dashDB & Rを使ったデータ分析をはじめてみる 基礎編(アソシエーション分析)
今回からクライアント環境に導入したR Studioを使用してdashDB In-database Analytics 関数を使用したデータ分析を進めてみたいと思います。基礎編ということで、dashDB R ライブラリのインストールから、どのようにRプログラムを記載するのか?というレベルから記載していきます。
また今回はサンプルシナリオとして、架空のアウトドア会社の売上明細表と製品マスタ表を元に、販売製品の併売傾向を分析するケース(アソシエーション分析)を例にして、dashDB In-database Analytics関数がどのように使えるか紹介していきます。
①.dashDB & Rを使用したデータ分析のために必要なライブラリ
dashDBのin-database Analytics関数を使用するためには「ibmdbR」というパッケージのダウンロードをCRANから実施する必要があります。R Studionのパッケージインストールからこちらは可能です。他のRパッケージとの依存関係は下記の通りです。
install.packages("ibmdbR")
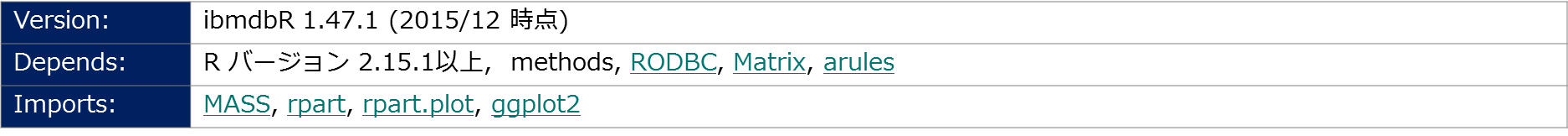
②.RODBCを使用したdashDB接続設定を行う。
ODBCドライバ名やデータベース名等の情報については、dashDBにログインして、『Connect』タブの『Connect Information』をクリックするとdashDB ODBC接続情報、OS別ドライバのダウンロード先へのリンクの参照できるようになっています。ユーザー名とパスワードはdashDBへの接続するユーザーのIDとパスワードになります。
library(ibmdbR)
driver.name <- “{ODBCドライバ名}" #IBM DB2 ODBC DRIVER
db.name <- “データベース名"
host.name <- “ホスト名"
port <-“ポート番号"
user.name <-“ユーザー名”
pwd <- “パスワード"
con.text <- paste("DRIVER=",driver.name, ";Database=",db.name, ";Hostname=",host.name, ";Port=",port, ";PROTOCOL=TCPIP", ";UID=", user.name, ";PWD=",pwd,sep="")
con <- odbcDriverConnect(con.text)
参考: dashDB Web Consoleログイン ⇒ Connect ⇒ Connect Information
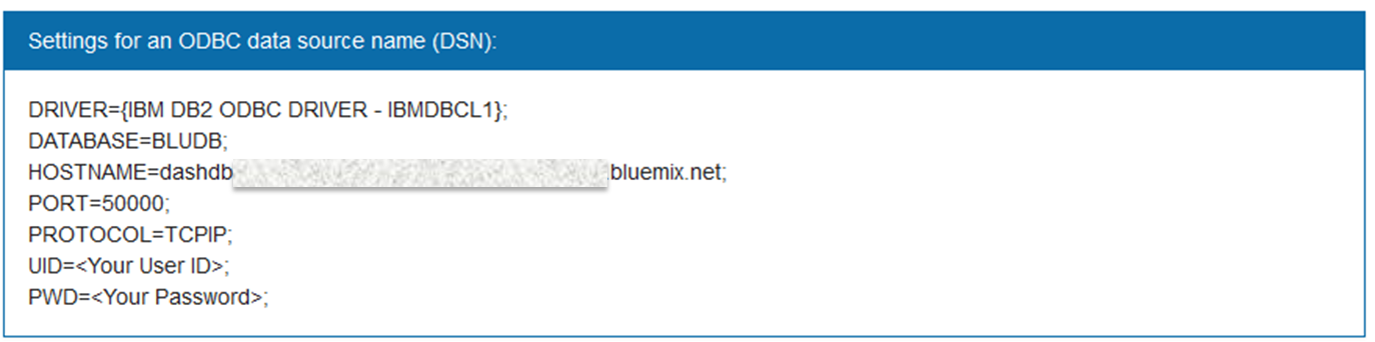
もしくはODBCデータソースとして事前に接続定義を作成している場合は下記構文から接続可能です。
con <- idaConnect(“dashDB”, “”, “”)
※『dashDB』はODBCシステムリソース名。接続定義は事前に記載必要です。ODBC設定はWindows7であればコントロールパネル⇒管理ツール⇒データソース(ODBC)で設定できます。
③.dashDBへのODBC接続定義を初期化します。
idaInit(con)
④.IDAデータフレームの作成
例として、dashDB上のORDER_DETAILS表を使用したIn-DBデータフレーム(IDAデータフレーム)オブジェクトを作成してみます。今回はORDER_DETAILS_40M表の2列とproduct表の2列を参照するIDAデータフレームオブジェクトを作成しています。これらのオブジェクトはDBの中で処理されます。ORDER_DETAILS_40M表は架空のアウトドア製品会社の4000万件の売上明細データとproduct表はアウトドア関連の製品マスタを指しています。
orderDetails <-ida.data.frame(‘ORDER_DETAILS_40M’),c('PRODUCT_NUMBER','ORDER_NUMBER')]
product <- ida.data.frame('PRODUCT'),c('PRODUCT_NUMBER','PRODUCT_TYPE_CODE')]
⑤.IDAデータフレームオブジェクトをマージする
次にorderdetailsとproducts IDAデータフレームをproduct_number列の値で結合させてみます。記述方法としては下記の通り、通常のRのmergeと記述の仕方はほぼ同じですが、データはDBの中で全て処理されています。
orderDetails2 <- idaMerge(orderDetails,product,'PRODUCT_NUMBER')
head(orderDetails)
PRODUCT_NUMBER ORDER_NUMBER PRODUCT_TYPE_CODE
1 68110 700193 961
2 70240 700193 961
3 71110 700193 961
・・・
⑥.アソシエーション分析モデルの作成
下記は⑤で作成したorderDetails2 IDAデータフレームを使用した相関ルールモデルの作成処理です。トランザクションIDにORDER_NUMBER, アイテムにPRODUCT_TYPE_CODEを指定、表記をわかりやすくするため、nametable,namecolとの紐付けを実施しています。inspect(モデル名)で確認するとどの製品が同時に購買されているのか傾向を示す値(support, confidence,lift)を確認することができます。
r <- idaArule(orderDetails2,tid="ORDER_NUMBER",item="PRODUCT_TYPE_CODE",minsupport=0.05,maxlen=2,nametable = "PRODUCT_TYPE",namecol = "PRODUCT_TYPE_EN")
