はじめに
チャットボットとは
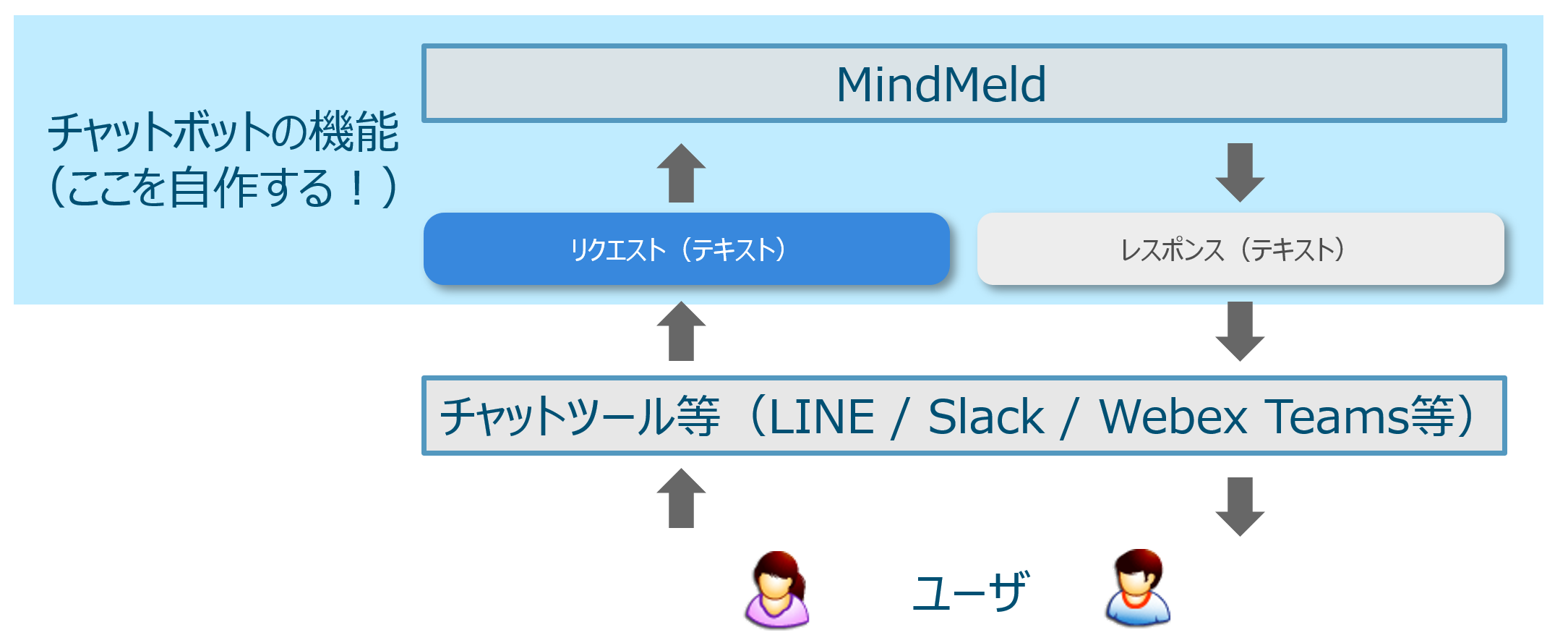
LINE・Slack・Webex Teams 等チャットアプリの会話相手は通常人ですが、最近は機械が会話相手となり賢く回答をしてくれる機能やサービスが増えています。この機械がチャットボットで、今回のテーマはチャットボットのPythonによる自作です。
MindMeld とは
自作する場合、クラウドサービスを使うと制約があるし、かと言って一から開発すると大変な労力が必要です。そこで役に立つのがオープンソースの MindMeld です。チャットボットを自作するための Python ベースのフレームワークです。
こんな場合に使える
MindMeld は残念ながら汎用AIではないので、どんな場合にでもウィットな返答をしてくれるボットは作れません。ただし以下の例のように、用途を限定して、かつ、会話の目的がはっきりしている場合には非常にうまく機能します。
- レストランの注文を受ける
- 航空券の予約を受ける
- 工場等手が使えない場所で音声により定型作業を行う(音声⇔テキスト変換は別途仕組みが必要)
MindMeld の特長
MindMeldは元々シスコシステムズが2017年に買収した企業です。同名のソフトウェアは既にシスコシステムズの製品へ組み込まれていますが、2019年5月にオープンソース化されました。企業ユースに耐えられる品質を兼ね備えますのでニーズがあるなら利用しない手はありません。
機能的な特長の一つとして、適宜ナレッジベースを参照する点が挙げられます。これにより賢くて頼りになるチャットボットが作れます。
なお、ユーザインターフェイスには様々なチャットツールと組合わせることができ、特に MindMeld4.2からは Cisco Webex Teams とのインテグレーションが簡単にできます。が、今回は実験ですのでビルトインのテスト用ツールを使っています。
