アプリケーションで利用したデータを分析やマーケティングに活用するために、Digdagで分析用データベースに転送する処理を定期実行しています。その処理が期待した時間以内に終わらなかったことを検知するために、実行中のワークフローを定期的にチェックし、実行時間の監視するワークフローを作成したのでその紹介をします。
※Digdagそのものに関する説明は割愛しています。
環境
Digdag ServerはREST APIを提供しており、HTTPリクエスト経由で状態を取得することができます。
この機能を使って、全プロジェクトの実行状況をチェックし、長時間実行中のジョブがあったらslackで通知する仕組みを作りました。
利用言語はpython3.8.1で依存ライブラリはrequestsとpytzです。
前提
まずDigdagで実行されるワークフローがどんな単位でデータが保持されているのかを説明します。これはあくまで私の理解なので誤りがあるかもしれません。
Digdagにはproject, workflow, session, attempt, taskの5つの要素があり、包含関係は下図のようになります。
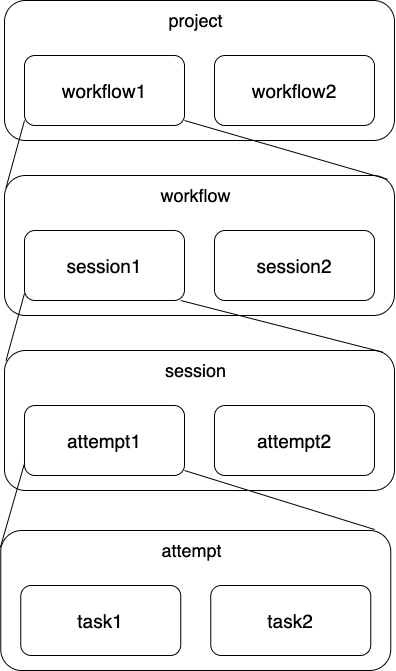
projectはworkflowを束ねる階層で、1つのprojectの中に複数workflowを定義できます。これはディレクトリ構造によって決まります。workflowは実行する処理の単位であり、定義したdigファイルに対応します。workflowを実行(run)したらsessionが作成され、実行する毎に新しいsessionが生成されます。
さらにsessionの中にはattemptとtaskという概念があります。sessionが失敗した場合リトライすることが可能ですが、リトライ時は同一sessionで異なるattemptが開始されます。そのため、最新でかつ、実行中のattemptを特定し、経過時間を取得することで、実行時間を算出することができます。taskはdigファイルの中で何かしらのオペレータを指定した場合に実行される単位であり、これは実行時間の算出に使います。
つまり、全プロジェクトの全workflowの中で実行中のsessionの中の最終attemptの実行時間を見ることで、現在のDigdag上で動いている処理の経過時間を計算することができます。
実装手順
pythonで上記のチェックを作る手順を説明します。
ワークフロー毎に実行中のセッション情報を取得する
まずは全プロジェクトのidを取得し、配列として保持します。requestsを使った場合は下記の方法でリクエストを送るとプロジェクト情報を取得できます。
projects = requests.get(f'{digdag.env.params["digdag_host"]}/api/projects')
project_id_list = [project.get('id') for project in projects.json()['projects']]
digdag_hostは各々の環境のDigdag Serverのホスト名を_exportで指定してください。
次に、このproject_id_ldを使ってプロジェクト毎にワークフローとセッション情報を取得します。セッションはワークフロー単位で取れないため、プロジェクト単位で取得した後に、ワークフロー名でフィルタリングします。
for project_id in project_id_list:
workflows = requests.get(f'{digdag.env.params["digdag_host"]}/api/projects/{project_id}/workflows')
sessions = requests.get(f'{digdag.env.params["digdag_host"]}/api/projects/{project_id}/sessions')
for workflow in workflows.json()['workflows']:
target_sessions = list(filter(lambda x: x['workflow']['name'] == workflow['name'], sessions.json()['sessions']))
last_session = target_sessions[0]
これで各プロジェクトの各ワークフローで実行中のセッション情報を取得することができました。
直近1回分のセッション情報が見れたらいいので、配列の先頭だけ利用しています。
取得したセッションの実行時間を算出する
次に取得したセッションの実行時間を出します。
前述した通り最終attemptのtaskの情報を使います。実行時間はtaskの中で最小の開始時間と現在時刻の差分で算出します。
# 最終attempt_idからattemptを取得
last_attempt_id = last_session['lastAttempt']['id']
last_attempt = requests.get(f'{digdag.env.params["digdag_host"]}/api/attempts/{last_attempt_id}')
# 完了したattempの場合はスキップ
if last_attempt.json()['done']:
continue
# task一覧を取得し、実行時間を算出
tasks = requests.get(f'{digdag.env.params["digdag_host"]}/api/attempts/{last_attempt_id}/tasks')
start_time_list = []
for task in tasks.json()['tasks']:
start_time_list.append(datetime.strptime(task['startedAt'], "%Y-%m-%dT%H:%M:%S%z").astimezone(timezone('Asia/Tokyo')))
start_time = min(start_time_list)
current_time = datetime.now(timezone('Asia/Tokyo'))
duration = (current_time - start_time).seconds
ワークフロー毎に閾値を決めてチェック
あワークフロー毎にdurationが閾値を超えているかをチェックし、問題があればslackへの通知を実行します。
あとはdigファイルに定期実行するスケジュール設定して完成です。
最後に
この仕組みがあると長時間実行中のワークフローがあった場合に気付くことができるようになりました。新規プロジェクトやワークフローが追加されても特に意識することなく対象に加わるため、運用手順が増えることもありません。