本記事は CyberAgent Group SRE Advent Calendar 2024 の10日目の記事になります。
株式会社 サイバーエージェント AmebaLIFE事業本部 開発局の江原です。
本記事では、Amebaブログのバックエンドチームで実施したAmebaブログコアシステムへの負荷試験と実際に行ったチューニング事例についてご紹介します。
負荷試験を実施した背景
Amebaブログバックエンドチームでは、ブログコアシステムの刷新を進めています。その際、旧システムと新システムでは技術スタックに以下のような違いがありました。
- 旧システム
- 使用言語・フレームワーク: Java・Spring Boot
- 通信方式: REST API
- 実行元: EC2
- 新システム
- 使用言語: Go
- 通信方式: graphQL API / gRPC
- 実行元: EKS
新システムを稼働させるにあたり、以下の点を確認するために負荷試験を実施する必要がありました。
- 1Podあたりの最適なリソース量
- 必要となるPodの最大数
- 適切なオートスケーリングの設定値
システム構成
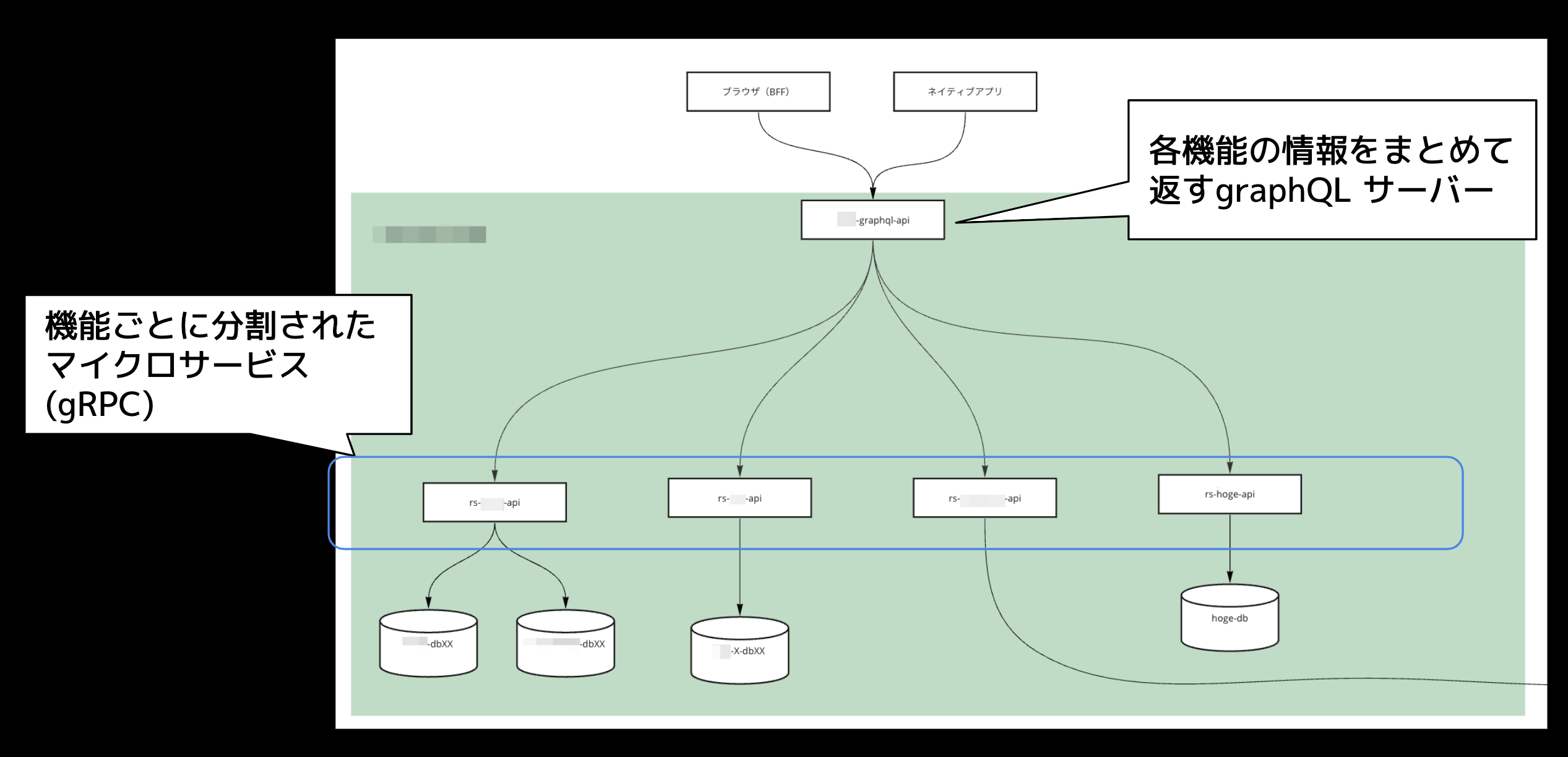
まずシステム構成について説明します。負荷試験対象となるシステムは次の2種類で構成されています。1つ目は機能単位で分割されたマイクロサービス群、2つ目はそれらが返す情報を集約しクライアントへ返却するGraphQLサーバーです。
事前準備
今回対象となるアプリケーションはEKS (Elastic Kubernetes Service) 上で稼働し、データベースはAurora MySQLを利用しています。
負荷試験を実施するために本番環境のAurora MySQLのデータを負荷試験環境にクローンし、本番相当の環境を構築しました。また、アプリケーションについても負荷試験環境にEKSクラスターを構築し、その上で各種マイクロサービスを稼働させるようにしました。
利用した負荷試験ツール
今回の負荷試験ではk6という負荷試験ツールと、k6による負荷走行をkubenetesクラスタ上で実行できる k6-operator を使って負荷試験を行いました。
これらのツールを選定した理由は以下のとおりです。
- 過去に同じチームでの実績があり、k6への知見があったこと
- k6-operatorを活用することで、比較的簡単に負荷の分散実行ができること
- 同一kubernetesクラスタ上にdatadog-agentを立てることで、k6-operatorの結果をdatadog上で確認できること
k6-operatorを実行するEKSクラスターとアプリケーションを実行するEKSクラスターはそれぞれ、別のAWSアカウント上で構築しています。
負荷試験計画
今回実施した負荷試験は主に2つのステップに分けて実施しました。
- 1Pod単位の性能試験
- 事前に想定している負荷をかける想定負荷試験
それぞれの試験の詳細を説明します。
1Pod単位の性能試験
この試験では、マイクロサービス単位でリソース割り当てを変えながら、最大のパフォーマンスが出せるリソース量を調査しました。
各種マイクロサービスはEKS上で稼働させるため、マイクロサービスごとに以下のようなマニフェストファイルをapplyして試験を実施しました。
apiVersion: apps/v1
kind: Deployment
metadata:
name: xxx-api
namespace: xxxx
spec:
replicas: 1
selector:
matchLabels:
app: xxx-api
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
