最近新卒にスマブラでタイマンを挑んでは負けを繰り返している中途入社エンジニアの @e_tyubo です。
この記事は ZOZOテクノロジーズ #1 Advent Calendar 2019 10日目の記事です。
昨日は @sesta さんによる「Lookerの派生テーブルを使って、集計量を減らす」でした。
話題のBIツールの活用事例を具体的に紹介していて、とても実用的な記事でしたので見習っていきたいです。
本記事はWindowsと仲良くなりたいMacユーザにお送りする文字コードのお話です。
はじめに
Macを使って開発をしてきた人にいきなりWindowsで開発をしろと言われたら多分抵抗はありますよね。
しかし、Windowsでしか動かせないソフトを使っていたり、何かとWindowsの方が好都合だからという至って合理的な理由でそのシチュエーションは容易に生じ得ます。
ある程度は仕方ないと思う部分もありますが、なんだかんだで自分だけMacで開発することになったときに必要となる知識について書こうと思います。
MacとWindowsの差異
基本的には問題の種となるのは下記だと思います。
- 文字コード違う問題
- 改行コード違う問題
- Windowsにしかクライアントアプリがない問題
本当は色々書きたかったですが、今回は文字コードについてのみ触れます。
文字コード違う問題
文字コードの概念は、これらの問題に向き合う際に必須です。
文字コードの定義は「プログラマのための文字コード技術入門」という書籍の中で、下記のように書かれています。
文字とそれに対応するビットの組み合わせを対応付ける規則を文字コードといいます。
人間が解釈するための言語をPC上で表現するためにはビットで表現(符号化)する必要があります。
例えばアルファベットのA~Cを表現するために必要な規則は2ビット使って下記のように定義できます。
A = 01
B = 10
C = 11
このような文字列とbit配列の対応関係を文字コードとして定義し、様々な言語を表現しています。
今回登場するのは
- ASCII
- Shift-JIS(日本語用)
- UTF-8(多言語をサポート)
です。
それぞれ特徴がありますが、ここではあまり重要ではないため詳しくは触れません。
ASCII(American Standard Code for Information Interchange)コードは多くの文字コードと互換性がある、主要な文字コードです。
アルファベットと数値が含まれており、プログラミングの世界でも頻繁に使う文字列ばかりのため、ざっくりでも理解していると役立ちます。
含まれる文字列の一覧は調べればすぐに出てきますが、wikipediaのが見やすかった。
https://ja.wikipedia.org/wiki/ASCII
文字コード違う問題
本題に入ります。
基本的には、MacとWindowsでデフォルトエンコードがそれぞれ
| Mac | Windows |
|---|---|
| UTF-8 | Shift-JIS |
のようになっている。という認識で話を進めます。
必ずしもそうではないですが、Windowsで作る(見る)ファイルはShift-JIS、Macで作る(見る)ファイルはUTF-8というイメージで読むと理解しやすいかと思います。
アルファベットや数字に関してはASCIIコードで記述でき、UTF-8でもShift-JISでも互換性があるため特に意識する必要はありません。日本語という特殊な文化のおかげで苦労してるわけですね。
文字コード自体はエディターの設定等で自由に変えられるのですが、Windowsで開発していると Shift-JIS なファイルがよく使われます。
特にWindows Serverで動かす用に作られたVBScriptを使っている場合だと、UTF-8な日本語がコメントやログ出力等に含まれていると実行時にエラーになってしまうので、Shift-JIS不可避です。
UTF-8が標準で使われるMacを使った場合に生じがちな問題としては
- 文字化けして日本語が読めない
- VBScriptなどShift-JIS前提な言語が実行できない
- grepを使った文字列検索がうまくいかない
といったことが考えられますが、知っておくべきポイントは
- 文字化けする理由
- 文字コードの確認方法
- 文字コードの変換方法
- 文字列検索の時に考えるべきエンコード設定
あたりだと思います。
上記についてそれぞれ説明します。
文字化けする理由
これは単純な話で、文字化けは
表示しようとしているファイルの文字コードと、表示に使う文字コードが異なる時
に発生します。
Macの標準ターミナルでShift-JISな日本語が含まれているファイルを開いた時を例に説明します。
下記のような日本語を含むShift-JISなファイルがあったとします。
こんにちは
Qiitaを書くのは楽しいね
このような素晴らしい日本語も、Macのターミナルでcatするとこうなります。
$ cat greet_sjis.txt
????ɂ???
