10分で分かるpandas
はじめに
この記事はpandas公式チュートリアル「10 minutes to pandas」の写経及び解説です
以下のURLを参考にしています
https://pandas.pydata.org/pandas-docs/stable/getting_started/10min.html
環境
- Python3.7
- Jupyter Lab
とりあえずインポート
import numpy as np
import pandas as pd
np
pd
以下のように各モジュールが表示されればOK

エラーが起きた場合
**ModuleNotFoundError: No module named 'pandas'**と怒られる場合、まずpandasを入れます。
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-1-59ab05e21164> in <module>
1 import numpy as np
----> 2 import pandas as pd
ModuleNotFoundError: No module named 'pandas'
コマンド
python -m pip install pandas
1. オブジェクトを作る
Seriesクラスにリストを入れることで簡単にデータを作ることが出来ます。
# 簡単に一列作る
s = pd.Series(data=[1, 3, 5, np.nan, 6, 8])
s

date_range()を使うことで、特定の期間の日付の行を作成出来ます。
# 2020年1月1日から6日間のデータ
dates = pd.date_range("20200101", periods=6)
dates

pandasのDataFrameクラス引数indexを指定することで、行インデックスを指定することが出来ます。
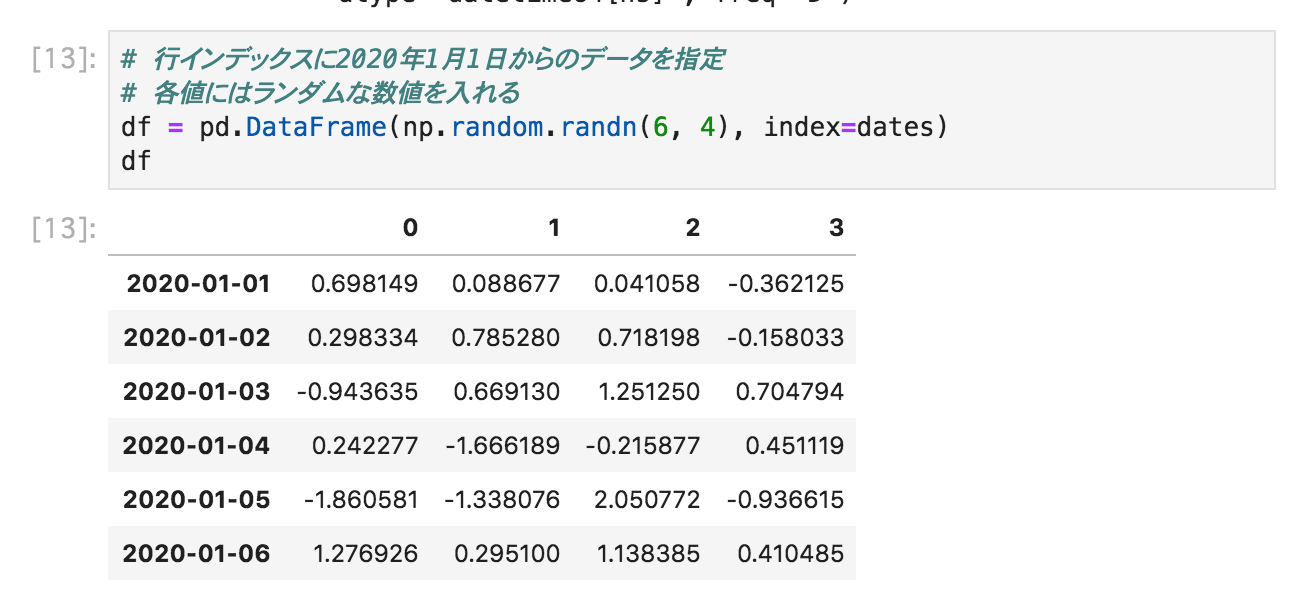
# 行インデックスに2020年1月1日からのデータを指定
# 各値にはランダムな数値を入れる
df = pd.DataFrame(np.random.randn(6, 4), index=dates)
df
また、同じくDataFrameクラスの
引数columnsを指定することで列名を設定することが出来ます。
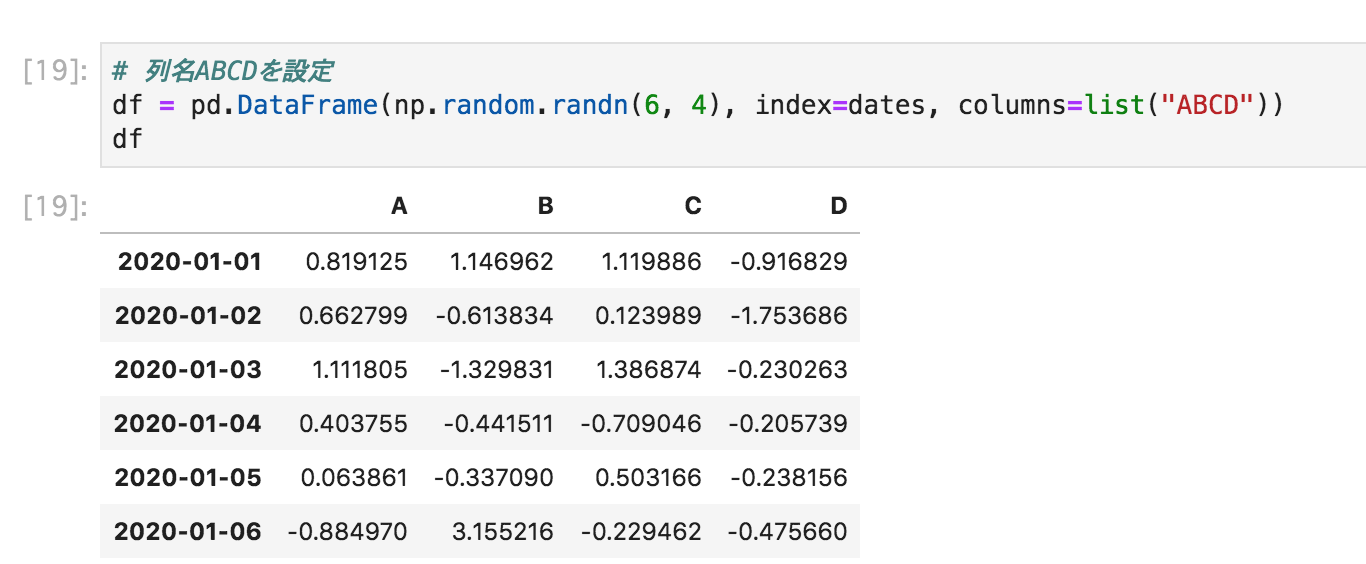
# 列名ABCDを設定
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD"))
df
DataFrameクラスに辞書型のデータを渡すことで、辞書型のキーの部分が列名になります。
df2 = pd.DataFrame(
{
"A": 1.,
"B": pd.Timestamp("20200101"),
"C": pd.Series(1, index=list(range(4)), dtype="float32"),
"D": np.array([3] * 4, dtype="int32"),
"E": pd.Categorical(["test", "train", "test", "train"]),
"F": "foo",
}
)
df2

dtypes属性に参照することで各列のデータ属性が分かります。
df2.dtypes

Jupyter nootbookやJupyter Labなどを使っている場合、列名がタブ補完で表示されます。
db2.<TAB>

2. データを表示する
DataFrameクラスのhead()メソッドを使うことでデータの先頭部を表示できます。
df.head(2)

同じくDataFrameクラスのtail()を使うことでデータの後尾部を表示できます。
df.tail(2)

