1. はじめに
12月8日にgoogle sheetで機械学習機能がリリースされたというツイートがありました。2つに分類する問題を試してみました。防備録として使う手順から記載しておきます。
2. 必要なもの
これを試すのに必要なもの
- gogole アカウント
- google ドライブの空き容量 10kB程度
- google ドライブが表示できるパソコン、ブラウザ、インターネット接続
3. 準備
3.1. google driveを表示
ブラウザからgoogleドライブを表示されるところまで進めましょう。(ログインして、ドライブを表示)
3.2. Simple ML for Sheetsのインストール
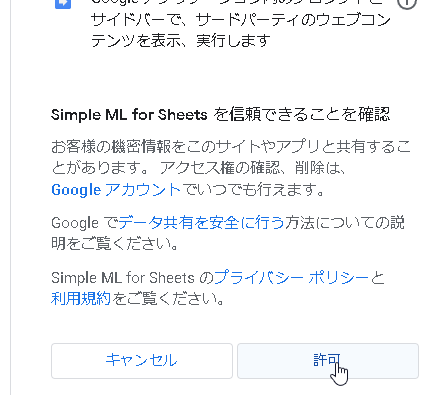
インストールといっても、導入先はPCではなく、自分のgoogle アカウントで使えるようにする設定です。
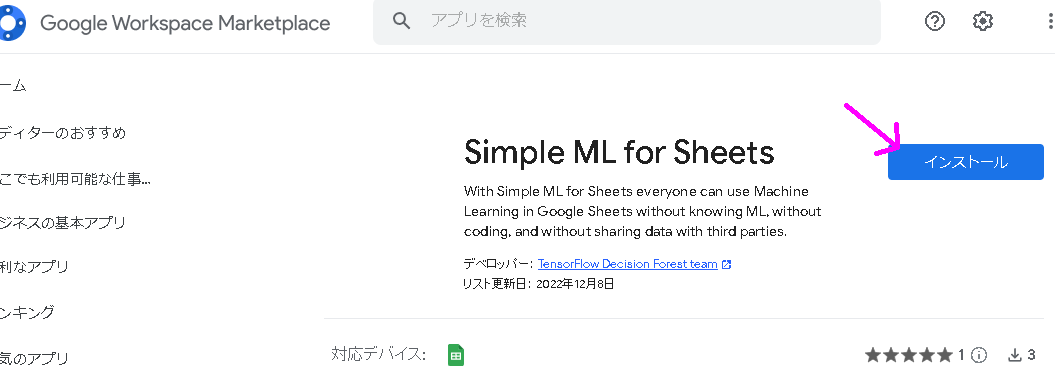
まずは次のページを開き、インストールボタンを押します。
Simple ML for Sheets : https://workspace.google.com/marketplace/app/simple_ml_for_sheets/685936641092


3.3. spread sheetの起動
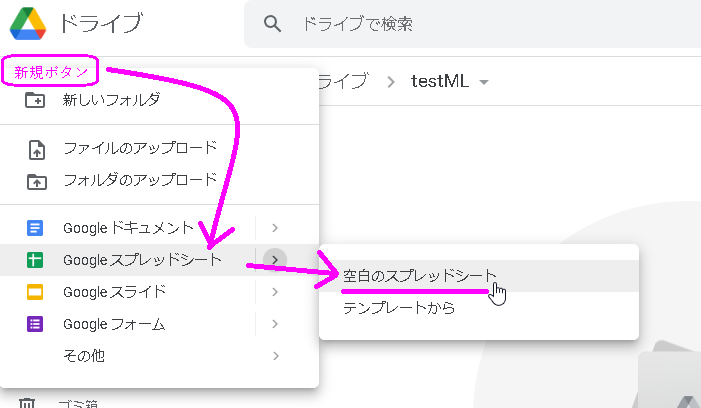
googleドライブをブラウザで表示すると左上に「+ 新規」というボタンがあるので、それをクリックすると何を新規作成するか選べますので、スプレッドシートを選択します。
4. 試す
4.1. とにかく試す
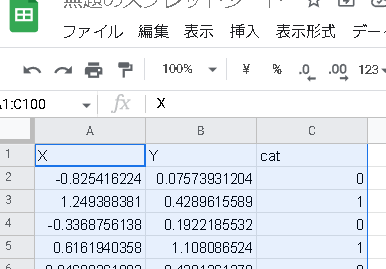
次のデータを使って試してみましょう。次のテストデータを選択してコピーします。
テストデータ
"X" "Y" "cat"
-0.825416224 0.07573931204 0
1.249388381 0.4289615589 1
-0.3368756138 0.1922185532 0
0.6161940358 1.108086524 1
0.04609361803 0.4301361378 0
1.059208472 0.4474787515 1