Qiita???????̂͊y??????
これではアルファベット以外読めませんね。
こうなってしまうのは、ターミナルで表示しようとしている文字コードがUTF-8に設定されているからです。
筆者は普段使わないので、ほぼデフォルトの設定ですが、下記のような設定になっています。
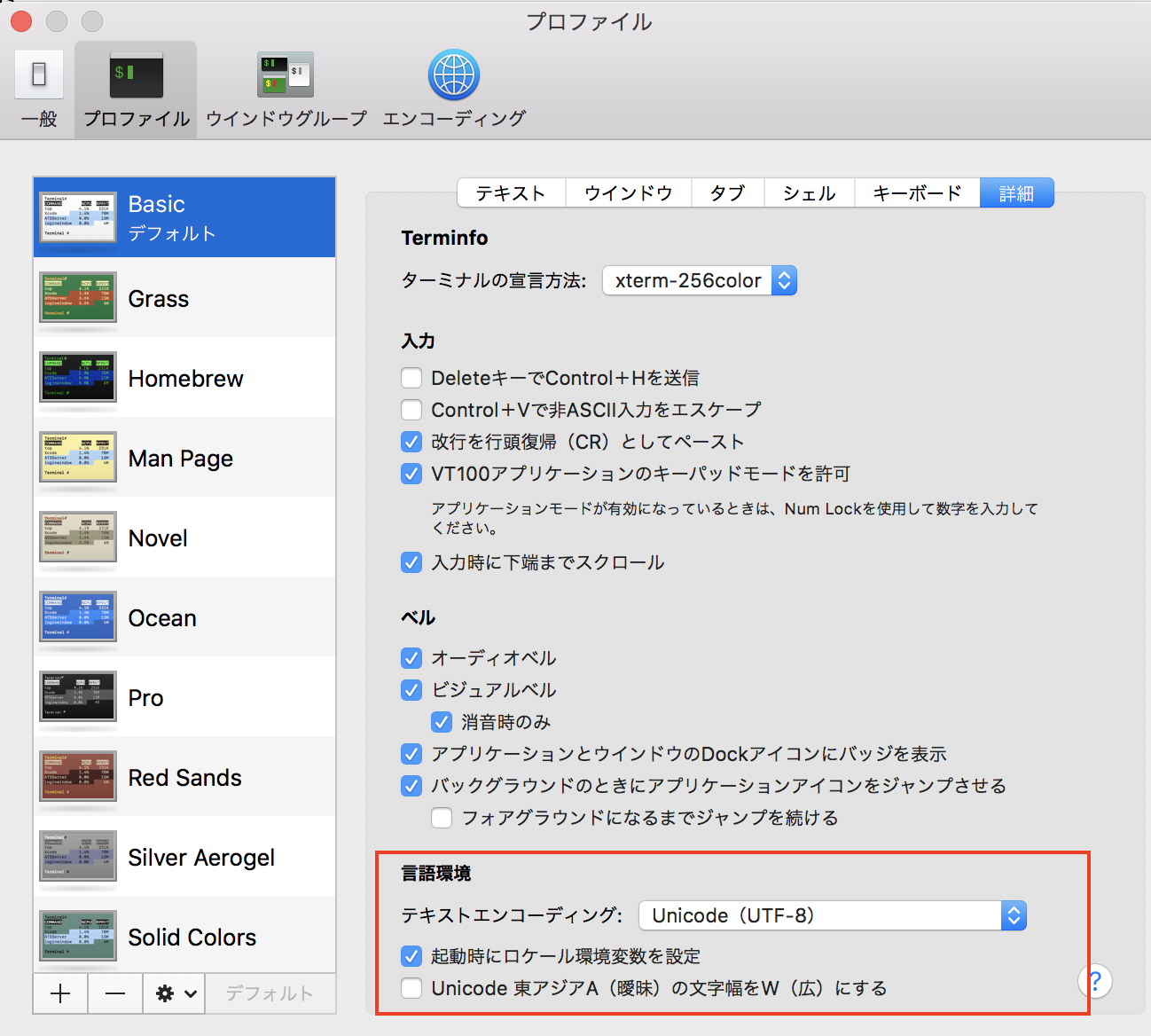
テキストエンコーディング: UTF-8
です。
そのため、ターミナルの画面上で表示される文字列は基本的にUTF-8として認識されます。
Shift-JISな日本語をUTF-8で表示しようとしても、何を表示したらいいかわかりません。
そのため????のように解釈不能な文字列が並んでます。
当然文字コードを統一すれば適切に表示できます。

$ cat greet_sjis.vbs
こんにちは
Qiitaを書くのは楽しいね
これで解決です。
文字化けが発生したら、表示に使っている文字コードを気にすると良いです。
文字コードの確認方法
適切に表示するために必要な設定はわかったので、次は確認方法を紹介します。
ファイルの設定Macユーザの皆様であれば、Linuxのコマンドがターミナルからスムーズに使えますので、下記で説明するコマンドで確認が可能です。
fileコマンド
標準で備わってるこのコマンドを使えば、fileのエンコーディング情報をまとめて表示できます。
fileコマンドの結果を3パターン載せました。改行コードについてはここでは詳しく触れません。
- Shift-JISな日本語あり、改行コードはCRLF
- UTF-8な日本語あり、改行コードはLF
- 日本語(ASCIIコードに含まれない文字)なし、改行コードはLF
file file_sjis_with_jp.vbs
# file_sjis_with_jp.vbs: Non-ISO extended-ASCII text, with CRLF line terminators
file file_utf8_with_jp.vbs
# file_utf8_with_jp.vbs: UTF-8 Unicode text
file file_without_jp.vbs
# file_without_jp.vbs: ASCII text
注意点としては、ファイルの文字が全てASCIIで構成される場合はASCII textと認識されます。必ずしも日本語だけが該当するわけではないのですが、日本語のようなASCII以外の文字列が登場すると、どの文字コードで記述されたのかを判断する必要が出てきます。
nkfコマンド
これは追加でインストールする必要がありますが、brew install nkfを実行すれば使えます。
このコマンドは文字コードの変換にも使えるため、コマンドラインで処理したい場合には便利です。
nkf -g file_sjis_with_jp.vbs
# Shift_JIS
nkf -g file_utf8_with_jp.vbs
# UTF-8
nkf -g file_without_jp.vbs
# ASCII
gオプションはguessのことで、文字コードを表示することができます。
fileコマンドよりも結果はシンプルで、文字コードに特化したコマンド。という印象です。
文字コードの変換方法
次に変換方法です。
先に紹介したnkfコマンドを使うと簡単に変換できるのでその方法を紹介します。
