courseraでせっかく受けた授業も受けたっきりでは忘れてしまいそうなので、今まで受けた授業をまとめてみようと思います。数式メイン、しかも理解しきれてないところもあります。何かあったらご指摘して頂けるとありがたいです。備忘録はあまり書いたことがないのでそこらへんはご了承ください。
(あと3,4週分一気にまとめようとしてるので抜けがいっぱいあるかもorz)
1 Week
はじめに大まかな機械学習の説明から始まりました。例えば何に使われているとか、機械学習の種類とか。
その部分いついては省かせていただきます。
Linear regression with one variable
手始めに単回帰分析から。
h_\theta(x) = \theta_0 + \theta_1x \\
J(\theta_0,\theta_1) = \frac{1}{2m} \sum_{i=1}^m ( h_\theta(x^{(i)}) - y^{(i)} )^2
$h_\theta(x)$はHypothesis functionで特徴量から予測値を計算するための関数です。
特徴量っていうのは、例えば家賃を予測するときに家の大きさだったり駅からの近さだったりです。
単回帰分析はこの特徴量が1個です。
一方、$J(\theta_0,\theta_1)$はCost functinで、別名は目的関数とか損失関数とかだった気がします。
単回帰分析はこの$J(\theta_0,\theta_1)$の値が一番小さくなるように$\theta_0,\theta_1$を更新していくものです。
目的関数は見ればわかる通り、予測値と実数値の差の二乗をとっています。これは、どれくらい予測値と実数値に差があるかを表します。なので、それが小さくなれば、関数の予測が上手くいくわけです。この方法をGradient descent algorithm(勾配降下法)と言います。
で肝心の$\theta_0,\theta_1$の更新方法はこちらです。
\theta_0 := \theta_0 - \alpha\frac{\partial}{\partial \theta_0}J(\theta_0,\theta_1) \\
\theta_1 := \theta_1 - \alpha\frac{\partial}{\partial \theta_1}J(\theta_0,\theta_1)
偏微分を用いて更新する$\theta$から引いていきます。
これは、イメージ的に先に進んだら値が上がるなら引いて、値が下がるなら足すってことなんですかね。
これでそれぞれの$\theta$に対しての極小値が求められる…はず?
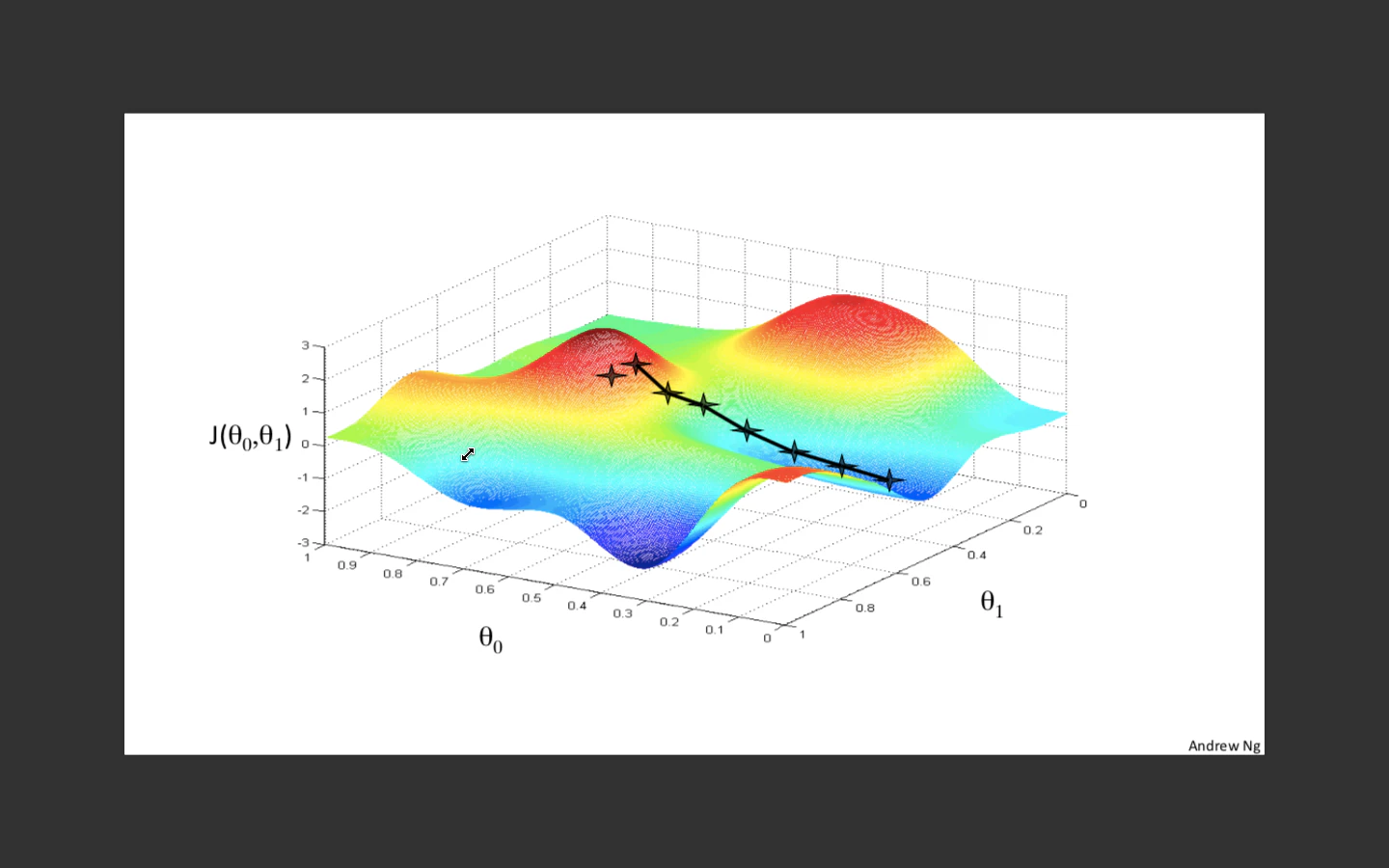
しかしどうやらそんなこともないらしい。
図の通り、小さい値を求めることはできるがその部分が全体を見たときの最小の値かはわからない。局所的最適解ではあるけど大域的最適解かどうかは分からないわけです。
あとは線形代数の基礎的な勉強だったのでパスします。
この行列を使って次に重回帰分析の講義に移ります。
とりあえず1 Weekはこんな感じで終わりです。
まとめ
なんか間違ってる部分もある気がしますがとりあえずここまで。
ご飯食べたら2Week分をまとめます。
はぁ、しんどいなぁ。勉強以外にも就活もちゃんとしなきゃ
ではではノシ