0.7367512309 1.091792978 1
0.7021591375 0.1748152031 0
1.384239752 0.6547356968 1
0.03274923288 -0.1933859409 0
0.771060167 0.7204931665 1
1.282602147 0.849983385 1
-0.1794354323 -0.06256786209 0
1.157406832 1.307767081
-0.2193602027 -0.1635002739
1.410894881 1.534081877
1.453140959 1.055560773
-0.6886210873 0.02101007827
1.474555028 1.028984672
-0.3680525174 1.109670281
1.538453674 1.546728593
0.6165237006 0.5861084148
-0.04026659597 -0.2915281699
0.9704754216 0.9463725078
-0.04202477207 -0.001282190986
1.249722169 1.837572681
1.264105562 1.604737188
0.1252783394 -0.4201858209
スプレッドシートのA1にカーソルを合わせ、ペーストします。
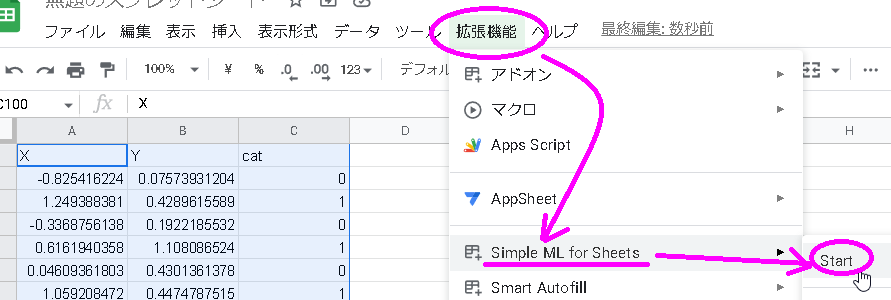
メニューバーの右の方にある「拡張機能」をクリックし、数秒間待つと、メニューの下に「simple ML for sheets」という項目が現れます。それをクリックしてstartし、30秒程度待ちます。
右に設定画面が現れます。「Predict missing values」と「cat」が表示されていることを確認します。そうでなければ、それらを選びます。
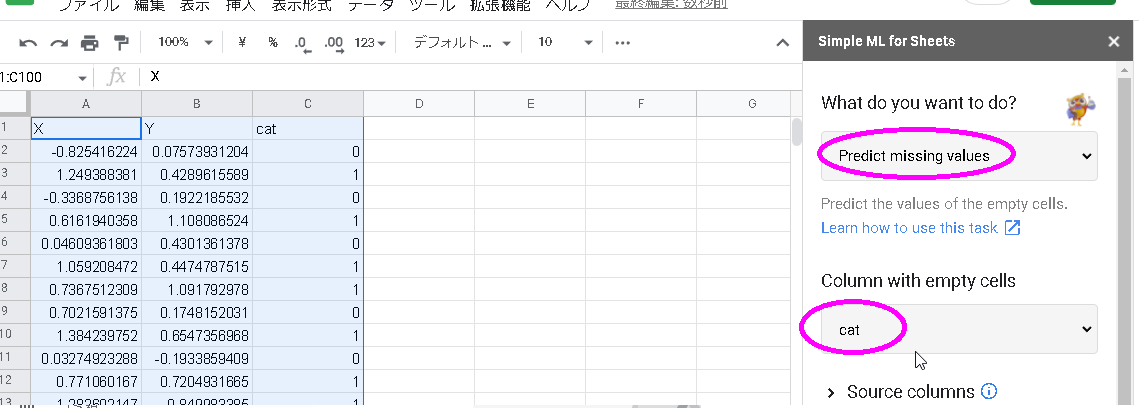
「Source columns」クリックし、XとYが選ばれていることを確認します。他が選ばれていたり、足りない場合は、そのようになるように設定します。
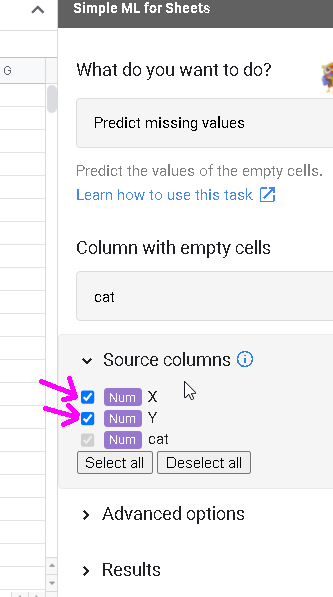
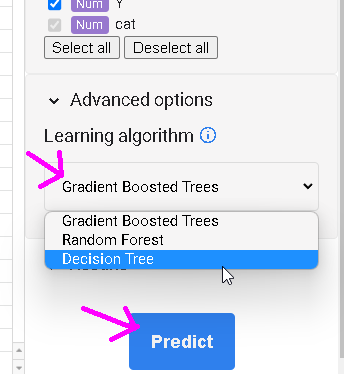