日本語は未対応
大きな問題点として MindMeld は現時点で日本語対応していません。また、日本語対応に向けた取り組みをしているコミュニティも残念ながら見つかりませんでした。その取っ掛かりを作りたい、というのが本記事の趣旨です。日本語化に向けたアイデア提供が目的であり、完全対応は目指していませんのでご注意ください。
今回行った日本語対応について
今回のデモでは以下3つのコンポーネントを日本語対応させています。
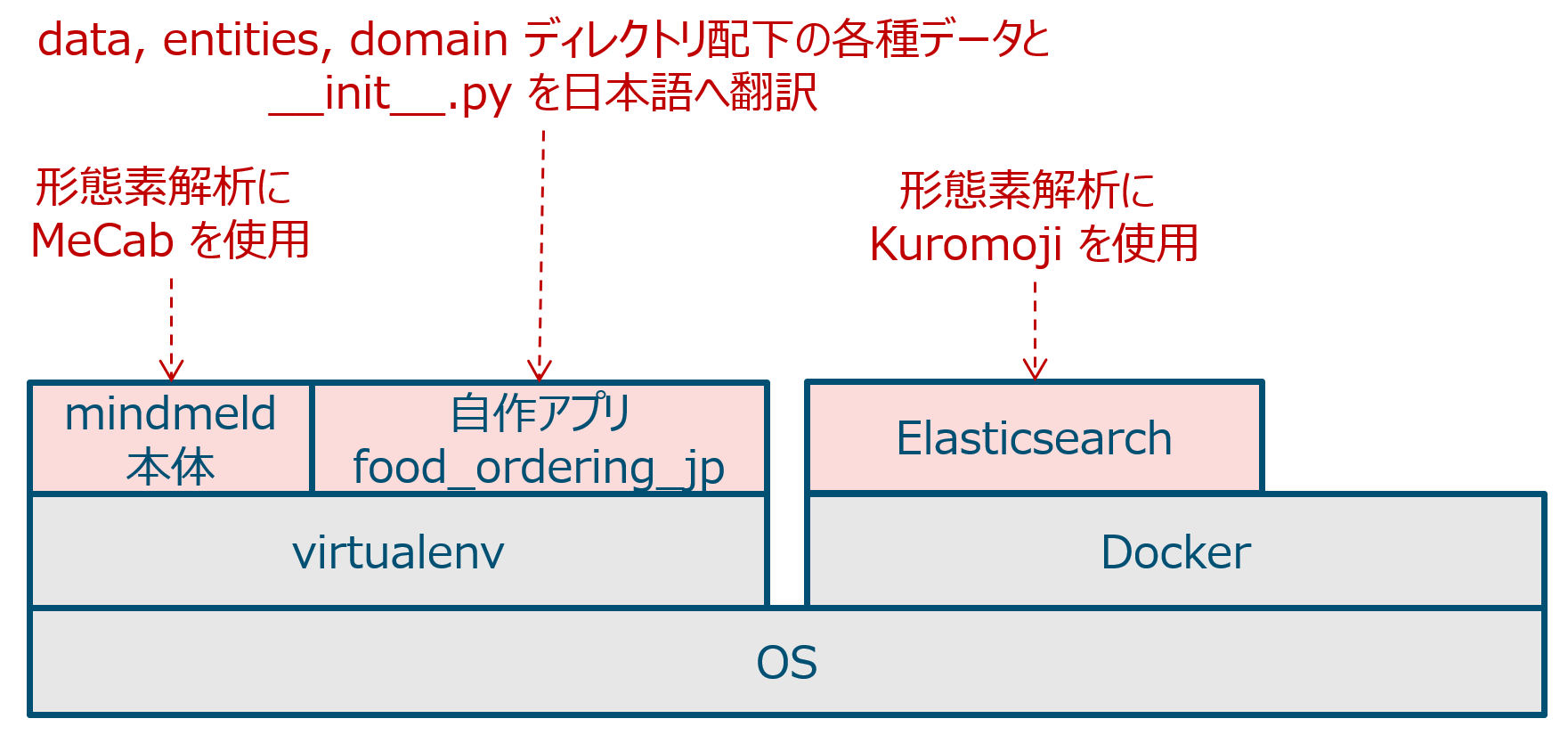
MindMeld 本体
デフォルトの MindMeld は英語で動作するため、リクエストをスペースで区切って単語へ分割します。その役割を担っているのが tokenizer.py の Tokenizer.tokenize_raw() です。下図の様に英語リクエストに対しては正しく動作しますが、日本語リクエストは分割できません。そこで Tokenizer.tokenize_raw_ja() を作ってみました。
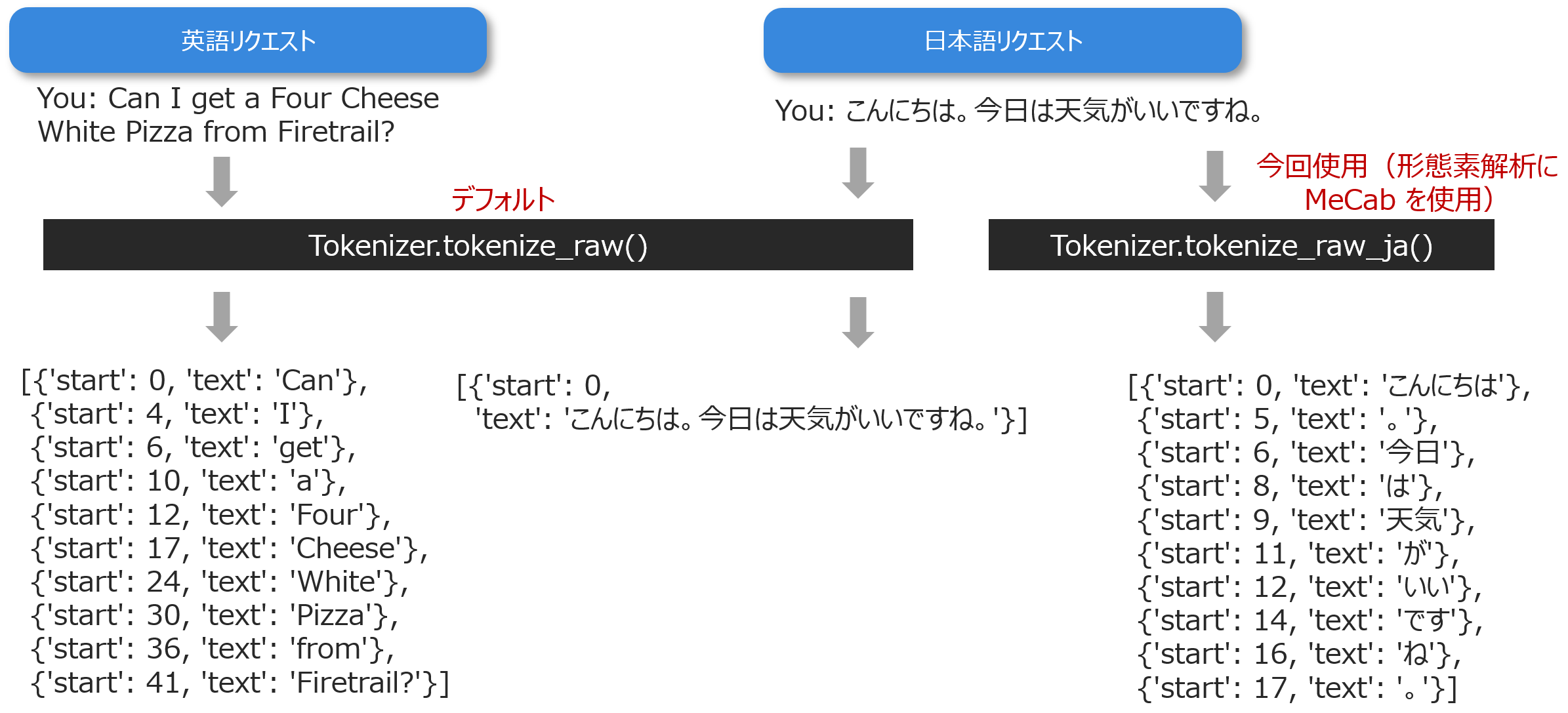
※上図の出力は raw_tokens です。
ElasticSearch
MindMeld のバックエンドでは ElasticSearch が Docker コンテナで動作しており、こちらも形態素解析に対応させる必要があります。今回は Kuromoji を使うようにリビルドしました。
自作アプリ food_ordering_jp
標準サンプル(ブループリント)food_ordering から一部のデータを抜き出し、さらにその一部を日本語へ翻訳しました。データが不完全なのでエラーの出ることがあります。ご注意ください(日本語化の具体的な手順は[後述](# インストール方法))。
