffic.csvを使用します.
前提
今回はライブラリは使えるものとして進めるので, それぞれのメソッド, 関数などの説明はしません.
環境
Mac
python3
1. データ確認
まずは, データの中身がどのようなデータなのかを読み込んで確認しようと思います.
データのサイズは6.4Kと小さいため, 一度に全て読み込もうと思います. これがもし多い場合は全て読み込んでしまうと大量にメモリを使用してしまうため, 一気に重くなる可能性があるので, 最初に取り扱うデータ量を確認するところは大切です.
# 機械学習に必要なライブラリ群のimport
>>> import scipy as sp
>>> import matplotlib.pyplot as plt
# データの読み込み
>>> data = sp.genfromtxt("web_traffic.tsv", delimiter="\t")
>>> print(data[:10])
[[1.000e+00 2.272e+03]
[2.000e+00 1.656e+03]
[3.000e+00 1.386e+03]
[4.000e+00 1.365e+03]
[5.000e+00 1.488e+03]
[6.000e+00 1.337e+03]
[7.000e+00 1.883e+03]
[8.000e+00 2.283e+03]
[9.000e+00 1.335e+03]
[1.000e+01 1.025e+03]]
>>> print(data.shape)
(743, 2)
データの整形
この章にて行うことは, データを扱うのに都合の良い形に変えることです.
そのために, 一つの変数に入っている二つのベクトルを別々の変数に格納します.
>>> x = data[:,0]
>>> y = data[:,1]
2. データの前処理
ここでは, 取得したデータ内に, 欠損値, ノイズ, 外れ値が含まれていないかを確認し, それぞれに対して, 適当な処理を行います.
欠損値の評価と対応
欠損値とは, 取得したデータが何らかの問題で取得できなかったところに発生する問題です.この値に対しては, その時点の値をそもそもなかったこととして削除してしまうか, 周囲の値に揃えて, 平均などの適当な値で埋めてしまうなどの方法があります.
欠損値はscipyの場合は[nan]という値で格納されているデータが該当します.
まずは[nan]が含まれている量を測定します.
>>> sp.sum(sp.isnan(y))
0
今回は欠損値はありませんでした. もし, 削除する場合は
>>> x = x[~sp.isnan(y)]
>>> y = y[~sp.isnan(y)]
とすることで外れ値を削除することができます.
ノイズの評価と対応
ノイズとは, 正規分布の端点に位置するデータ群だと自分は認識しています.というのも, 本来, 事象や物事はあるべき本来の形を中心にして正規分布的な形で発生, 存在している. しかし, その端点に存在するデータも本来あるべき形が示しているデータのうちの一つとして学習させるべきかということです. (この下のグラフの両はしの発生率の低い部分のこと)
例えば, この下の小学生の一日の摂取カロリーを学年ごとに調査し, 学年ごとの摂取カロリーのモデルを作成しようとしてるとしましょう. その場合, 学年ごとに縦軸を人数, 横軸をカロリーで示した場合は全ての学年において以下のような正規分布を示すはずです. しかし, 中には将来アメフト選手などを目指して毎日1万カロリー取っていますなどというスーパー小学生もいるかもしれません. しかし, そのような小学生は稀であり, 下のグラフでいうと端っこのところに含まれることになります. この際に, その小学生を学年ごとの摂取カロリーのモデル作成に入れてしまうと本来作りたいモデルからは少し離れてしまうため, 外すべきでは?というのがノイズへ対処すべき理由です.(異なる場合は指摘していただけると助かります)
ノイズは一旦グラフ化することで視覚的に存在を確認することができます.
