オチも山場もない5日間で1ツール作る記録
なんか新しいことやりたいな。どうせならお仕事でつかえるもの
→OPLOG整形しようかな。
Oplog とは弊社プロダクト用語。csv に日時、操作者、操作機能 と余計なデータがごちゃごちゃ入ってる操作ログです。何時にトラブルが起こったとかいうときにももらうこともある。「オペレーションログ」です。
自分の幸せを追求するのが一番モチベーションにもよい。とりあえず日時でソートされるだけでも嬉しい。マイペースでもたもた始めようと思った。
弊社のカレンダーはこれ:
Develop fun!を体現する Works Human Intelligence Advent Calendar 2020
Develop fun!を体現する Works Human Intelligence #2 Advent Calendar 2020
何使おう
候補はこの辺
1.触ったことないのでGo
https://qiita.com/noborus/items/f253961cca6f4465f20c
https://golang.org/
2.データ加工といえばpythonらしいのでPython
3.普通にjava
1日目はここまで。
2日目
https://www.python.org/downloads/
ひとまずPython3.9を入れた。
https://qiita.com/AI_Academy/items/b97b2178b4d10abe0adb
本当は5時間も使いたくないですが一旦これ見てみよう。
# この行はコメントです。この行は実行されません。
print("Hello, Python")
# この行はコメントです。この行は実行されません。
# この行はコメントです。この行は実行されません。
を作ってコマンドプロンプトで test.py と打つと怒られたぞ
C:\workspace\Python\playground>test.py
SyntaxError: Non-UTF-8 code starting with '\x82' in file C:\Users\works\Desktop\workspace\Python\playground\test.py on line 1, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
素人さんかーい。UTF-8で保存し直してHello, Python 成功
からの?
py -m pip install pandas
https://data-flair.training/blogs/install-pandas-on-windows/
これでPandasがインストールできた?
https://note.nkmk.me/python-pandas-to-csv/
とりあえずこの辺を試したいがその前に、pythonのエディタって何が良いのかな。
→VScodeを入れました。
https://code.visualstudio.com/
何も考えず
import pandas as pd
と書いてみたがエラーが出た
RuntimeError: The current Numpy installation ('C:\\Users\\works\\AppData\\Local\\Programs\\Python\\Python39\\lib\\site-packages\\numpy\\__init__.py') fails to pass a sanity check due to a bug in the windows runtime. See this issue for more information: https://tinyurl.com/y3dm3h86
3日目
RuntimeError: The current Numpy installation (中略) fails to pass a sanity check due to a bug in the windows runtime. See this issue for more information: https://tinyurl.com/y3dm3h86
の原因を探る。
for more information を見ると以下。
https://developercommunity.visualstudio.com/content/problem/1207405/fmod-after-an-update-to-windows-2004-is-causing-a.html
use numpy==1.19.3 works ?
https://qiita.com/bear_montblanc/items/b4b75dfd77da98076da5
ググったらまんまこれ
あまり根拠がわからず信じるのは何だがそのままやってみる
→エラーが消えた。えー。
CSVのソートをしたい
https://note.nkmk.me/python-pandas-sort-values-sort-index/
に戻る。チュートリアル通り
import pandas as pd
df = pd.read_csv('sample_pandas_normal.csv', index_col=0)
print(df)
で、実行。
C:\workspaces\playground>firstpandas.py
age state point
name
Alice 24 NY 64
Bob 42 CA 92
Charlie 18 CA 70
Dave 68 TX 70
Ellen 24 CA 88
Frank 30 NY 57
おー、でた。これにソートを掛けてみる。こんなんでよいの?