template: metadata:
labels:
app: xxx-api
spec:
resources:
# requestsとlimitsでCPUのコア数・メモリ量ともに同じ値を指定する
limits:
cpu: 2000m
memory: 100Mi
requests:
cpu: 2000m
memory: 100Mi
試験を実施する際は、事前にCPUのコア数とメモリ量の組み合わせを決めておき、一番パフォーマンスが出る組み合わせを本番稼働時に採用するというやり方で実施していました。
想定負荷試験
想定負荷試験では、マイクロサービス・graphQL APIそれぞれ1Podずつ起動し、HPAのしきい値を設定。徐々にリクエスト数を想定負荷まで近づけながら試験を実施しました。
この試験では主に以下の点を確認しています。
- 本番リリース時に設定するHPA (Horizontal Pod AutoScaler) の適切なしきい値
- 今回対象となるアプリケーションはCPUのaverageUtilizationを基準としていました
- アプリケーション全体が想定している負荷に耐えられること
試験結果
これらの負荷試験を実施したことで、事前に分かっていなかったボトルネックや、最適なリソース割り当ての設定を把握することが出来ました。
ここからは、実際に試験をやって得られた知見や注意点をご紹介します。
(12/10までにまとめきれなかった項目があり、後ほど加筆予定です。)
1Podあたりのリソース割り当てについて
1Podあたりの性能試験で最適なCPU割り当てを試していた際、興味深い結果が得られたのでご紹介したいと思います。
以下の表では最適なCPU割り当てをそれぞれ試した結果を示しています。
| 割り当てるコア数 (millicore) | 1000 millicoreを1としたときの最大RPSの相対性能 |
|---|---|
| 1000 | 1 |
| 2000 | 2.25 |
| 4000 | 4 |
| ※メモリ量は同一 |
このアプリケーションはGoで書かれています。Goはマルチコアスケールをサポートする言語のため、すべての処理が並行処理できる場合、コア数に比例して性能も向上するはずです。しかし、表を見ると、2000millicoreの場合は2.25倍性能が増加しているのに対し、4000millicoreでは4倍となっており、性能向上率が縮小していることが分かります。
この結果を見るまでコア数と性能の関係が分からなかったことを踏まえると、実際に負荷試験をして性能を計測することの重要性を感じました。
k6-operatorとdatadogの連携について
負荷試験を実施していた際、k6-operatorが実行したjobリソースのログが出力するレイテンシの値と、datadog上に出力されているメトリクスの値が一致していないことがありました。
同じような問題がまとまっているissueがないか確認したところ、同じ症状を訴えているissue がありました。issueの内容をざっくりまとめると、statsdの問題でメトリクス情報がドロップしていることが原因で、datadog上に出力される情報で不整合が発生しているとのことでした。この問題は2024/12/10時点でも解決されていません。
そのため、以下の方法で結果を確認するのをおすすめします。
- issueで示されている通り、OpenTelemetryでのoutputオプションを使ってメトリクスを出力する
- k6が出力するメトリクスではなく、アプリケーション側から出力されるメトリクスを使う
実際、自分のチームでは、アプリケーション側で出力された各種メトリクスを使って負荷試験結果をまとめるようにしていました。
終わりに
本記事では、Amebaブログで実施した負荷試験事例についてご紹介しました。