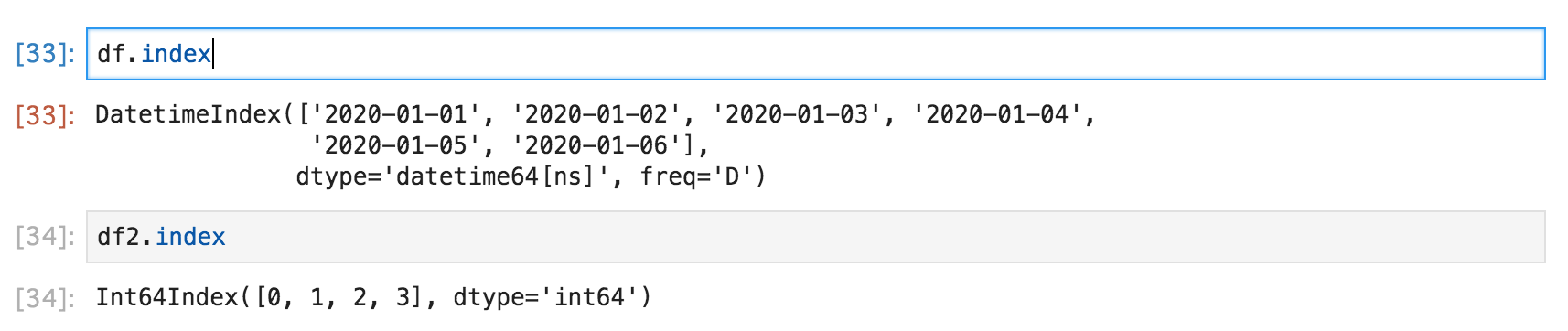
DataFrameクラスの**index**を参照することでそのデータの行インデックスを表示出来ます。
df.index
df2.index
DataFrameクラスのto_numpy()を使うことでデータをnumpyで操作しやすいデータに変換できます。
df.to_numpy()
df2.to_numpy()

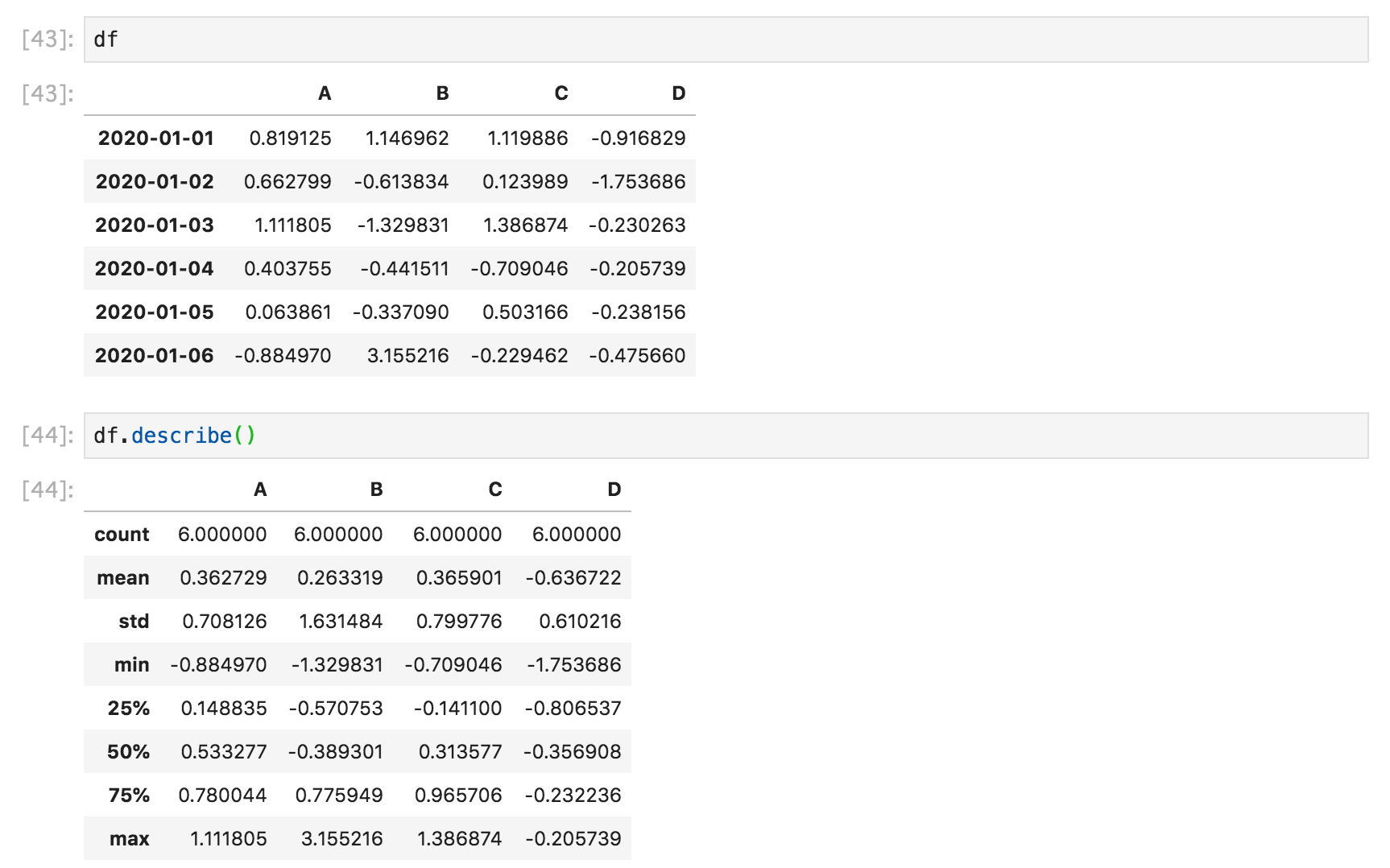
DataFrameクラスの参考:DataFrame.describe()を使うことで、データの各列の簡単な統計を取ることができます。
df2.describe()
DataFrameクラスのT属性を参照すると、行列入れ替えたデータにアクセスできます。
df.T

