PandasはPythonのデータ解析ライブラリです。
データの加工や集計、分析に皆様活用されていると思います。
最近ではPolarsというRustベースの高速データ解析ライブラリが登場し、こちらを利用する人も増えているのではないかと思います。
PolarsではApache Arrowという列指向のデータフォーマットをベースにしており、データの高速処理を実現しています。
そんな中、最近Pandasの2.0がプレリリースされたようです。
2.0では、Apache ArrowをPython操作できるようにしたライブラリPyArrowがPandasで使えるようになったようなので、どれだけ高速に処理できるのか早速試してみました。
前提
Pandas2.0はプレリリース版を使用します。
(この記事を書いている2023/3/21時点では、まだ正式リリースされていないようです。)
追記(2023/4/6):
2023/4/3にPandas2.0.0が正式リリースされたようです。
実行環境
Google Colaboratory(無料版、GPU利用なし)を利用します。
準備
pandasのプレリリース版2.0.0rc0と、比較用にpolarsをインストールします。
!pip install --upgrade --pre pandas==2.0.0rc0
!pip install polars
インポートとバージョンの確認
import pandas as pd
import numpy as np
import polars as pl
print('pandas: ', pd.__version__)
print('polars: ', pl.__version__)
# 実行結果
# pandas: 2.0.0rc0
# polars: 0.16.13
性能評価用のダミーデータを準備します。
今回は10万行のデータを利用します。
# ダミーファイル用のデータ準備
str_val = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
sample_n = 100000
df = pd.DataFrame({
'col1': np.random.choice(str_val, sample_n),
'col2': np.random.rand(sample_n),
'col3': np.random.rand(sample_n),
})
print(df.shape)
display(df.head())
# ダミーファイル作成
df.to_csv('./df_data.csv', header=True, index=False)
# 実行結果
# (100000, 3)
# col1 col2 col3
# 0 g 0.622630 0.878988
# 1 f 0.389823 0.525934
# 2 d 0.043534 0.703387
# 3 e 0.750366 0.596771
# 4 f 0.599945 0.038867
評価用コードの実装と実行
以下3つのライブラリの処理速度を比較します。(PyArrow未使用のPandasも2.0.0rc0を使います。)
- Pandas - PyArrow未使用
- Pandas - PyArrow使用
- Polars
ファイル読み込み
# Pandas PyArrow未使用
%timeit -n 100 -r 10 pd.read_csv('./df_data.csv')
# Pandas PyArrow使用
%timeit -n 100 -r 10 pd.read_csv('./df_data.csv', \
engine='pyarrow', \
use_nullable_dtypes=True)
# Polars
%timeit -n 100 -r 10 pl.read_csv('./df_data.csv')
# 実行結果
# 54.5 ms ± 6.76 ms per loop (mean ± std. dev. of 10 runs, 100 loops each)
# 25.8 ms ± 6.02 ms per loop (mean ± std. dev. of 10 runs, 100 loops each)
# 17.3 ms ± 3.79 ms per loop (mean ± std. dev. of 10 runs, 100 loops each)
ファイル保存
# Pandas PyArrow未使用
%timeit -n 10 -r 5 df_read.to_csv('./df_read.csv', index=False)
# Pandas PyArrow使用
%timeit -n 10 -r 5 df_read_arrow.to_csv('./df_read_arrow.csv', index=False)
# Polars
%timeit -n 10 -r 5 df_read_polars.write_csv('./df_read_polars.csv')
# 実行結果
# 472 ms ± 97.8 ms per loop (mean ± std. dev. of 5 runs, 10 loops each)
# 532 ms ± 185 ms per loop (mean ± std. dev. of 5 runs, 10 loops each)
# 62.1 ms ± 2.65 ms per loop (mean ± std. dev. of 5 runs, 10 loops each)
mean
# Pandas PyArrow未使用
%timeit -n 100 -r 10 df_read['col2'].mean()
# Pandas PyArrow使用
%timeit -n 100 -r 10 df_read_arrow['col2'].mean()