>>> plt.scatter(x,y)
>>> plt.title("web traffic over the last month")
>>> plt.xlabel("Time")
>>> plt.ylabel("Hits/hour")
>>> plt.xticks([w*7*24 for w in range(10)],['week %i '%w for w in range(10)])
>>> plt.autoscale(tight=True)
>>> plt.grid()
>>> plt.show()
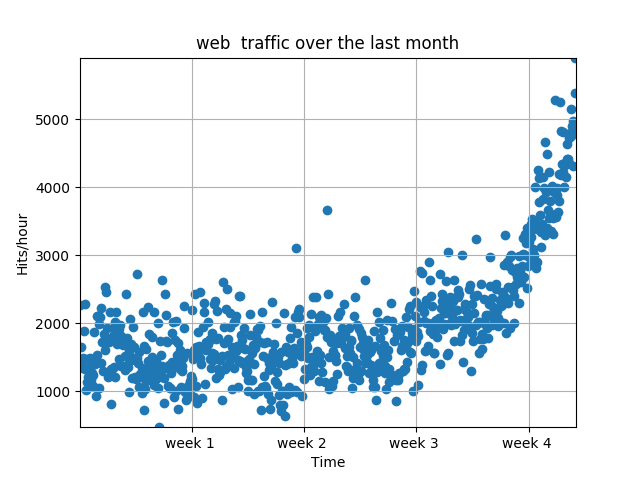
グラフを見た所, 大きなノイズと見られる値はないため今回はこのまま進めます.
外れ値の評価と対応
外れ値とはデータを取得する際に使用したセンサーの故障や人的なミスにより取得されたありえないデータに対する対処です.
例えば, 先ほどの小学生の一日の摂取カロリーの例で言えば-1000カロリーという値があったとします. カロリーデータにマイナスは存在しないため, これは間違いということになります.
これもノイズ同様にグラフなどで視覚化したり, マイナスの値があるかなどのチェックを入れることで判別することができます.
今回はノイズのところで視覚化した時にそれらしき値は確認できなかったため外れ値はなしとして進めます.
3. モデル作成
訓練データとテストデータに分ける
ここでは用意したデータセットを訓練データとテストデータに分ける作業を行います. 訓練データとはモデルを作成するためのデータで, テストデータは作成したモデルの評価に使用します.
訓練用とテスト用を別々にする理由を説明します. モデルを作成する理由はそもそも, 未知のデータを予想するためです. そして, このモデルを作成するには過去のデータを利用しますが, このモデルを評価する際に訓練に含まれているデータを利用しても適切な評価を行うことができません. というのも, この訓練時に使用したデータに対してのみ高い一致率を示すモデルが作成されているだけで, 含まれていないデータに対しては全く役に立たないモデルが作成される可能性があります. このようなモデルの状況を過学習と呼びます. このような過学習の状況にあるモデルを使用しないように正しく評価するためには訓練データにてモデルを作成し, テスト用データにて評価をすることで未知のデータに対しても使用できる真なるモデルを選択することができます.
では, 訓練データとテストデータに分ける手順です.
今回は訓練 : テストを7:3で分けたいと思います.
>>> frac = 0.3
>>> split_idx = int(frac * len(x))
>>> shuffled = sp.random.permutation(list(range(len(x))))
>>> test = shuffled[:split_idx]
>>> train = shuffled[split_idx:]
線形モデル
まずは線形でモデルを作成してみましょう.
>>> fp1, residuals, rank, sv, rcond = sp.polyfit(x[train], y[train], 1, full=True)
>>> print("Model parameters: %s " % fp1)
Model parameters: [ 2.57152281 1002.10684085]
>>> print(residuals)
[3.19874315e+08]
以上の計算によって, fp1に線形で表現されたモデルのパラメータが入っており,これを数式で表すと
y = 2.571x + 1002
になります. このパラメータを用いてモデルを作成するには以下のようにします.
>>> f1 = sp.poly1d(fp1)
>>> print(f1)
2.572 x + 1002
このように, f1が数式として表現されています.
次数が2の多項式曲線モデル
先ほどは線形である一次式で近似しました. 今度は2次式で近似してみたいと思います.