また、DataFrameクラスのtranspose()でも同じく行列の入れ替えを取得できます。
df.transpose()

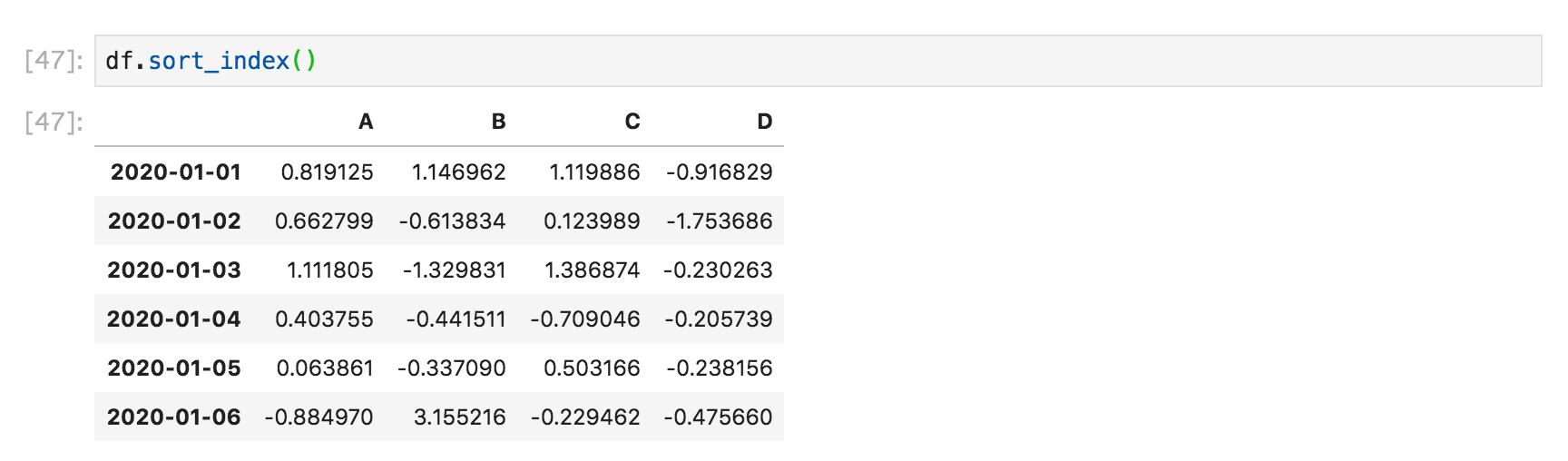
DataFrameクラスのsort_index()を使用することで、行全体もしくは列全体の並び替えを行うことができます。
df.sort_index()
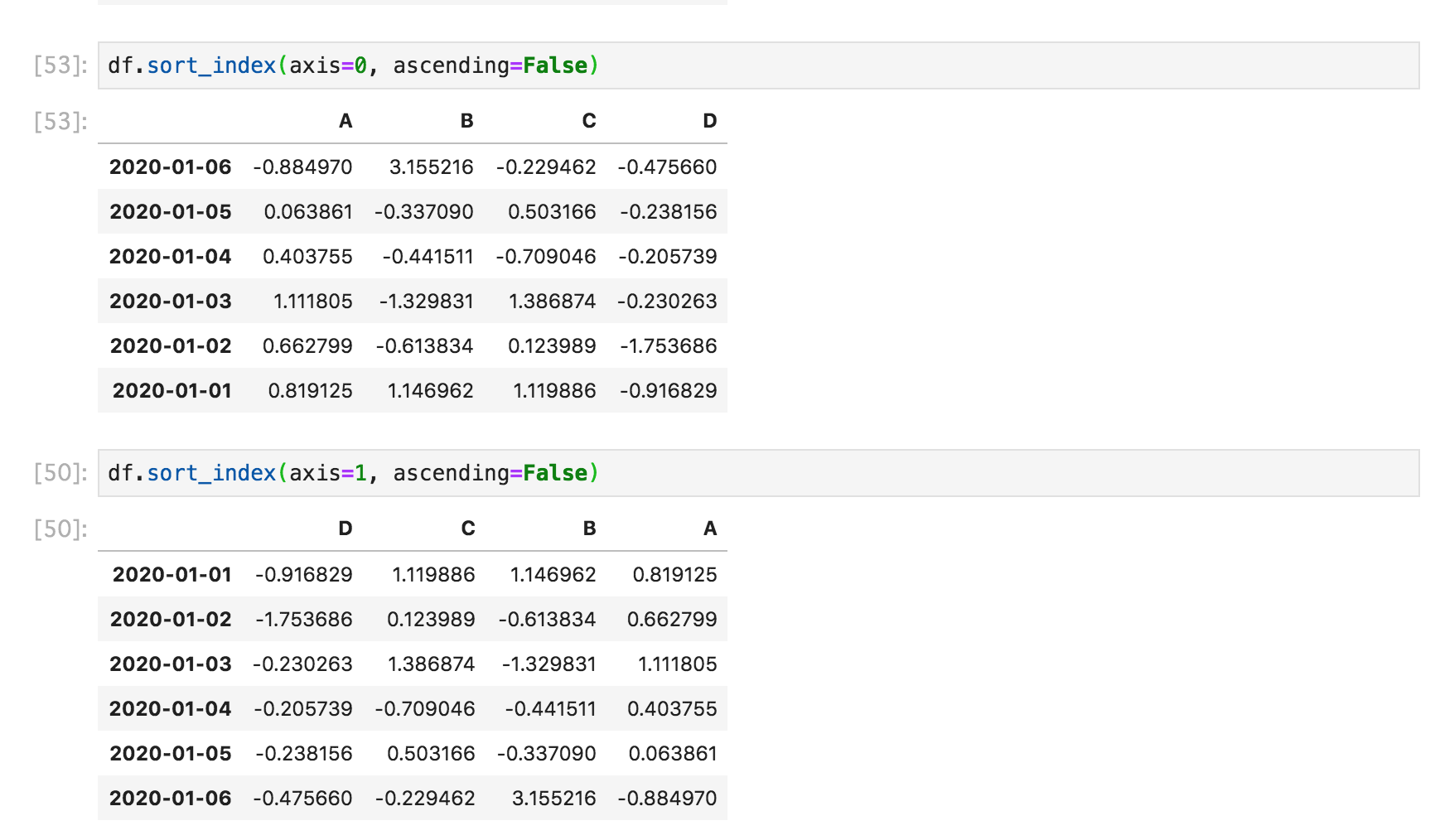
引数axisに0もしくは"index"を設定すると行に、1もしくは"columns"を設定すると、列を軸に並び替えします(デフォルト値0)。また、引数ascendingにFalseを指定すると並び順が降順になります(デフォルト値True)。
df.sort_index(axis=0, ascending=False)
df.sort_index(axis=1, ascending=False)
DataFrameクラスのsort_values()を使用することで行単位もしくは列単位に並び替えを行うことができます。
df.sort_values(by="B")
df.sort_values(by="2020-01-01", axis=1)

