概要
サービスメッシュ運用の課題
Kubernetes 上のマイクロサービスはどんどん増えて大規模になりがちです。各サービスは互いにネットワークで接続され、複数クラウド上に渡って存在することもあり得ます。複雑さに頭を痛めている方も多いかもしれません。Istio はその辺りの機能を提供するものの、十分ではないと言えます。そこで活用できるのが Backyards です。
Banzai Cloud Backyards とは
Backyards は Istio をベースに UI/API を強化し、マルチクラスタにも対応してより使いやすくしたツールです。
複雑で大規模なマイクロサービスを100%の信頼性で運用するのは非現実的です。Backyards はこの問題を現実的に扱うために「サービスレベル目標」と呼ばれる概念を取り入れています。
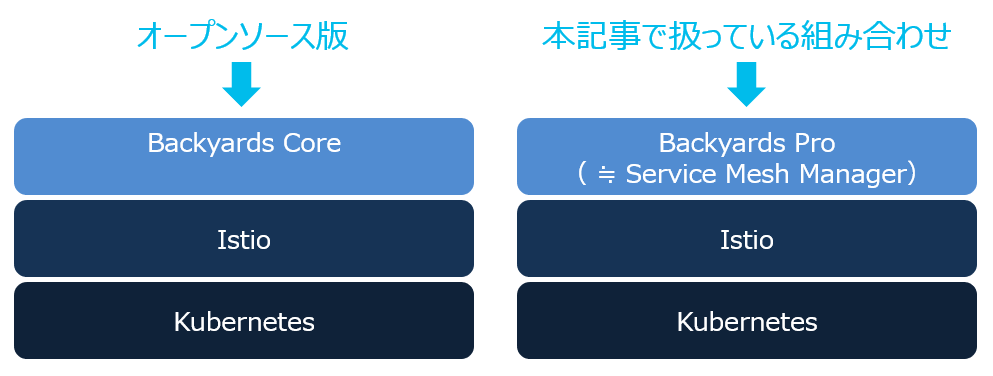
Backyards は Banzai Cloud 社が開発したツールで、オープンソースの Core と、より高機能な有償版の Pro があります(機能比較はこちら):