# Polars
%timeit -n 100 -r 10 df_read_polars.select('col2').mean()
# 実行結果
# 324 µs ± 47.7 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
# 98.6 µs ± 28.4 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
# 196 µs ± 56 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
unique
# Pandas PyArrow未使用
%timeit -n 100 -r 10 df_read['col1'].unique()
# Pandas PyArrow使用
%timeit -n 100 -r 10 df_read_arrow['col1'].unique()
# Polars
%timeit -n 100 -r 10 df_read_polars.select('col1').unique()
# 実行結果
# 3.99 ms ± 299 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
# 1.55 ms ± 84.3 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
# 3.69 ms ± 170 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
round
# Pandas PyArrow未使用
%timeit -n 100 -r 10 df_read[['col2', 'col3']].round()
# Pandas PyArrow使用
%timeit -n 100 -r 10 df_read_arrow[['col2', 'col3']].round()
# Polars
%timeit -n 100 -r 10 df_read_polars.with_columns([ \
pl.col(c).round(0) for c in ['col2', 'col3'] \
])
# 実行結果
# 2.17 ms ± 79.9 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
# 4.7 ms ± 92.5 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
# 542 µs ± 68.7 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
集計
# Pandas PyArrow未使用
%timeit -n 100 -r 10 df_read.groupby('col1').sum()
# Pandas PyArrow使用
%timeit -n 100 -r 10 df_read_arrow.groupby('col1').sum()
# Polars
%timeit -n 100 -r 10 df_read_polars.groupby('col1').sum()
# 実行結果
# 8.14 ms ± 2.07 ms per loop (mean ± std. dev. of 10 runs, 100 loops each)
# 13.9 ms ± 3 ms per loop (mean ± std. dev. of 10 runs, 100 loops each)
# 5.36 ms ± 1.26 ms per loop (mean ± std. dev. of 10 runs, 100 loops each)
merge
# マージ用ダミーデータ作成
df_tmp = pd.DataFrame({
'col1': ['a', 'b', 'c', 'd', 'e', 'f', 'g'],
'val': ['000', '001', '002', '003', '004', '005', '006']
})
# Pandas PyArrow未使用
%timeit -n 100 -r 10 df_read.merge(df_tmp, on='col1', how='left')
# Pandas PyArrow使用
%timeit -n 100 -r 10 df_read_arrow.merge(df_tmp, on='col1', how='left')
# Polars
df_tmp_pl = pl.from_pandas(df_tmp)
%timeit -n 100 -r 10 df_read_polars.join(df_tmp_pl, on='col1', how='left')
# 実行結果
# 16.8 ms ± 3.39 ms per loop (mean ± std. dev. of 10 runs, 100 loops each)
# 21.2 ms ± 3.5 ms per loop (mean ± std. dev. of 10 runs, 100 loops each)
# 6.74 ms ± 1.85 ms per loop (mean ± std. dev. of 10 runs, 100 loops each)
結果
結果をグラフで確認します。


meanとuniqueでPandas PyArrow使用が一番処理速度が速いが、それ以外は全てPolarsが速いという結果になりました。
データ件数を1000万件に増やしたバージョンでも試してみました。
結果は以下の通りです。
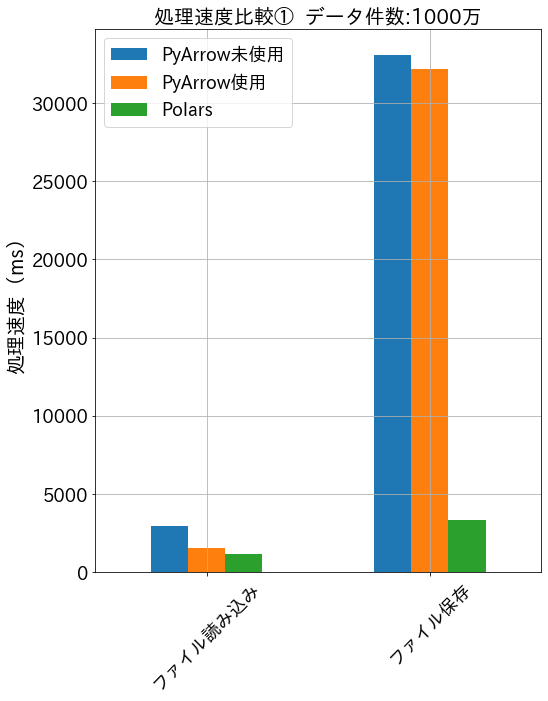

unique以外全てPolarsが速いという結果になりました。
まとめ
Polars強い。。