import pandas as pd
df = pd.read_csv('sample_pandas_normal.csv', index_col=0)
df.sort_values('age')
print(df)
結果、変わらない。いや感覚でやっちゃ良くない。。
まず公式ドキュメントはこの辺
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.sort_values.html
もう一度。
結論から書くと、これでイメージが付いた。
import pandas as pd
df = pd.read_csv('sample_pandas_normal.csv')
print(df)
df_s = df.sort_values('age')
print(df_s)
C:\workspaces\playground>firstpandas.py
name age state point
0 Alice 24 NY 64
1 Bob 42 CA 92
2 Charlie 18 CA 70
3 Dave 68 TX 70
4 Ellen 24 CA 88
5 Frank 30 NY 57
name age state point
2 Charlie 18 CA 70
0 Alice 24 NY 64
4 Ellen 24 CA 88
5 Frank 30 NY 57
1 Bob 42 CA 92
3 Dave 68 TX 70
Pythonの文法からもっかいおさらいしたほうが良いね
Python3チートシート(基本編)
Pythonチートシート 基本要素編(@IT)
Pandas 公式チートシートを翻訳しました
一旦ここまで。
日付でソートしてみる
さて用いるCSVをちょっと変えて、日付カラムを足した。
name,age,state,point,birthday
Alice,24,NY,64,1996/1/2
Bob,42,CA,92,1978/2/2
Charlie,18,CA,70,2002/3/4
Dave,68,TX,70,1952/1/1
Ellen,24,CA,88,1996/1/5
Frank,30,NY,57,1990/5/15
import pandas as pd
df = pd.read_csv('sample_pandas_date.csv')
print(df)
df_s = df.sort_values('birthday')
print(df_s)
これでどうなるのかというと結果以下。
C:\workspaces\playground>firstpandas.py
name age state point birthday
0 Alice 24 NY 64 1996/1/2
1 Bob 42 CA 92 1978/2/2
2 Charlie 18 CA 70 2002/3/4
3 Dave 68 TX 70 1952/1/1
4 Ellen 24 CA 88 1996/1/5
5 Frank 30 NY 57 1990/5/15
name age state point birthday
3 Dave 68 TX 70 1952/1/1
1 Bob 42 CA 92 1978/2/2
5 Frank 30 NY 57 1990/5/15
0 Alice 24 NY 64 1996/1/2
4 Ellen 24 CA 88 1996/1/5
2 Charlie 18 CA 70 2002/3/4
それっぽくなってきた。
そろそろ本当の操作ログを用いてみよう。
と、実際のCSVを置いてみたらやっぱりエラーが出た。盛り上がってきたところで一旦ここまで。
C:\workspaces\playground>firstpandas.py
Traceback (most recent call last):
File "C:\workspaces\playground\firstpandas.py", line 3, in <module>
df = pd.read_csv('oplog20201112.csv')
File "C:\Users\works\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\io\parsers.py", line 688, in read_csv
return _read(filepath_or_buffer, kwds)
File "C:\Users\works\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\io\parsers.py", line 454, in _read
parser = TextFileReader(fp_or_buf, **kwds)
File "C:\Users\works\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\io\parsers.py", line 948, in __init__
self._make_engine(self.engine)
File "C:\Users\works\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\io\parsers.py", line 1180, in _make_engine
self._engine = CParserWrapper(self.f, **self.options)
File "C:\Users\works\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\io\parsers.py", line 2010, in __init__
self._reader = parsers.TextReader(src, **kwds)
File "pandas\_libs\parsers.pyx", line 537, in pandas._libs.parsers.TextReader.__cinit__
File "pandas\_libs\parsers.pyx", line 740, in pandas._libs.parsers.TextReader._get_header
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x83 in position 0: invalid start byte
4日目
CSVを読み込んだらエラーが出ましたよ
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x83 in position 0: invalid start byte
CSVはこんな(マスクしています)
ユーザーID,クライアント名,WindowsログインID,端末ID,IP Address,MAC Address,ドメイン名,ログイン時刻,ログアウト時刻,ログインステータス,アクション,機能名,実行ファイル名(シェル),引数(コマンドライン),実行時刻,実行状態
"all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","プログラム","ジョブ監視","Job.exe","-context:*****","2020/11/12 13:19:23","成功"
"all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","プログラム","メインメニュー","Companyxx.exe","-cfg","2020/11/12 13:18:56","成功"
"all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","プログラム","システム設定","Maintenance.exe","-context:*****","2020/11/12 13:19:19","成功"
"all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","バッチジョブ","mst13","svc.sh","userid/password","2020/11/12 13:19:32","成功"
"all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","バッチジョブ","mst13","test.sh","userid/password 0 0","2020/11/12 13:19:29","成功"
"all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","バッチジョブ","mst13","test.sh","userid/password 0 0","2020/11/12 13:19:30","成功"
"all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","バッチジョブ","mst13","out.sh","userid/password %JAVA% 0","2020/11/12 13:19:31","成功"
"all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","プログラム","ジョブ管理","quevw.exe","-context:*****","2020/11/12 13:19:20","成功"
"all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","プログラム","batchjob jobid:498298","test.sh","userid/password 0 0","2020/11/12 13:19:56","成功"
"all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","プログラム","batchjob jobid:498301","svc.sh","userid/password","2020/11/12 13:21:39","成功"
まあ日本語含まれてたしね。エンコードが必要。
全然関係ないけど
Python 新型コロナのcsvファイルを題材にpandasでデータ処理する
というのもあって面白そう。
一旦確認のためテキストをUTF-8にエディタで変えたら読込成功。
お、これこのまま日時カラムでソートしてみる?