触ってみた(画面を見ながら理解する)
ここからは実際にインストールした製品の画面を参照しながら理解を深めていきます。
本記事執筆には Backyards Pro と同等なはず1の Service Mesh Manager(SMM)を利用しました。そのため以後ツール名を SMM で統一します。
トポロジーの可視化
SMM で一番特徴的なのがネットワークの可視化です。メニューで TOPOLOGY を選択すると、こんな感じでマイクロサービス間通信が可視化できます:
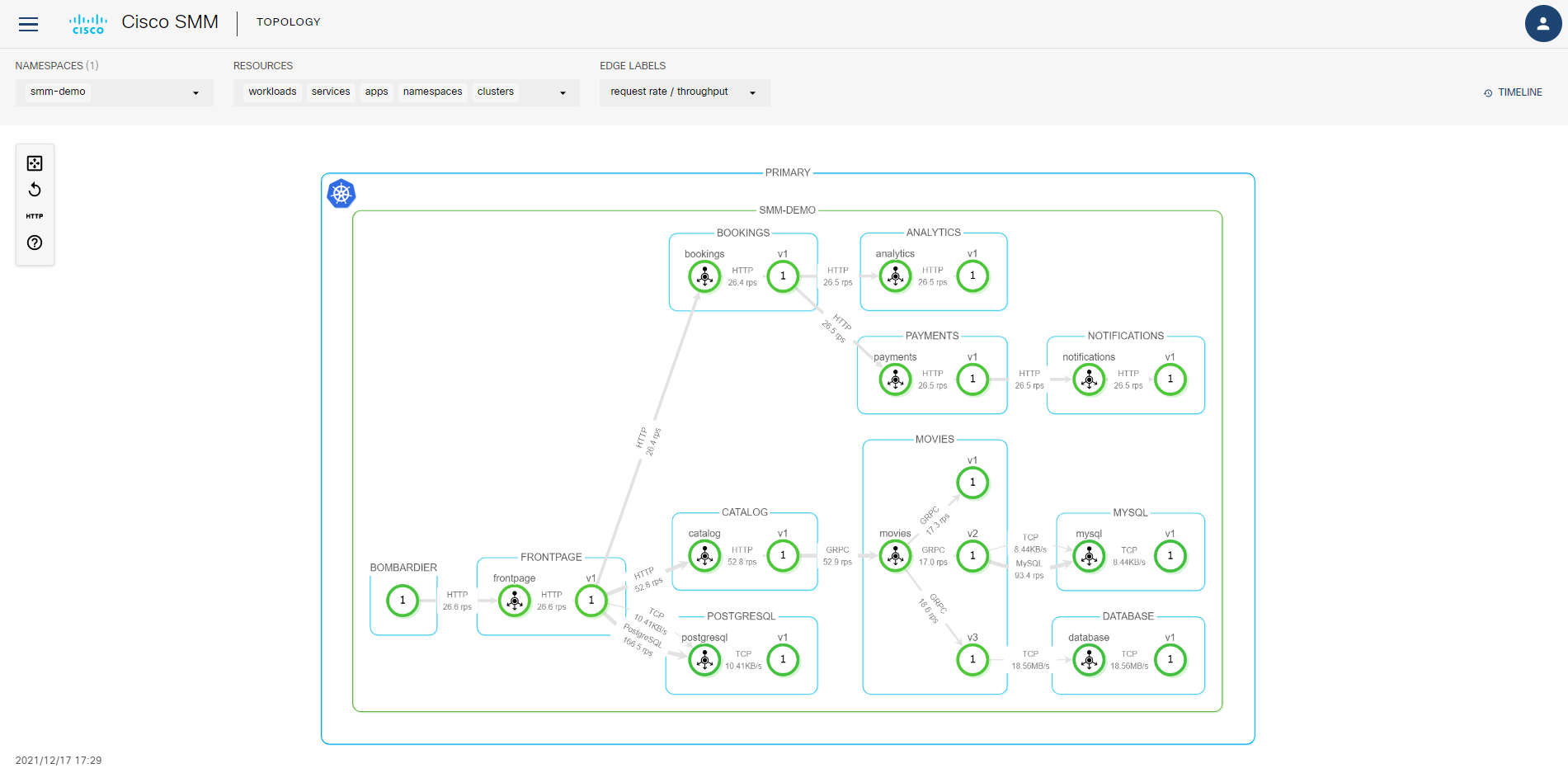
※実通信が流れないと図は表示されません。
トポロジー図の左下を拡大してみます:
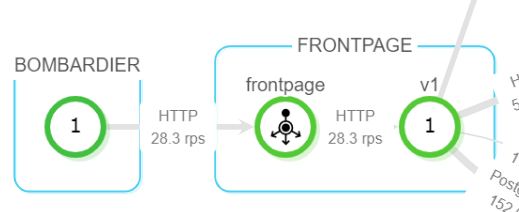
円は Kubernetes の Service またはワークロードを示し、その色で正常性を示します(緑=正常)。コンテナ間の通信が矢印で示され、そのラベルにプロトコルと通信量(request per second)が示されています。なお、本環境の Service を CLI で確認したのが以下で、トポロジーと対応していることがわかります:
$ kubectl get svc -n smm-demo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
analytics ClusterIP 192.168.199.189 <none> 8080/TCP,8082/TCP,8083/TCP 28h
bookings ClusterIP 192.168.88.145 <none> 8080/TCP,8082/TCP,8083/TCP 28h
catalog ClusterIP 192.168.192.61 <none> 8080/TCP,8082/TCP,8083/TCP 28h
database ClusterIP 192.168.39.171 <none> 8080/TCP,8082/TCP,8083/TCP 28h
frontpage ClusterIP 192.168.164.154 <none> 8080/TCP,8082/TCP,8083/TCP 28h
movies ClusterIP 192.168.186.93 <none> 8080/TCP,8082/TCP,8083/TCP 28h
mysql ClusterIP 192.168.158.251 <none> 3306/TCP 28h
notifications ClusterIP 192.168.236.76 <none> 8080/TCP,8082/TCP,8083/TCP 28h
payments ClusterIP 192.168.77.229 <none> 8080/TCP,8082/TCP,8083/TCP 28h
postgresql ClusterIP 192.168.33.139 <none> 5432/TCP 28h
ラベルに遅延とセキュリティ(=通信がSSLか否か)を表示することもできます。EDGE LABELS メニューで表示の切替を行えます:
メニューでsecurityを選択するとラベルが切り替わります。鍵マークのついている通信は安全であることがわかります:
トラフィック制御を使ったバージョン管理