利用例を通じて動作原理を理解する
自作アプリの用途
自作アプリ food_ordering_jp の元となる food_ordering の用途は、近所の配達可能なレストランリストの中からメニューを選択して発注する、というものです。が、それっぽく答えるだけで実際には発注しません。
以下実際の会話を通じて MindMeld 動作原理を順に説明していきます。と同時に、説明をした項目は日本語での動作確認が取れた部分でもあります。
今回説明にあたり用意した会話は大きく3ステップに分かれます。
- ステップ1:あいさつ
- ステップ2:レストランとメニューの決定
- ステップ3:発注
ステップ1:あいさつ
注)ビルトインのテスト用ツールの見方
You: は、ユーザの話しかけた言葉(リクエスト)
App: は、MindMeldボットの回答(レスポンス)
例1-1:あいさつ(望ましいレスポンス)
You: こんにちは
App: こんにちは。注文できるレストランの例は次の通りです:ファイアトレイルピザ, バサシーフードエクスプレス, モンクのやかん
例1-2:あいさつ(望ましくないレスポンス)
You: こんにちは。今日は天気がいいですね。
App: 申し訳ないのですが理解できません。'ファイアトレイルのマルゲリータピザを食べたいな'の様に話しかけて下さい。
例1-1は会話が成立していますが、例1-2はユーザの意図を理解できなかったようです。解決を試みる前に、まずは裏側の処理を理解するため MindMeld の内部構成を見てみます。
MindMeld の構成要素を理解する
ユーザのリクエストを受け取ると MindMeld は下図の構成要素を順に使って処理を行い、最終的にレスポンスを回答します。