やり方はとても簡単で, 先ほどのpolyfitの引数1を2にすれば2次式になります. また, 先ほどは引数にてfull=Trueとしたため, 多くの結果が返されましたが, これはなくすことで, 2次式のパラメータのみが取得できます.
>>> fp2 = sp.polyfit(x[train], y[train], 2)
>>> print(fp2)
[ 1.04688184e-02 -5.21727812e+00 1.96921629e+03]
>>> f2 = sp.poly1d(fp2)
0.01047 x^2 - 5.217 x + 1969
数式で表すと
y = 0.01047 x^2 - 5.217 x + 1969
になります.
次数が3の多項式曲線モデル
今度は3次式で近似してみたいと思います.
やり方はpolyfitの引数2を3にすれば3次式になります.
>>> fp3 = sp.polyfit(x[train], y[train], 3)
>>> print(fp3)
[ 3.18145203e-05 -2.49384741e-02 5.27178547e+00 1.31460438e+03]
>>> f3 = sp.poly1d(fp3)
3.181e-05 x^3 - 0.02494 x^2 + 5.272 x + 1315
数式で表すと
y = 0.00003181 x^3 - 0.02494 x^2 + 5.272 x + 1315
になります.
モデルの評価方法
モデルの作成方法には様々な種類があります. それらはこれが最も適したモデルであるというものは存在せず, その最適さは扱うデータによって異なります. では, それをどのようにして見つけたら良いのかというと, 作成した各々のモデルを同じ軸の指標を用いて比較することによって最適さを決めることができます. そこで使用されるのが, 誤差関数というものです. これは, モデルが予想した値と, 実際に取得した値のユークリッド平方距離を誤差として計算する方法で, 実際のデータと作成したモデルの乖離を数値化し, それを元に比較を行なっています. 計算方法は以下になります.
>>> def error(f, x, y):
>>> return sp.sum((f(x)-y)**2)
この評価方法にも複数の手法があるので, ぜひ調べてみてください.
モデルの評価
では早速, 作成した三つのモデルに加えて10次元と100次元のものを加えて評価してみたと思います.
まずは, それぞれを評価関数である誤差関数にて評価したいと思います
>>> print(error(fp1, x[test], y[test]))
99595511.10469732
>>> print(error(fp2, x[test], y[test]))
60719316.56938812
>>> print(error(fp3, x[test], y[test]))
47735706.95055852
>>> print(error(fp10, x[test], y[test]))
42563051.16770753
>>> print(error(fp100, x[test], y[test]))
41171553.289567575
これを見ると一見,次数が高ければ高いほど良い結果になっているように見えます.では次にグラフにしてみたいと思います.
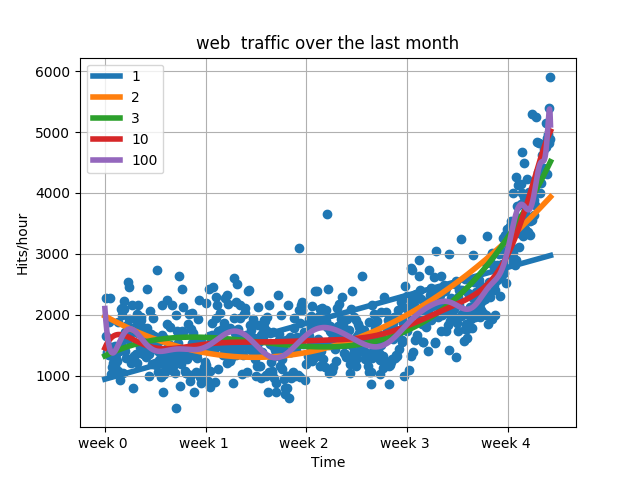
これを見ると, 次数が高いグラフは蛇行しています. これはデータ内のノイズに対して反応してしまっている状況で, 過学習が発生してしまっています. よって良いモデルとは言えません. ではこのように過学習になってしまった時の改善方法はどうすれば良いのか.次に取るべき行動は以下の3つの行動が挙げられます.