「Predict」ボタンを押すと始まります。もし、アルゴリズムを変えたい場合はAdvanced optionsをクリックして指定します。
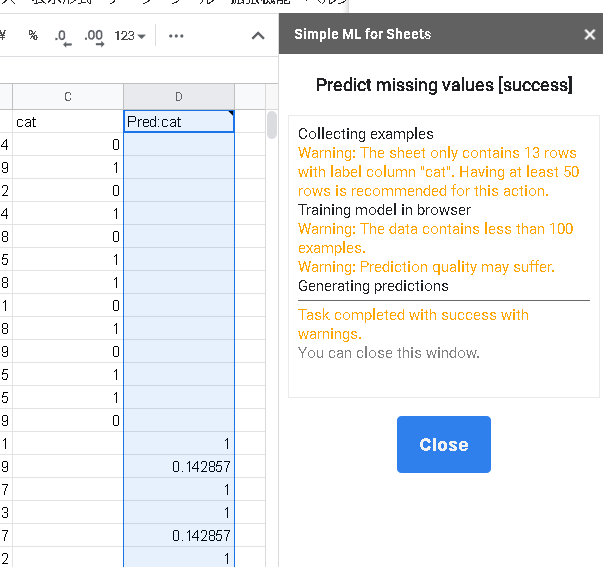
30秒程度待つと結果が表示されます。
この処理は何をしたかというと、次のような画面を見ると判るかもしれません。
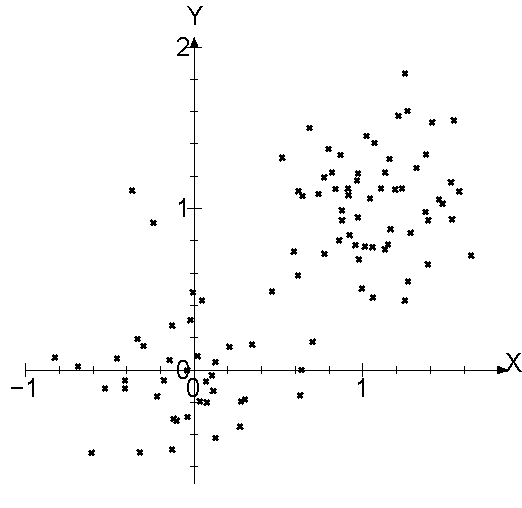
これは、XとYの値で作った散布図です。眺めていると2つのグループに見えると思います。元のデータは、ラベルが0と1の2種類がランダムに並んでおり、(x,y)で(0,0)と(1,1)にプロットさせ、そこにノイズが乗せています。catの列では、正解を10個与えて、残りを予測させてみた結果です。1の方はしっかりと1と出てますが、0の方はなんとなく0という弱気な値です。
4.2. ちょっと変える
元のデータは次のシートを使って生成しました。
新しいシートを用意して、次のテキストをコピーして、A1セルにペーストします。
データ生成用tsvファイル
"_" "param1" "param2" "param3" "LCG_1" "LCG_2" "LCG_3" "BoxMuller_I" "BoxMuller_Q" "Quantize" "X" "Y"
"multiplier" 3 20 21 3 50 12 =SQRT(-2*LN(E2/B$4+2^(-10)))*COS(2*PI()*F2/C$4) =SQRT(-2*LN(E2/B$4+2^(-10)))*SIN(2*PI()*F2/C$4) =rounddown(g2/D$4+0.5) =J2*B$10+H2*B$11 =J2*C$10+I2*C$11
"increment" 5 11 13 =MOD(E2*B$2+B$3,B$4) =MOD(F2*C$2+C$3,C$4) =MOD(G2*D$2+D$3,D$4)
"modulus" 101 103 105
"usage : copy E3,F3,G3 to bottom cell"
"modulus are equal to max length"
"E2,F2,G2 are initial value"
"H2,I2 are Box-Mullr method"