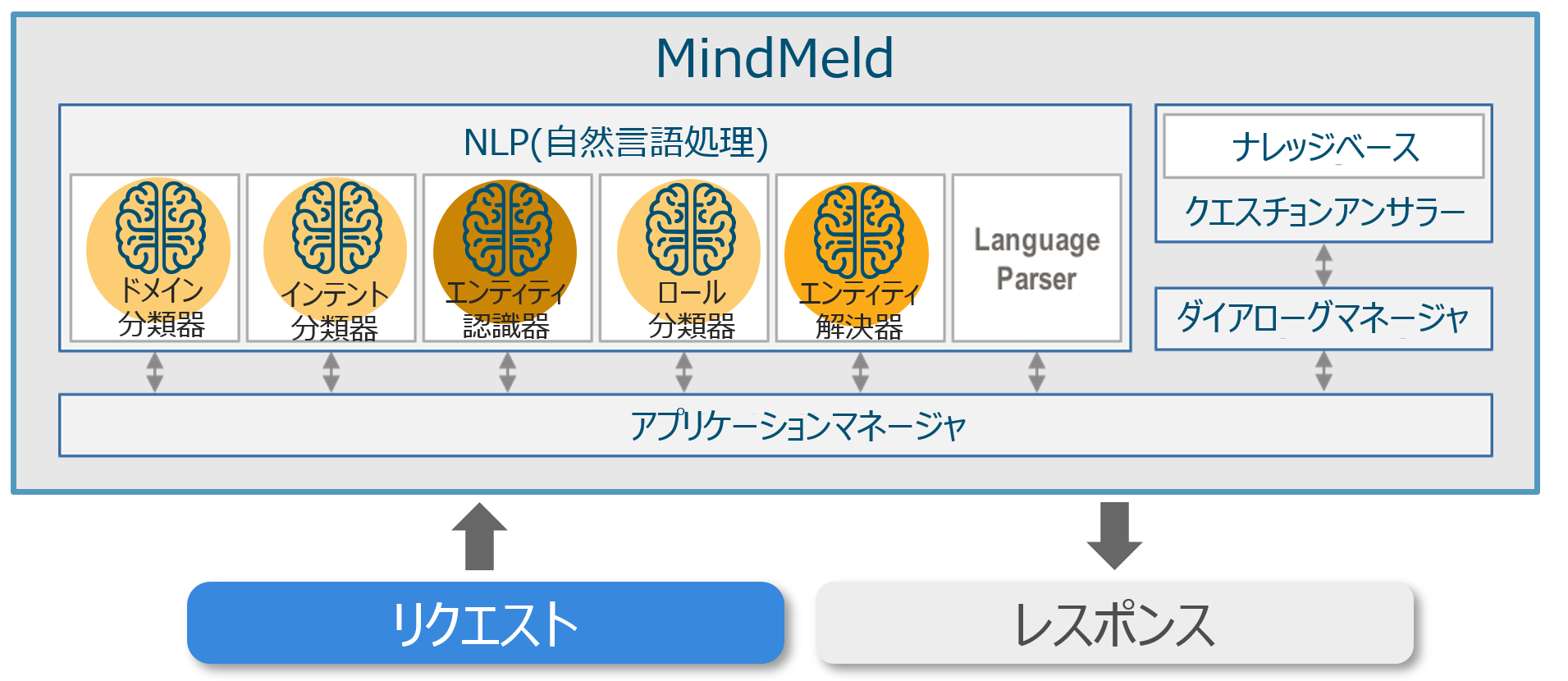
分類器を理解する
上図には分類器が3種存在しています。各分類器の役割は、リクエストを受け取ると、その内容に基づき予め定義したカテゴリーから一つを選択して出力する、というものです。下図はカテゴリー数=2の場合の例です。
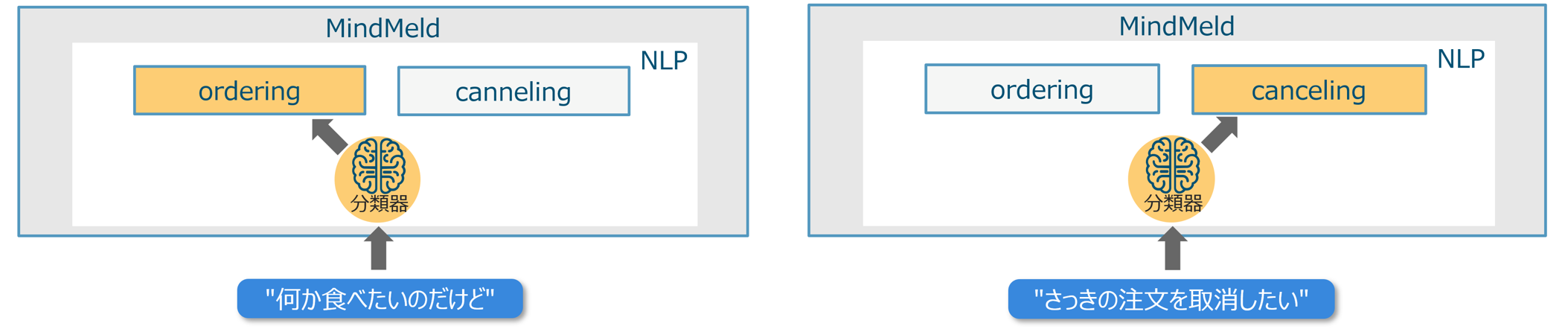
MindMeld ではこのカテゴリーが三種類あり、それぞれドメイン・インテント・ロールと名付けられています。
ドメイン分類器を理解する
MindMeld は用途を限定して初めて効果を発揮します。ユーザのリクエストから用途を大雑把に限定する作業がドメイン分類です。が、今回はドメインを ordering(注文)一つしか作ってませんので全てのリクエストが ordering へ分類されます。
インテント分類器を理解する
インテント分類はユーザの意図(インテント)をより細かく分類する仕組みです。MindMeld はドメイン=ordering へ分類した後、リクエストをインテント分類器にかけて、予め定義された7つのインテントの中から最も相応しいと思われるインテントを1つ選び出します。例1-1で MindMeld はリクエストを greet(あいさつ)へ分類していました。
でも、それはなぜでしょう?
それは、アプリ実行前に分類器へ教師データとなるテキストを渡して学習させておいたからです。例1-1 で greet 用に使用した教師データは下記の通りです:
こんにちは
こんちは
ハロー
はろー
おはよう
おはようございます。
こんばんは
こんにちわ
ごきげんよう
元気?
ヘイ
おはよ
おは
おはよー
今日も寒いね
調子はどう?
元気かい?