次に、サービスメッシュならではの機能を見てみます。
典型的な利用シーンとして、マイクロサービスを構成する各コンテナはサービス向上のため高頻度で更新していくのが一般的です。が、更新の度にサービスをダウンさせるわけにいきません。利用者への影響を小さくする方法の一つにカナリアリリースがあります。
カナリアリリースとは、一部のランダムに選ばれたユーザのみ新機能にアクセスさせ、そこで問題が無いことを確認した後、全ユーザへ新機能を公開する手法です。
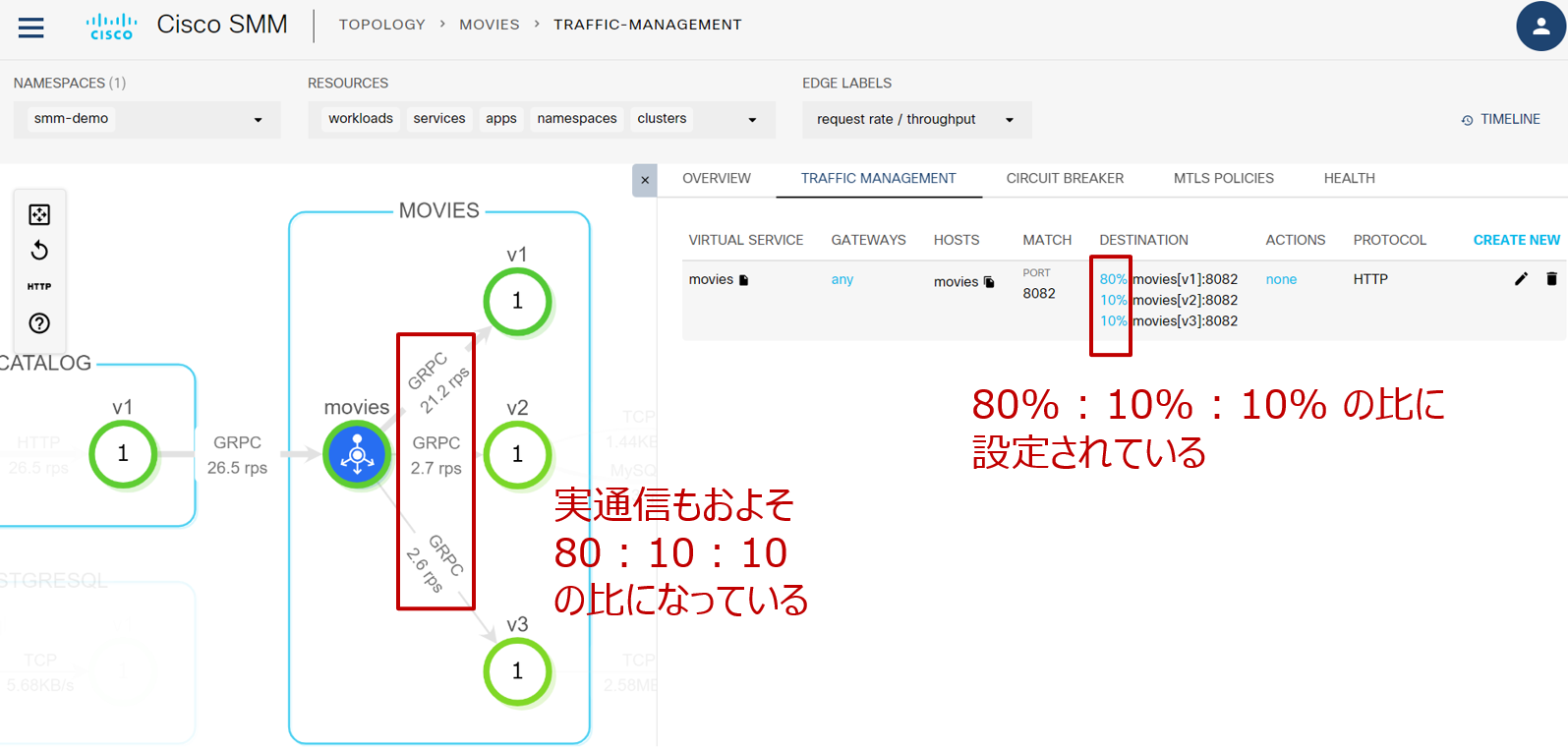
今回のアプリでは movies に3つのバージョンが存在し、現状は v1 : v2 : v3 = 80% : 10% : 10% の比で割り振る設定になっています。SMMでその設定を確認してみましょう。movies をクリックして詳細を表示します:
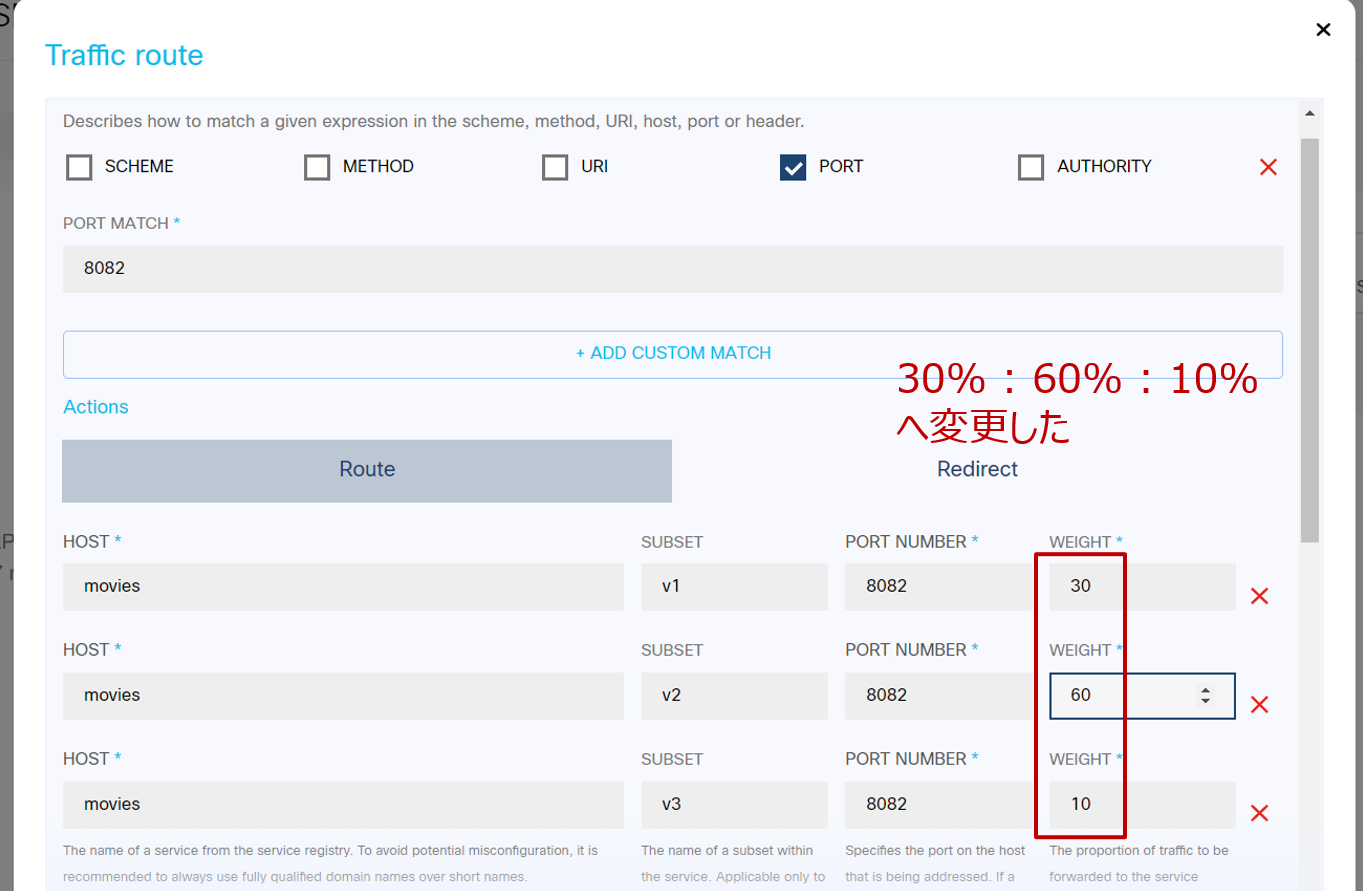
試しに 30% : 60% : 10% へ変更してみます。右側にある鉛筆マークをクリックすると設定画面が現れます:
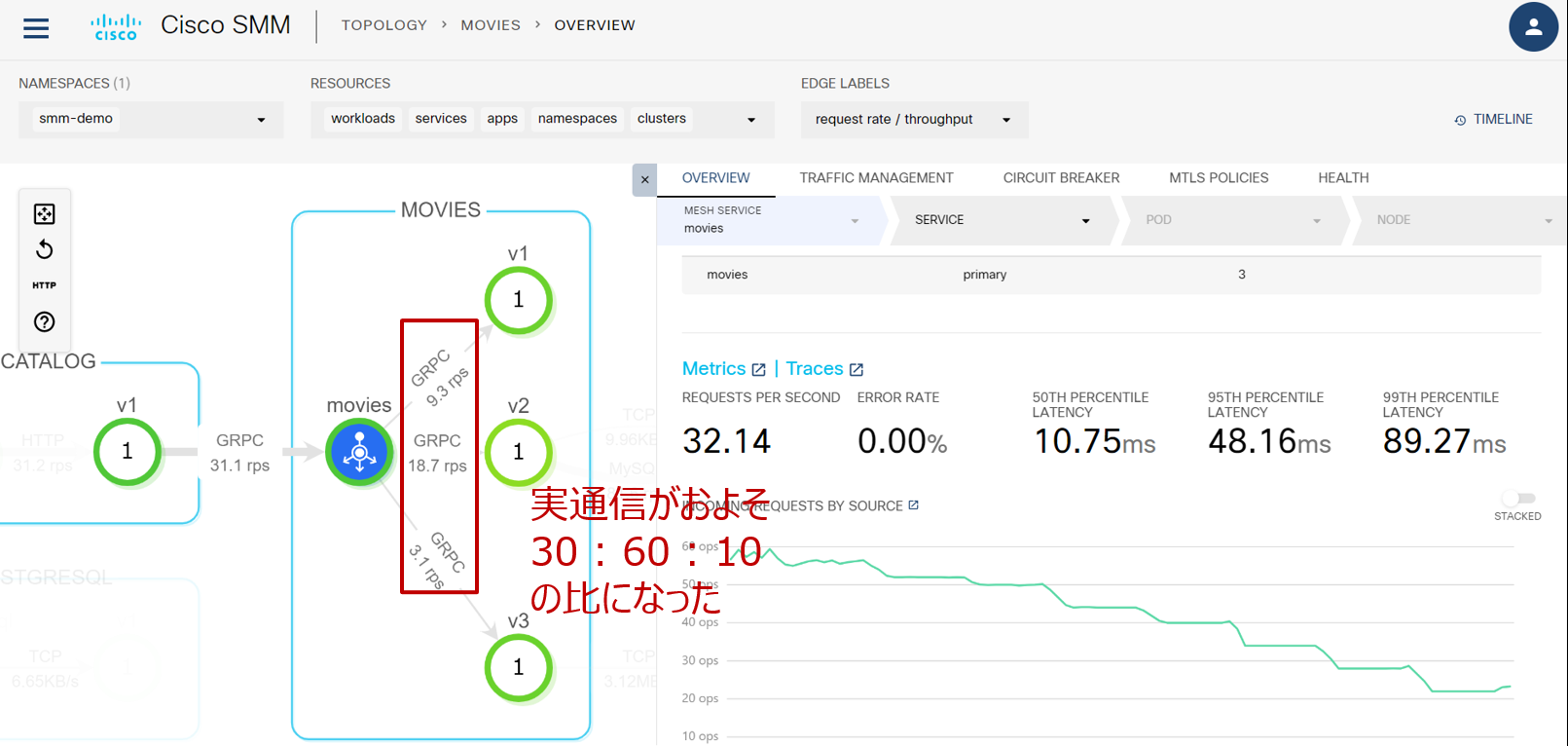
その後実際の通信が設定に従って行われ、しばらく待つと RPS が 30:60:10 に近い値になりました:
SERVICES で全体を俯瞰
アプリケーションの監視を行う際、全体を俯瞰していつどのサービスに変化があったかを知ることは有効です。メニューから SERVICES を選択する:
と、行に各サービス、列に各時刻を持ったマトリックスを表示します:
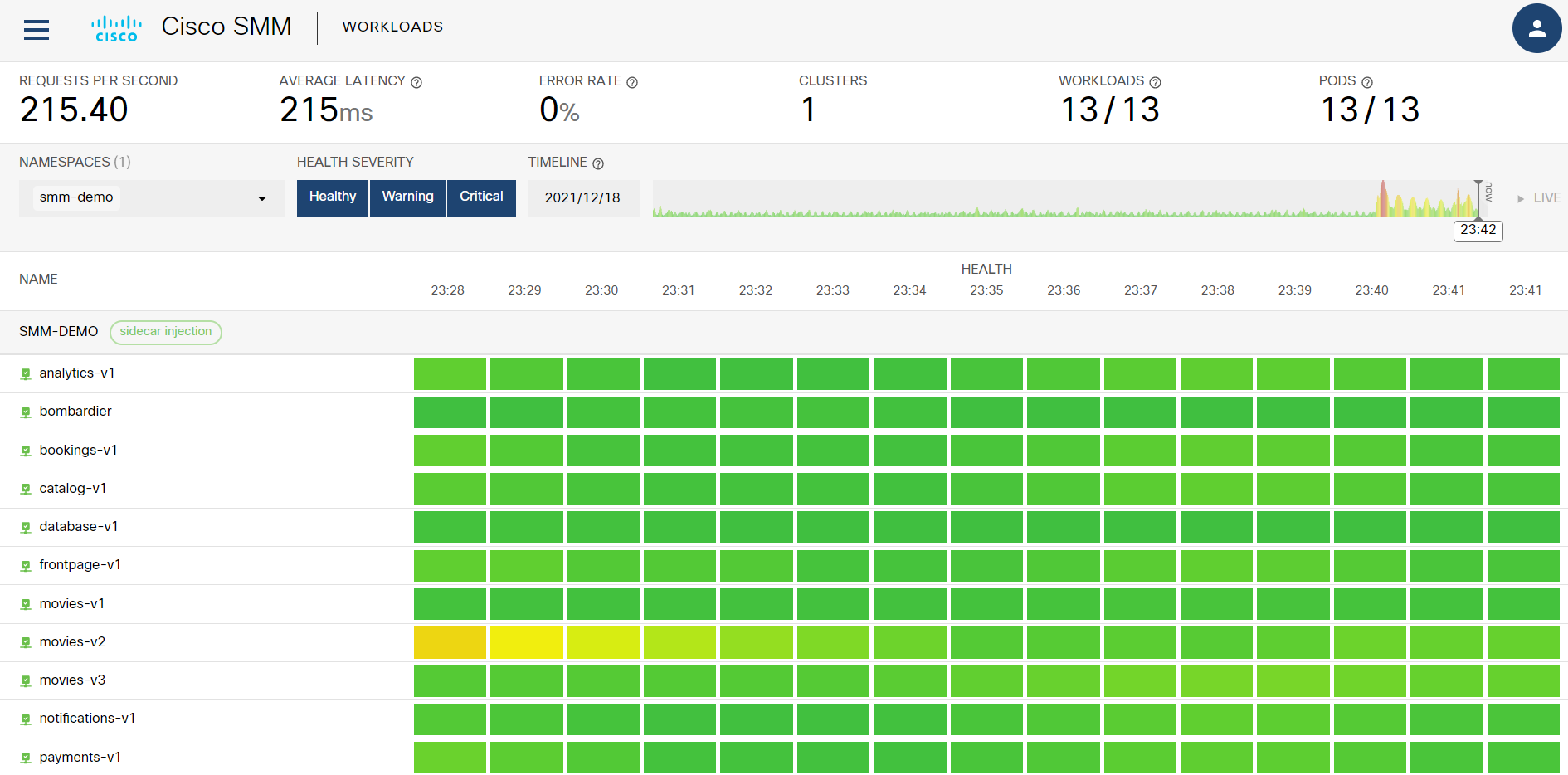
上図から movies-v2 で 23:28 頃に何かしらの変化が起きていたことがわかります。これに加え、右上の TIMELINE を見るともう少し前の時刻(20:55頃)が赤く表示されています。そこをクリックすると過去その時刻での状況が表示されます:
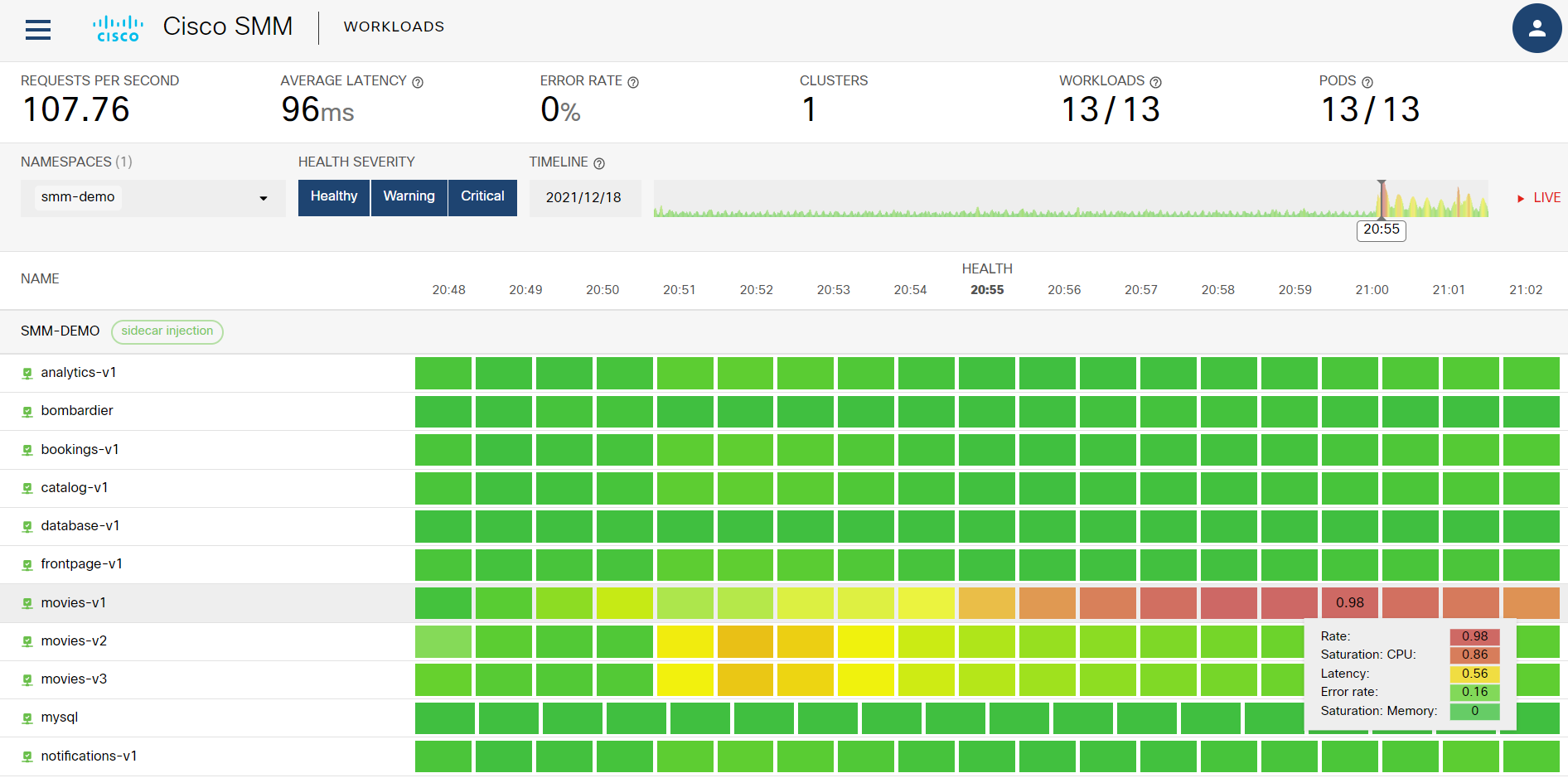
上図から movies-v1 で 21:00 頃に Saturation CPU と Latency が大き目の値になった事実が確認できます。