"J2 is quantization"
"K2,L2 are X-Y plot example" 1 1
"noise factor" 0.314 0.314
ペーストしたら、次は、セルE3,F3,G3を選択して、下にコピーします。100個ぐらいが上限です。
その次にセルH2,I2,J2,K2,L2を下にコピーします。G列と同じにします。
ここで、K列とL列を選択して散布図を書かせてみると、先ほどのグラフが出てくるのが判ります。
M1にcatと記載し、M2からは、J2と同じ値を下に10個作ります。
これで、始めに試したものと同じ形になります。
catと書いたM列の正解は、Quantizeと書かれたJ列です。
つまり、J列と同じ値が出れば正解です。
このシートで予測する場合は、XとYだけを予測に用いるように、一旦全てチェックを外してから行います。
セルB11とC11の数字を0.2のように小さくすると、正確になりますし、0.5のように大きくすると予測が難しくなります。
5. 考察とメモ
セルB11とC11の数字はノイズの係数で、値を大きくするとノイズが大きくなります。
大きくすると予測が難しくなることが判ります。それは散布図を見れば、明らかです。
ノイズや答えの生成には、疑似乱数を使っています。線形合同法 (Linear congruential generators: LCG)で一様乱数に近いものを作り、Box-Muller法でガウス分布に近いものを作っています。
これらは、それぞれ関数を利用しても良いかと思います。
また、予測のためのアルゴリズムは、決定木など3種類ですが、試す分には十分だろうと思います。それぞれ算出する値が異なる場合がありますので、楽しめます。
6. おわりに
表計算ソフトで機械学習に手軽に触れることができる時代になりました。現在の人工知能AIと呼ばれるものの多くは機械学習で構成されています。
このツールで面白いことができるのではないかとワクワクしている次第です。
A. 修正点
R4.12/8 18:10 : 当初「クラスタ分析」と記載していたのですが、10個答えを与えてから予測しているので、「分類問題」と表現を直しました。クラスタ分析の場合は、k-means法などで、予め決めた群れの重心やその近傍の点を分類します。今回はいわゆる教師ありの方法で、分類に相当していました。