おっす
今日は
ハイ
コンニチハ
コンニチワ
一方、例1-2においてはインテント= Unsupported (理解不能)へ分類してしまいました。本来は greet へ分類すべきですので教師データを追加して MindMeld を賢くしましょう。下記教師データを追加して再学習してみます:
こんにちは。今日も寒いですね。
こんにちは。今日は天気がいいですね。
こんにちは。今日は雨が長引いてますね。
こんにちは。雨が止まなくて嫌だ。
こんにちは。晴れて気持ちがいい。
以下は再学習した上での実行結果です:
You: こんにちは。明日は晴れるかな。
App: こんにちは。注文できるレストランの例は次の通りです:ファイアトレイルピザ, バサシーフードエクスプレス, モンクのやかん
正しく greet へ分類されました。ここで注目したいのは、ユーザの「こんにちは。明日は晴れるかな。」の文章そのものが教師データに含まれていない点です。学習結果とリクエスト文章の類似性が高いため greet へ正しく分類されています。機械学習には Scikit-learn のロジスティック回帰(sklearn.linear_model.LogisticRegression)を利用しています。
ドメイン・インテント・エンティティの階層構造を理解する
MindMeld アプリを自作するには予め設計図としてドメイン・インテント・エンティティの階層構造を描く必要があります。下記は今回の自作アプリのものです。
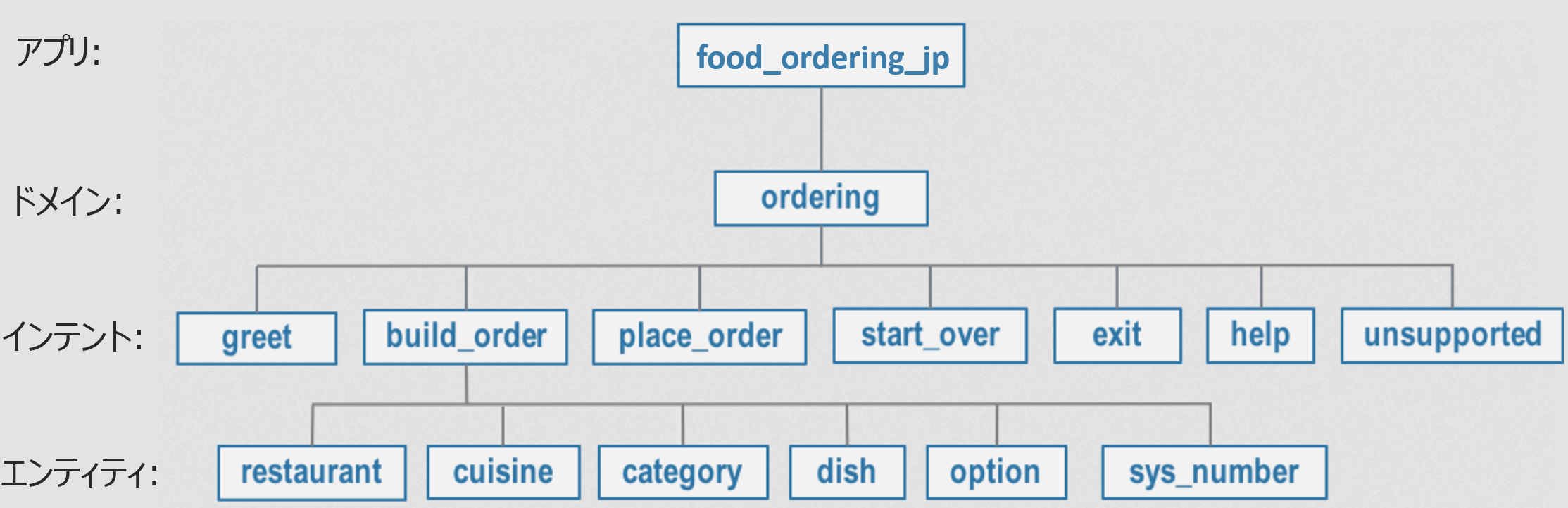
計7つのインテントが定義されています。その他のインテントの例として、下記はインテント= help へ分類された場合のレスポンスです:
You: わからん
App: 近所のレストランへの注文を承ります。例えばこんな風に話しかけて下さい:'ファイアトレイルのマルゲリータピザを食べたいな'の様に話しかけて下さい。
ダイアローグマネージャを理解する
MindMeld ではチャットボットとの会話が一問一答形式ではなく、数往復に渡る会話を通じてユーザの意図を確定させます。その役割を担っているのがダイアローグマネージャです。ダイアローグマネージャはインテント分類の結果に基づいてハンドラを呼び出します。
例1-1 ではインテント=greet へ分類された事実を受け、ダイアローグマネージャがハンドラ=welcome を割当てて実行します。