import pandas as pd
df = pd.read_csv('oplog20201112.csv')
print(df)
df_s = df.sort_values('実行時刻')
print(df_s)
結果、結構普通に実行時刻でソートしてくれた。なるほど。
CSVを別名で保存してみよう。
このページに戻る。
https://note.nkmk.me/python-pandas-to-csv/
import pandas as pd
df = pd.read_csv('oplog20201112.csv')
# print(df)
df_s = df.sort_values('実行時刻')
# print(df_s)
df_s.to_csv('out.csv')
これに先程のエンコード問題を以下で対処。
https://note.sngklab.jp/?p=435
import pandas as pd
df = pd.read_csv('oplog20201112.csv',encoding="SHIFT-JIS")
print(df)
df_s = df.sort_values('実行時刻')
print(df_s)
df_s.to_csv('out.csv')
実行時刻カラムを一番左に持ってきたい
続いてカラムを動かす方法。
https://note.nkmk.me/python-pandas-reindex/
見たまんま、それらしくなりました。
import pandas as pd
df = pd.read_csv('oplog20201112.csv',encoding="SHIFT-JIS")
# print(df)
df_s = df.sort_values('実行時刻')
# print(df_s)
df_s = df_s.reindex(columns=['実行時刻',
'機能名',
'ユーザーID',
'クライアント名',
'WindowsログインID',
'端末ID',
'ログイン時刻',
'ログアウト時刻'])
df_s.to_csv('out.csv')
ツールの配布
作ったものをどうやって使いやすくすればいいのかも見ておきたい。
pyintallerというものがあるんだな。
set path=C:\Users\works\AppData\Local\Programs\Python\Python39\Scripts;%path%
が先に必要なので注意。
コマンドプロンプトで
C:\workspaces\playground>pyinstaller firstpandas.py --onefile
67 INFO: PyInstaller: 4.0
67 INFO: Python: 3.9.0
69 INFO: Platform: Windows-10-10.0.19041-SP0
70 INFO: wrote C:\workspaces\playground\firstpandas.spec
(後略)
とすると無事Exeができました。
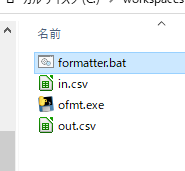
*.batをつくる
cd /d %~dp0
call firstpandas.exe
同フォルダにはこんな感じ
in.csv を読み込んで out.csv にするだけの firstpandas.exe がいます。
実際もらうファイルは in.csv でもなんでも無いので今度は*.batで引数で受け取ったcsvをin.csvにしてやるとかかなあ。
カラムの存在チェック
ところでファイル形式にいくつか種類があったので変更。
How to check if a column exists in Pandas
https://stackoverflow.com/questions/24870306/how-to-check-if-a-column-exists-in-pandas
import pandas as pd
df = pd.read_csv('oplog20201112.csv',encoding="SHIFT-JIS")
# print(df)
if '実行時刻' in df:
df_s = df.sort_values('実行時刻')
df_s = df_s.reindex(columns=['実行時刻',
'機能名',
'ユーザーID',
'クライアント名',
'WindowsログインID',
'端末ID',
'ログイン時刻',
'ログアウト時刻'])
if 'PRC_DATE' in df:
df_s = df.sort_values('PRC_DATE')
df_s = df_s.reindex(columns=['PRC_DATE',
'DETAIL1',
'USERID',
'TERM_ID'])
df_s.to_csv('out.csv')
ファイルのエンコード
以下が出る時がある。
UnicodeDecodeError: 'shift_jis' codec can't decode byte 0x87 in position 22224: illegal multibyte sequence
と思っていたが、
pandasにexcel出力のcsvを読ませる時に注意する点
https://minus9d.hatenablog.com/entry/2015/07/30/225841
https://stackoverflow.com/questions/6729016/decoding-shift-jis-illegal-multibyte-sequence
に倣いencodingを更に変更。
import pandas as pd
# df = pd.read_csv('in.csv',encoding="SHIFT-JIS")
df = pd.read_csv('in.csv',encoding="shift_jisx0213")
# print(df)
if '実行時刻' in df:
df_s = df.sort_values('実行時刻')
df_s = df_s.reindex(columns=['実行時刻',
'機能名',
'ユーザーID',
'クライアント名',
'WindowsログインID',
'端末ID',
'ログイン時刻',
'ログアウト時刻'])
if 'PRC_DATE' in df:
df_s = df.sort_values('PRC_DATE')
df_s = df_s.reindex(columns=['PRC_DATE',
'DETAIL1',
'USERID',
'TERM_ID'])
df_s.to_csv('out.csv')
ほか参考
https://techacademy.jp/magazine/23367
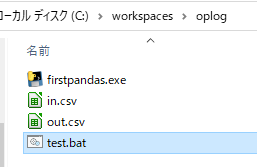
最終的に
cd /d %~dp0
copy %1 in.csv
call ofmt.exe
echo "see out.csv!"
pause
こんな感じになりましたとさ