(2020-03-07追記)
3. データを選択する
単純なデータ取得
df["A"]もしくはdf.Aとすることで、指定した一列を取得することができます。
df["A"]
df.A

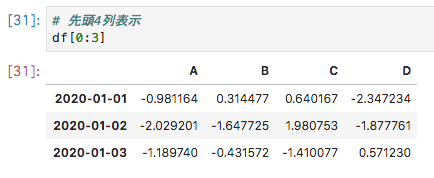
リスト**[]**で指定した場合、Pythonのスライス操作で列や行を選択することができます
# 先頭4列表示
df[0:3]
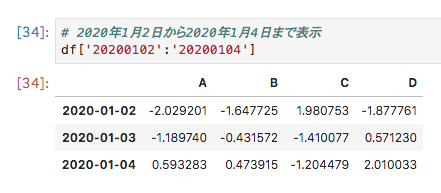
リインデックスの範囲を取得することもできます。
# 2020年1月2日から2020年1月4日まで表示
df['20200102':'20200104']
ラベルを指定してデータを選択する
DataFrameクラスのloc()にインデックス(今回の場合dates)を指定することで、行を列として選択することができます。
df.loc[dates]
df.loc[dates[0]]

loc()を使うことで、複数列を選択することができます。
df.loc[:, ["A", "B"]]

先頭のコロンがない場合エラーになるみたいです。

loc()スライス操作を組み合わせることで複数行、複数列選択することができます。
df.loc['20200102':'20200104', ['A', 'B']]

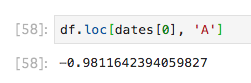
loc()にインデックスを指定することで単体データを取得できます
df.loc[dates[0], 'A']
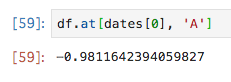
at()を使うことでより高速に単体データを取得することができます
df.at[dates[0], 'A']
位置を指定してデータを選択する
DataFrameクラスのiloc()を使うことで、数値を指定してデータ選択することが出来ます。
df.iloc[3]
df.iloc[3:5, 0:2]
df.iloc[[1, 2, 4], [0, 2]]

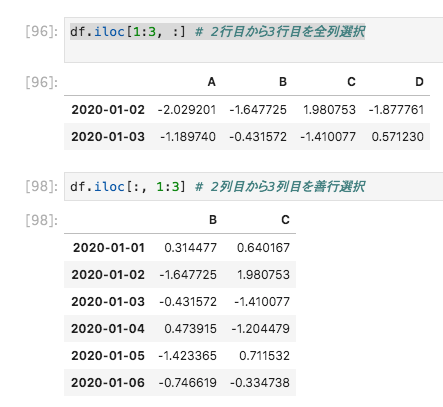
DataFrameクラスのiloc()の引数に開始位置終了位置を省略したスライス(:のみ)を指定することで、特定の全行 or 全列を取得できます
df.iloc[1:3, :]
df.iloc[:, 1:3]
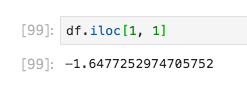
DataFrameクラスのiloc()に引数にを数値のみ指定することで、単体データの選択ができます
df.iloc[1, 1]
at()と同様、iat()使うことでより高速に単体データを取得することができます
df.at[dates[0], 'A']

条件判定によるデータ選択
(ここで力尽きる。残り……多くない?10分とは![]() )
)
4. 欠損データ
5. 操作
6. マージ
7. グルーピング
8. 再構築
9. 時系列
10. カテゴリー化
11. プロット
12. データの入力と出力
13. 落とし穴