inspect(r)
lhs rhs support confidence lift
1 {Cooking Gear} => {Tents} 0.06406790 0.5154857 5.194457
2 {Tents} => {Cooking Gear} 0.06406790 0.6456008 5.194457
3 {Cooking Gear} => {Sleeping Bags} 0.06495043 0.5225865 5.241218
・・・
ちなみにsupport, confidence, liftについて1行目の結果で説明すると製品「Cooking Gear」を買ったお客様が製品「Tents」を買った全体の割合は6.4%となります。またCooking Gearを購入された顧客がTentsを購入した顧客の発生割合が51%という結果になっています。相関ルールは、support、confidence、Liftの値を元に各製品が合わせて購入される傾向を見るものですが、単純に各指標の値だけ見て判断できない側面もあるため、実際に有効なデータであるかの判断はビジネス現場での判断も重要になります。
相関ルール自体の説明については、こちらのサイトの説明が非常にわかりやすいです。
⑦.アソシエーション分析モデルの適用
次に⑥で作成した分析モデルの適用を行い結果をheadを使用して参照してみます。モデル適用にはidaApplyRule関数を使用することが可能です。IDAデータフレームを使用した処理となるため、こちらもDB内で処理が可能です。
q <- idaApplyRules(idaGetModelname(r),orderDetails2,"ORDER_NUMBER","PRODUCT_TYPE_CODE")
head(q)
ORDER_NUMBER RANK RULEID PRINT LENGTH SUPPORT LIFT CONFIDENCE
1 100001 1 16 (Eyewear) => (Watches) 2 0.61940439 1.225006 0.8340371
2 100002 1 15 (Watches) => (Eyewear) 2 0.61940439 1.225006 0.9097603
3 100003 1 16 (Eyewear) => (Watches) 2 0.61940439 1.225006 0.8340371
・・・
上記分析結果から今回使用したサンプルデータからは、EyewearとWatchesの相関関係の強さがわかりますね。supportの値が約61%、confidenceの値が90%という結果になっていることから、1つ分析結果として解釈することができます。
⑧.作成したオブジェクトの削除、接続クローズ
最後に作成した表、モデルといったオブジェクトをDBから削除して接続をクローズさせたいと思います。それぞれ下記のような形でRプログラムで実装することが可能です。
idaDeleteTable(orderDetails2)
idaDropModel(idaGetModelname(r))
idaClose(con)
このようにRプログラムと同じような文法構造でありながら、処理自体はDBの中で行わせることができる点がdashDB In-database Analyticsのメリットにもなります。Rになじみのある記載方式なので使用にあたりそこまでハードルは高くないと思います。もちろんdashDB側のテクノロジーについてある程度把握しておくと、どのような処理をDBサーバー側でやらすと効果的か予測がしやすくなるので、知っておくことに越したことはありません。
以上、今回は終了です。次はK-meansやベイズといった分析基礎編、dashDB MPPによる大量データ分析処理の実施例をアップしていきたいと思います。
⑨.参考:サンプルRスクリプト
最後に今回のdashDB & R アソシエーション分析で使用したRスクリプトを参考までにのせておきます。こちらはdashDBのサンプルとして記載がありますので、全体を記載すると下記となります。
library(arulesViz)
library(ibmdbR)
con <- idaConnect('dashDB','','')
idaInit(con)
orderDetails <- ida.data.frame('XXXXX.ORDER_DETAILS_40M')[,c('PRODUCT_NUMBER','ORDER_NUMBER')]
products <- ida.data.frame('XXXXX.PRODUCT')[,c('PRODUCT_NUMBER','PRODUCT_TYPE_CODE')]
orderDetails2 <- idaMerge(orderDetails,products,'PRODUCT_NUMBER')
head(orderDetails2)
r <- idaArule(orderDetails2,tid="ORDER_NUMBER",item="PRODUCT_TYPE_CODE",minsupport=0.05,maxlen=2,nametable = "XXXXX.PRODUCT_TYPE",namecol = "PRODUCT_TYPE_EN")
inspect(r)
jpeg('graph.jpeg')
plot(r,"graph")
dev.off()
jpeg('grouped.jpeg')
plot(r,"grouped")
dev.off()
q <- idaApplyRules(idaGetModelname(r),orderDetails2,"ORDER_NUMBER","PRODUCT_TYPE_CODE")
head(q)
idaDeleteTable(orderDetails2)
idaDropModel(idaGetModelname(r))
idaClose(con)