コマンドのhelpドキュメントを見てみます(一部抜粋)
nkf --help
# j/s/e/w Specify output encoding ISO-2022-JP, Shift_JIS, EUC-JP
# UTF options is -w[8[0],{16,32}[{B,L}[0]]]
# J/S/E/W Specify input encoding ISO-2022-JP, Shift_JIS, EUC-JP
# UTF option is -W[8,[16,32][B,L]]
# --overwrite[=SUF] Preserve timestamp of original files
output encoding が変換先の文字コードです。
nkf -g file_utf8_with_jp.vbs
# UTF-8
nkf -s file_utf8_with_jp.vbs > file_utf8_to_sjis_with_jp.vbs
nkf -g file_utf8_to_sjis_with_jp.vbs
# Shift-JIS
nkf -g file_sjis_with_jp.vbs
# Shift-JIS
nkf -w file_sjis_with_jp.vbs > file_sjis_to_utf8_with_jp.vbs
nkf -g file_sjis_to_utf8_with_jp.vbs
# UTF-8
変換処理は難しい作業ではなく、このようにワンラインで実行できます。
InteliJのようなエディターを使っても変換が可能です。
文字列検索の時に考えるべきエンコード設定
これでファイルがどんな文字コードになってるかを確認し、必要に応じて変換できるようになりました。
ただし、MacのターミナルでShift-JISなファイルから文字列をgrepで検索するときは注意が必要です。
たとえば下記のようなShist-JISな日本語を含んだ単純なテキストファイルがあったとします。
a
あ
あa
aあ
このファイルに対し、Macのデフォルトターミナルで下記を実行したら
grep "あ" file_sjis_with_jp.txt
なんと何もヒットしません。
この問題を紐解くためには文字コードに関する設定が3箇所存在することを認識する必要があります。設定は下記の3つです。
- ファイル自体の文字コード
- ターミナルが認識する文字コード
- 環境変数LANG
期待した動作をさせるためには、これら全ての文字コードを一致させる必要があります。
ファイル自体の文字コード
これは単純な話で、検索対象のファイルがどの文字コードで文字列を保持しているかの設定になります。
今回だとShift-JISです。
ターミナルが認識する文字コード
これが一つの盲点です。
何気なくgrepで指定した"あ"という文字列。PCで表示している以上、これにも文字コードが存在します。
grep "あ" file_sjis_with_jp.txt
文字化けの説明でも触れましたが、ターミナルに表示される文字の文字コードはアプリケーションの設定によって決まります。
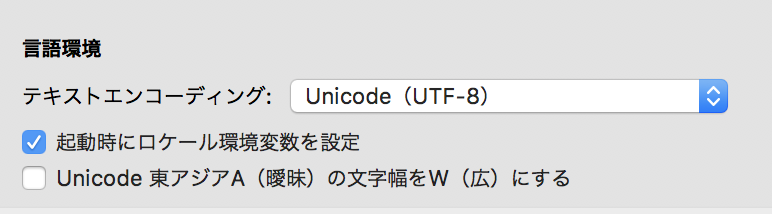
最初の状態だとおそらくUTF-8となっており、何気なく入力している日本語は自動的にUTF-8として裏では認識されています。
この状態ではUTF-8の"あ"でShift-JISの"あ"を検索しに行くため、ヒットしません。