例1-2 ではインテント=unsupported へ分類された事実を受け、ダイアローグマネージャがハンドラ=default を割り当てて実行します。
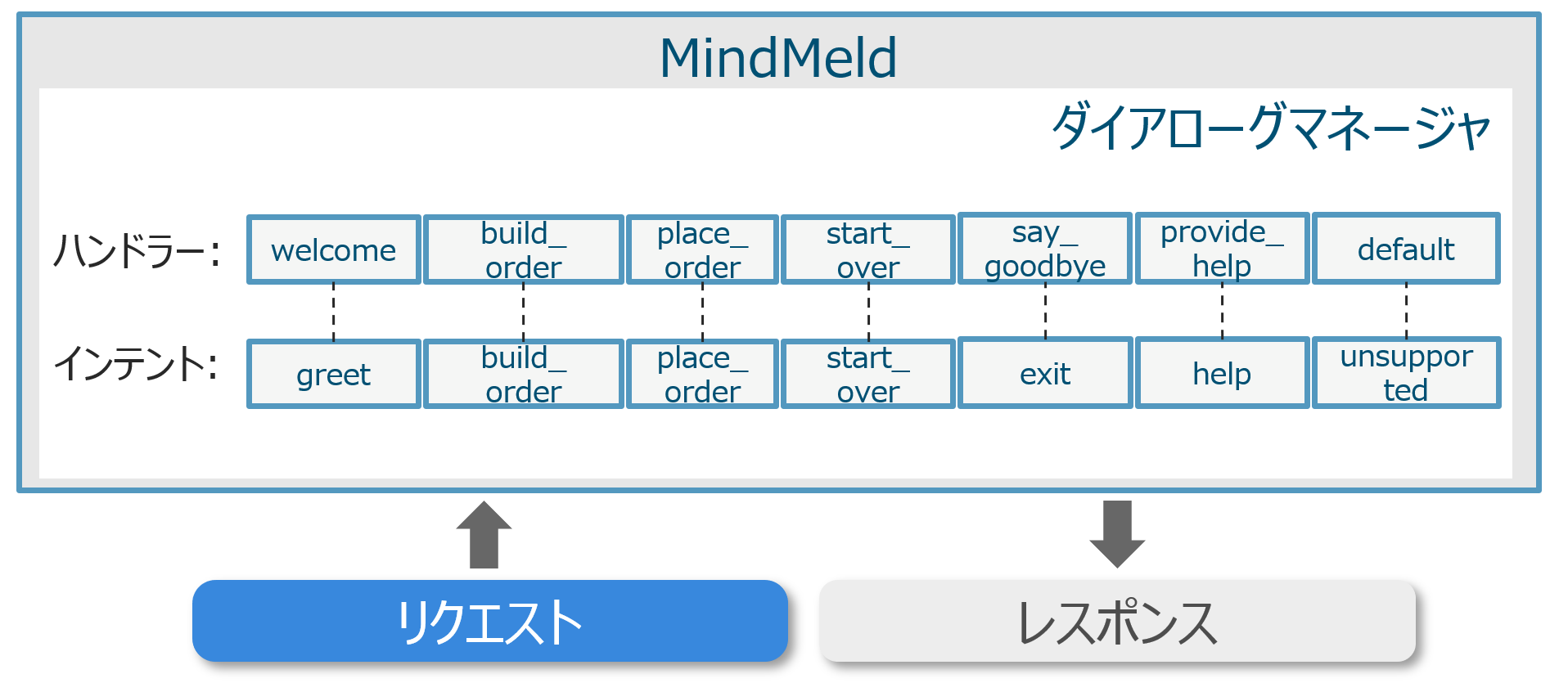
ハンドラが具体的に何を実施するかは開発者が自由にプログラム可能ですが、通常の利用方法では responder.reply() メソッドを使ってレスポンスを回答します。以下例として、default 及び welcome ハンドラの具体的なコードを抜き出します。
@app.handle(default=True)
@app.handle(intent='unsupported')
def default(request, responder):
replies = ["申し訳ないのですが理解できません。"
"'ファイアトレイルのマルゲリータピザを食べたいな'の様に話しかけて下さい。"]
responder.reply(replies)
@app.handle(intent='greet')
def welcome(request, responder):
try:
responder.slots['name'] = request.context['name']
prefix = 'こんにちは、{name}. '
except KeyError:
prefix = 'こんにちは。'
restaurants = app.question_answerer.get(index='restaurants')
suggestions = ', '.join([r['name'] for r in restaurants[0:3]])
responder.reply(prefix + '注文できるレストランの例は次の通りです:'
+ suggestions)
ステップ2:レストランとメニューの決定
例2-1:レストランとメニューの指定1
ここではレストラン名=バサシーフードエクスプレスから、メニュー名=海藻サラダを注文してみます(ユーザはこのメニューがあることを知っている前提)。
You: バサシーフードエクスプレスの海藻サラダが食べたいな
App: かしこまりました。海藻サラダ1つをバサシーフードエクスプレスに注文します。総額は税込みで$4.99です。発注しますか?