- 多項式モデルからどれか一つを選択する.
- より複雑なモデルに切り替える
- データについて別の視点で考え, 初めからやり直す
今回は, 3つ目の別の視点で捉えてみたいと思います.
別の視点で考える
散布図のデータをみてみると3週目の途中, 約3.5週目からデータの繊維がいきなり変わっていることが伺えます. このことから, 0週目から3.5週目までと,3.5週目以降のデータは別々のモデルが裏に存在すると捉えることができます.
よってここからは以下のような手順でモデルを構築したいと思います.
1. 3.5週目より前と後でデータを分ける.
2. 今回の目的は一時間当たりのアクセス数が500000アクセスに達する週を予測することである. よって, より今後の未来を示しているであろう3.5週目以降のデータを使用してモデルを作成する.
3. 作成したモデルを評価関数により評価する.
3.5週目以降のデータを取得
# 3.5週目以前, 以降で分ける
>>> inflection = 3.5 * 7 * 24
>>> xa = x[:inflection]
>>> ya = y[:inflection]
>>> xb = x[inflection:]
>>> yb = y[inflection:]
# さらに, 訓練データとテストデータとで分ける
>>> frac = 0.3
>>> split_idx = int(frac * int(len(xb)))
>>> shuffled = sp.random.permutation(list(range(len(xb))))
>>> train_xb = sorted(shuffled[:split_idx])
>>> test_xb = sorted(shuffled[split_idx:])
3.5週目以降のデータのみを用いてモデルを作成する
>>> f1 = sp.poly1d(sp.polyfit(xb[train_xb], yb[train_xb], 1))
>>> f2 = sp.poly1d(sp.polyfit(xb[train_xb], yb[train_xb], 2))
>>> f3 = sp.poly1d(sp.polyfit(xb[train_xb], yb[train_xb], 3))
>>> f10 = sp.poly1d(sp.polyfit(xb[train_xb], yb[train_xb], 10))
>>> f100 = sp.poly1d(sp.polyfit(xb[train_xb], yb[train_xb], 100))
モデルを評価関数にて評価する
>>> print(error(f1, xb[test_xb], yb[test_xb]))
20464654.391516544
>>> print(error(f2, xb[test_xb], yb[test_xb]))
16538250.686778337
>>> print(error(f3, xb[test_xb], yb[test_xb]))
16582432.034499796
>>> print(error(f10, xb[test_xb], yb[test_xb]))
30821442.151004374
>>> print(error(f100, xb[test_xb], yb[test_xb]))
386374941.4076538
この結果から面白いことが判明しました. 最も, 評価関数の結果が小さいのは2次式のモデルになりました. このことから, 未来のデータを予測する最適な関数は2次式で近似したモデルということが判明しました.
それではこのモデルを利用して1時間当たり500000アクセスに達する週がいつになるかを予想したいと思います.
1時間当たり500000アクセスに達する週の答え
この答えはf2モデルの答えが500000になるxを予想すれば良いということのため以下の関数にて答えを得ることが出来る.
>>> from scipy.optimize import fsolve
>>> reached_max = fsolve(f2-500000, 800) / (7*24)
>>> print("500000 hits/hour expected at week %f" % reached_max[0])
500000 hits/hour expected at week 18.269475
このことから答えは18.2週後に限界に達するということがわかりました.
まとめ
今回学習したことは, 機械学習をする際の基本的な手順が
1.データのサイズ確認
2.データの中に確認
3.データの整形
4.データの前処理
5.データの解析
6.データ解析結果の評価
ということと, その中でも, データの前処理や解析をする際の前提を間違えると出力された結果がそれなりの評価値になっても信頼性が全くない結果になったしまうということでした.
今後は, 異なる種別のデータや手法などを試していきたいと思います.
追記
修正点や指摘ポイントがある場合はいただけると助かります.