言語環境でShift-JISを選択すると、入力文字列がShift-JISになるため、晴れて検索条件と検索対象の文字コードが一致します。

こうしましょう。
しかし、これだけではダメです。
環境変数LANG
環境変数LANGは言語毎に表示をローカライズする際に用いられるものみたいです。詳しくないので事実ベースで書きます。
設定内容はlocaleコマンドで確認することができます。
$ locale
LANG="ja_JP.UTF-8"
LC_COLLATE="ja_JP.UTF-8"
LC_CTYPE="ja_JP.UTF-8"
LC_MESSAGES="ja_JP.UTF-8"
LC_MONETARY="ja_JP.UTF-8"
LC_NUMERIC="ja_JP.UTF-8"
LC_TIME="ja_JP.UTF-8"
LC_ALL=
Macのターミナルでの実行結果です。
ja_JP.UTF-8となっているため、UTF-8を使って表示を日本語表示しろってことですかね。
試しにLANGを指定せずにコマンドを実行すると
$ grep "あ" file_sjis_with_jp.vbs
grep: illegal byte sequence
というエラーになり、実行できません。grepが文句を言ってるので、LANGを指定して実行してみます。
$ LANG=jp_JP.sjis grep "あ" file_sjis_with_jp.vbs
あa
aあ
あいうえお
おえういあ
動きました。
grepコマンドが内部的にLANGを参照して、UTF-8で"あ"を処理しようとしたけど、Shift-JISな"あ"が入力されてるから上手く処理できなかった。って感じかと思います。(予想)
これで解決しました。
別のケースも見てみましょう。
ターミナルの文字コードをUTF-8に戻して"a"を検索してみます。
$ grep "a" file_sjis_with_jp.vbs
a
aiueo
なんと"あ"を含む行がヒットしません。
ターミナルの文字コードをShift-JISに変更してaを検索して見ます。
$ grep "a" file_sjis_with_jp.vbs
a
aiueo
変化なしです。
次にLANGを指定して、検索します。
LANG=jp_JP.sjis grep "a" file_sjis_with_jp.vbs
a
あa
aあ
aiueo
ヒットしました。
ターミナルの文字コードは、あくまでターミナルに表示される文字列にしか影響がないと考えると、入力に日本語が含まれていないため結果に変化がなかったことは理解できます。
LANGを指定したことにより結果が得られたということは、grepコマンドの中で文字列を解釈するときにはLANGの設定が利用され、行単位でLANGと文字コードが異なる日本語が含まれるとスキップされるようです。
この挙動は認識していないと割と危険で、「grepで検索してもヒットしないから文字列含まれてない」という結論を出す前に環境変数LANGとファイルの文字コードの確認をするようにしましょう。
最後に
周りがWindowsな環境な中Macで開発するのは肩身が狭かったりしますが、この辺りのケアをしっかりして迷惑をかけない立ち回りをすることで、健全な開発が進められるかと思います。
明日は開発合宿にドローンを持ってきてしまうお茶目なエンジニア @ikeponsu が記事を書いてくれますので乞うご期待!