ナレッジベースを理解する
今回のアプリが実用的であり得るのは、レストラン名一覧とメニュー一覧をデータベースとして保持しているためです。MindMeld ではこれらデータ をナレッジベースと呼び、JSON 形式のファイルを作成する必要があります。
今回のアプリは計2つの JSON データを使用しており、ファイル名はレストラン一覧の restaurants.json とメニュー一覧の menu_items.json です。
以下は restaurants.json からレストランをひとつ分抜き出したもので、name(レストラン名)、rating(レビュー点数)、num_reviews(レビューの数)をはじめ、応用できそうな各種データを含んでいます。また、id(識別子)"B01N97KQNJ" はこのレストランを特定するのに使われます。
[
{
"cuisine_types": [
"シーフード",
"寿司"
],
"rating": 3.2,
"name": "バサシーフードエクスプレス",
"num_reviews": 8,
"menus": [
{
"option_groups": [
{
"max_selected": 1,
"options": [
{
"price": 0.0,
"description": null,
"name": "コーラ",
"id": "B01N1ME52H"
},
{
"price": 0.0,
"description": null,
"name": "水",
"id": "B01MTUONJU"
}
],
"min_selected": 1,
"id": "Coke or Water",
"name": "Choose One"
}
],
"id": "78eb0100-029d-4efc-8b8c-77f97dc875b5",
"size_groups": [
{
"sizes": [
{
"alt_name": "Small",
"name": "小"
},
{
"alt_name": "Medium",
"name": "中"
}
],
"description": null,
"name": "Choose Size",
"id": "Size"
}
]
}
],
"image_url": "https://images-na.ssl-images-amazon.com/images/G/01/ember/restaurants/SanFrancisco/BasaSeafoodExpress/logo_232x174._CB523176793_SX600_QL70_.png",
"price_range": 1.0,
"id": "B01N97KQNJ",
"categories": [
"ハワイアンスタイルポケ(HP)",
"セビーチェ(C)",
"握り寿司(2 Pcs)",
"人気商品",
"巻き寿司(6 Pcs)",
"クラムチャウダー(CC)",
"サイドオーダー(SO)",
"刺身(5 Pcs)",
"フィッシュアンドチップス(FC)",
"サラダ(SL)",
"ライスボウル(RB)",
"サンドウィッチ(SW)",
"スペシャルロール",
"スペシャルコンボ(PC)"
]
},
(中略)
]
以下は menu_items.json からメニューをひとつ分抜き出しました。restaurant_id でレストランと対応させています。上述の通り "B01N97KQNJ" がバサシーフードエクスプレスを意味します。
[
{
"category": "サイドオーダー(SO)",
"menu_id": "78eb0100-029d-4efc-8b8c-77f97dc875b5",
"description": null,
"price": 4.99,
"option_groups": [],
"restaurant_id": "B01N97KQNJ",
"size_prices": [],
"size_group": null,
"popular": false,
"img_url": "https://images-na.ssl-images-amazon.com/images/G/01/ember/restaurants/SanFrancisco/BasaSeafoodExpress/BasaSeafood_SeaweedSalad_640x480._V523234919_.jpg",
"id": "B01MTUORTQ",
"name": "海藻サラダ"
},
(中略)
]
エンティティ認識器を理解する
それでは MindMeld が例2-1 のリクエストを処理する過程を見ていきます。
まず、ドメイン分類器がドメイン=orderingへ分類します。次にインテント分類器がインテント=build_order(注文作成)へ分類します。
build_order へ分類された場合、ユーザが具体的に何を注文しようとしているのか、レストラン名やメニュー名等の要素(エンティティと呼ぶ)を抜き出す必要があります。
具体的にはエンティティ認識器が、バサシーフードエクスプレスをエンティティ=restaurantsとして、海藻サラダをエンティティ=dishとして抜き出します。
このように、エンティティ認識が必要な場合のインテント分類器用の教師データは、これまでと異なり下記の通りラベルを含んだ形で記述します:
{バサシーフードエクスプレス|restaurant}の{海藻サラダ|dish}を食べたいな
| の右側の restaurant と dish はそれぞれエンティティの種類を示します。| の左側はサンプルを1つ記述します。左側は同一エンティティであればその他のレストラン・その他のメニューでも反応しますので、上記教師データは例2-2のリクエストもインテント=build_order へ分類します。
例2-2:レストランとメニューの指定2
You: ファイアトレイルピザの四種チーズのホワイトピザを食べたいな
App: かしこまりました。四種チーズのホワイトピザ1つをファイアトレイルピザに注文します。総額は税込みで$13.00です。発注しますか?
別の例です。[階層構造](## ドメイン・インテント・エンティティの階層構造を理解する)を参照すると build_order の下で6種類のエンティティを定義しています。注文指定にはこれらのエンティティを利用することも可能です。
例2-3 はエンティティ=sys_number の使用例です。
例2-4 はエンティティ=option の使用例です。
例2-3:レストランからメニューを個数と共に指定
{バサシーフード|restaurant}から{海藻サラダ|dish}を{1|sys_number|num_orders}つと{ドラゴンロール|dish}を{1|sys_number|num_orders}つ注文しようかな
上記の教師データに基づき、下記例のように個数指定で注文できます。
You: バサシーフードからドラゴンロールを1つと海藻サラダを2つ注文しようかな
App: かしこまりました。ドラゴンロール1つ と海藻サラダ2つをバサシーフードエクスプレスに注文します。総額は税込みで$20.93です。発注しますか?
例2-4:ピザ注文時にオプションを指定する
{四種チーズのホワイトピザ|dish}に{オリーブ|option}と{ソーセージ|option}をトッピングして
上記の教師データに基づき、下記例のようにオプションを指定の上、注文できます。
You: ファイアトレイルピザの四種チーズのホワイトピザにオリーブとソーセージをトッピングして
App: かしこまりました。四種チーズのホワイトピザ1つをファイアトレイルピザに注文します。総額は税込みで$16.00です。発注しますか?
上記レスポンスにはオプション名の記載が無いものの、例2-2と比較すると、オリーブが1.00ドル、ソーセージが2.00ドルなので計3.00ドル総額が高くなっています。
注)オリーブやソーセージ等のオプションの金額等は restaurants.json で定義されています。
エンティティ解決器を理解する
エンティティ認識器はあくまでもリクエストからエンティティを抜き出す役割しか持ちません。最終的には抜き出したエンティティがナレッジベース内のどのデータへ対応するのかを一意に決定する必要があります。その役割を果たすのがエンティティ解決器です。
エンティティ解決器は類語リスト(Synonym List)という便利なツールを使用して、「通称」でのエンティティ解決が可能です。
例えば、例2-4 で「四種チーズのホワイトピザ」を注文しましたが、正直名称が長く面倒です。そこで「ホワイトピザ」や「白ピザ」という通称でも注文できるようにします。これらを類語リストに登録しましょう。
{
"kb_index_name": "menu_items",
"kb_field_name": "name",
"entities": [
(略)
{
"whitelist": [
"白ピザ",
"ホワイトピザ",
"4種チーズのピザ"
],
"cname": "四種チーズのホワイトピザ",
"id": "B01D8TDEK2"
},
(略)
]
}
上記類語リストを登録することで下記の通り通称でメニューを指定できます。
例2-5:通称を使ってメニューを指定する
You: ファイアトレイルピザの白ピザにオリーブとソーセージをトッピングして
App: かしこまりました。四種チーズのホワイトピザ1つをファイアトレイルピザに注文します。総額は税込みで$16.00です。発注しますか?
ステップ3:注文
メニューを指定できたら最終的に発注をします。ステップ1~3を通してみてみましょう。
例3-1:発注までの流れ
You: こんにちは。明日は晴れるかな。
App: こんにちは。注文できるレストランの例は次の通りです:ファイアトレイルピザ, バサシーフードエクスプレス, モンクのやかん
You: ファイアトレイルピザのホワイトピザにオリーブとソーセージをトッピングして
App: かしこまりました。四種チーズのホワイトピザ1つをファイアトレイルピザに注文します。総額は税込みで$16.00です。発注しますか?
You: はい
App: ご注文を承りました。ファイアトレイルピザへ発注します。30-45分で届く見込みです。ご利用ありがとうございました
インテント分類器が「はい」というリクエストをインテント=place_order へ分類した結果、ハンドラ=place_order が呼び出され、発注が完了します。対応するハンドラのコードを以下示します。
@app.handle(intent='place_order')
def place_order(request, responder):
selected_restaurant = request.frame.get('restaurant')
if selected_restaurant:
responder.slots['restaurant_name'] = selected_restaurant['name']
if len(request.frame.get('dishes', [])) > 0:
replies = ['ご注文を承りました。{restaurant_name}へ発注します。30-45分で届く見込みです。'
'ご利用ありがとうございました。']
responder.frame = {}
else:
replies = ["まだ料理が決まっていません。{restaurant_name}へ何を注文しますか"
"?"]
else:
replies = ["どちらのレストランへ発注しましょうか?"]
responder.reply(replies)
クエスチョンアンサラーを理解する
最後に説明が抜けていた便利機能クエスチョンアンサラーについて補足します。今回の例はユーザが事前にレストラン名・メニュー名を知っている前提のシナリオでしたが、現実にはそうはいきません。クエスチョンアンサラーを使うと、様々な条件で柔軟しかも簡単に、ナレッジベースのデータへ問合せを行うことができ、これによりレストラン名・メニュー名等を取得可能です。
実は[例1-1](### 例1-1:あいさつ(望ましいレスポンス)) でクエスチョンアンサラーを利用していました。ハンドラ=welcome 内の下記が該当部分です。ナレッジベースからレストラン名を取得し、先頭から3つを表示していました。
restaurants = app.question_answerer.get(index='restaurants')
suggestions = ', '.join([r['name'] for r in restaurants[0:3]])
クエスチョンアンサラー利用方法の一例として、レストランの rating の高い順に表示してみます。なお、restaurants.json によると、各レストランの rating は下記の通りです:
- ファイアトレイルピザ:4.1
- バサシーフードエクスプレス:3.2
- モンクのやかん:4.0
一行目を以下のように変更してみます。desc は降順にソートするオプションです:
restaurants = app.question_answerer.get(index='restaurants', _sort='rating', _sort_type='desc')
例3-2:あいさつ(クエスチョンアンサラーを使って rating でソート)
変更後の会話:
You: こんにちは
App: こんにちは。注文できるレストランの例は次の通りです:ファイアトレイルピザ, モンクのやかん, バサシーフードエクスプレス
動作原理の説明は以上です。
インストール方法
以下インストールの流れを示します。
MindMeld のインストール
公式サイトに従って MindMeld をインストールします。Docker と virtualenv の二通りありますが、ここでは前者を採用した前提で解説を続けます。
注意!以下の作業は virtualenv 内で行います
MindMeld 自作アプリのインストール
MindMeld 自作アプリ mm_food_ordering_jp を git clone します。
$ git clone https://github.com/dyoshiha/mm_food_ordering_jp.git
Janome のインストール
Janome をインストールします。
MindMeld本体の修正
修正箇所その1
Ckass Tokenizer へ下記追加します:
@staticmethod
def tokenize_raw_ja(text):
me = MeCab.Tagger("-Owakati")
j = 0
tokens = []
token = {}
for t in me.parse(text).split(' ')[: -1]:
token = { 'start' : j, 'text' : t }
tokens.append(token)
j = j + len(t)
return tokens
修正箇所その2
Tokenizer.tokenize() の下記の部分を
raw_tokens = self.tokenize_raw(text)
下記へ書き換えます:
raw_tokens = self.tokenize_raw_ja(text)
ElasticSearch の Docker イメージを Kuromoji へ対応させる
詳細は割愛しますが、今回使用した Docker イメージはこちらにあります。
ビルトインのテスト用ツールの起動方法
$ python -m food_ordering_jp build
$ python -m food_ordering_jp converse
おわりに
MindMeld はオープンソースですので、日本語環境の整備はどなたでも貢献できます。コミュニティを盛り上げる一助になれば幸いです。