サービスレベル目標
サービスx時刻のマトリックスでは全体を俯瞰して問題点を見つけることができました。これはいかにも便利なアプローチですが、そもそも SMM はどのような判断に基づいて緑や赤で状態を色付けし、また、どのような運用方針を持つのでしょうか。
複雑で大規模なマイクロサービスを100%の信頼性で運用するのは非現実的です。SMM は障害は発生するものとの前提に立ち、例え発生してもあらかじめ定義したサービスレベル目標(Service Level Objectives: SLO)を満たすような運用を目指します(詳細はこちら参照)。
SLO の具体例は次のようなものです:
30日間の gRPC の成功率を99%にしたい場合、SLO は99%となる。つまり、1% のエラーは許容できることを意味する。30日間の想定リクエスト数が1,000万の場合、10万回のエラーが許容できることになる。これをエラーバジェットと呼び、例えば今月2万回のエラーが既に起きたとすると、エラーバジェット消費は20%であると表現する。
実際 SLO の設定は簡単ではないので、修正をしながら運用するのが現実的です。
では実際に SMM の画面で SLO を確認してみます。トポロジー図から再度 movies サービスをクリックします。現在赤枠の中に2つの SLO が設定されています:
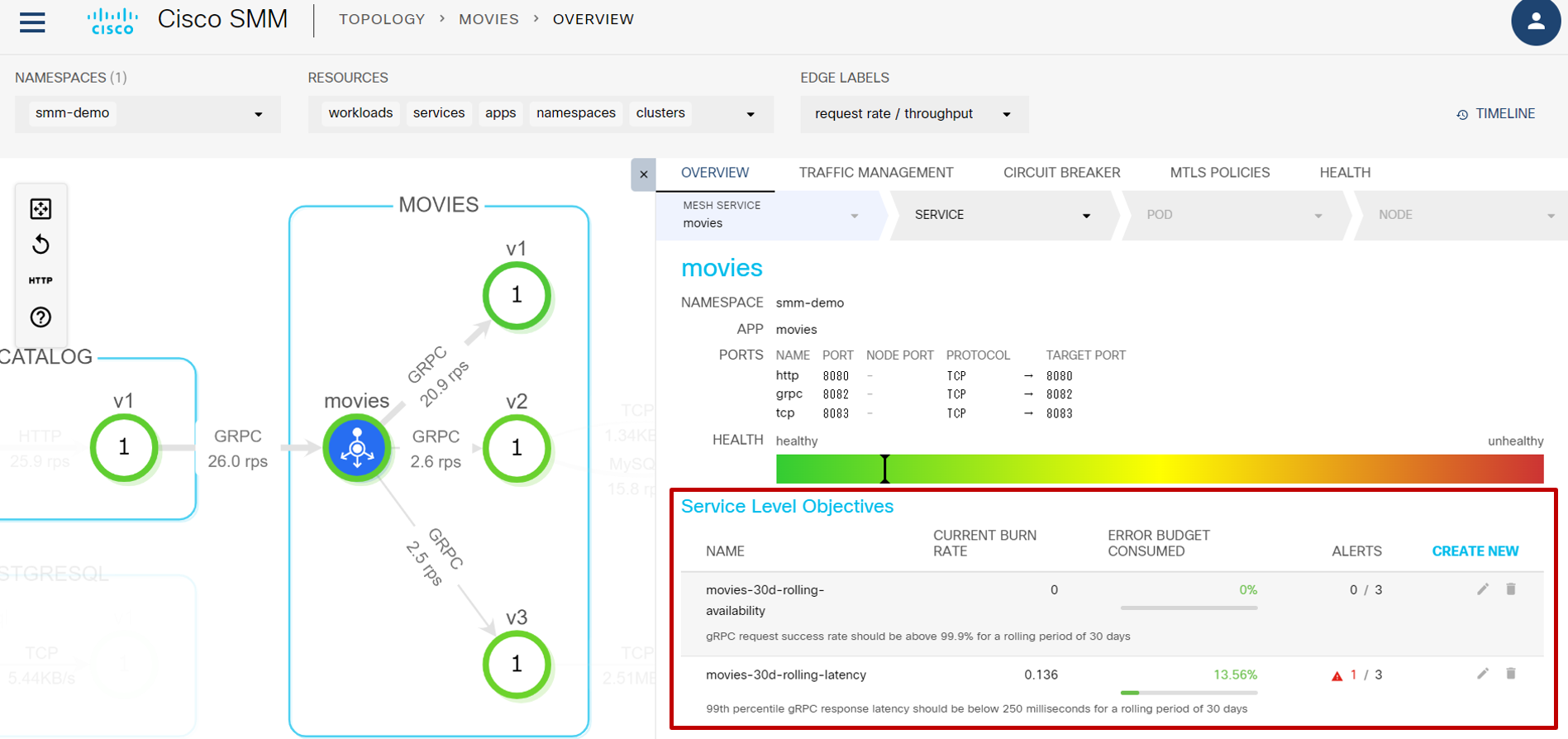
2つの内の一方 movies-30d-rolling-latency をクリックすると詳細が表示されます:
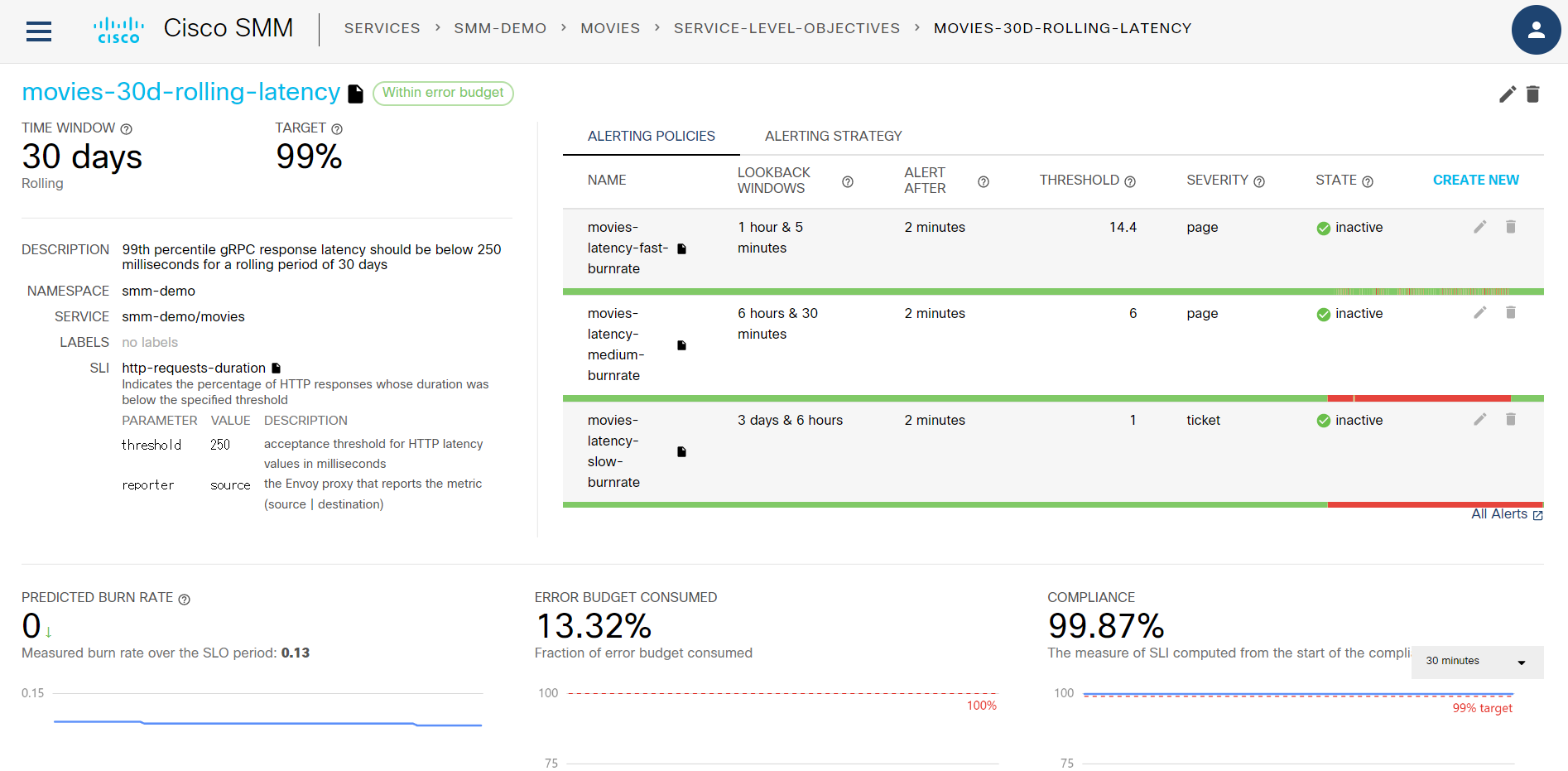
サービス名 movies の満たすべき条件(=Service Level Indicator: SLI)が「30日間で gRPC の99thパーセンタイル遅延が250ミリ秒以下であること」とわかります。
Jaeger による遅延状況の解析
遅延が発生し詳しく通信を調べたい場合は Jaeger ダッシュボードが有効です。先ほど確認した SLO をもう少し下にスクロールすると、Traces のところから Jaeger を開くことができます:
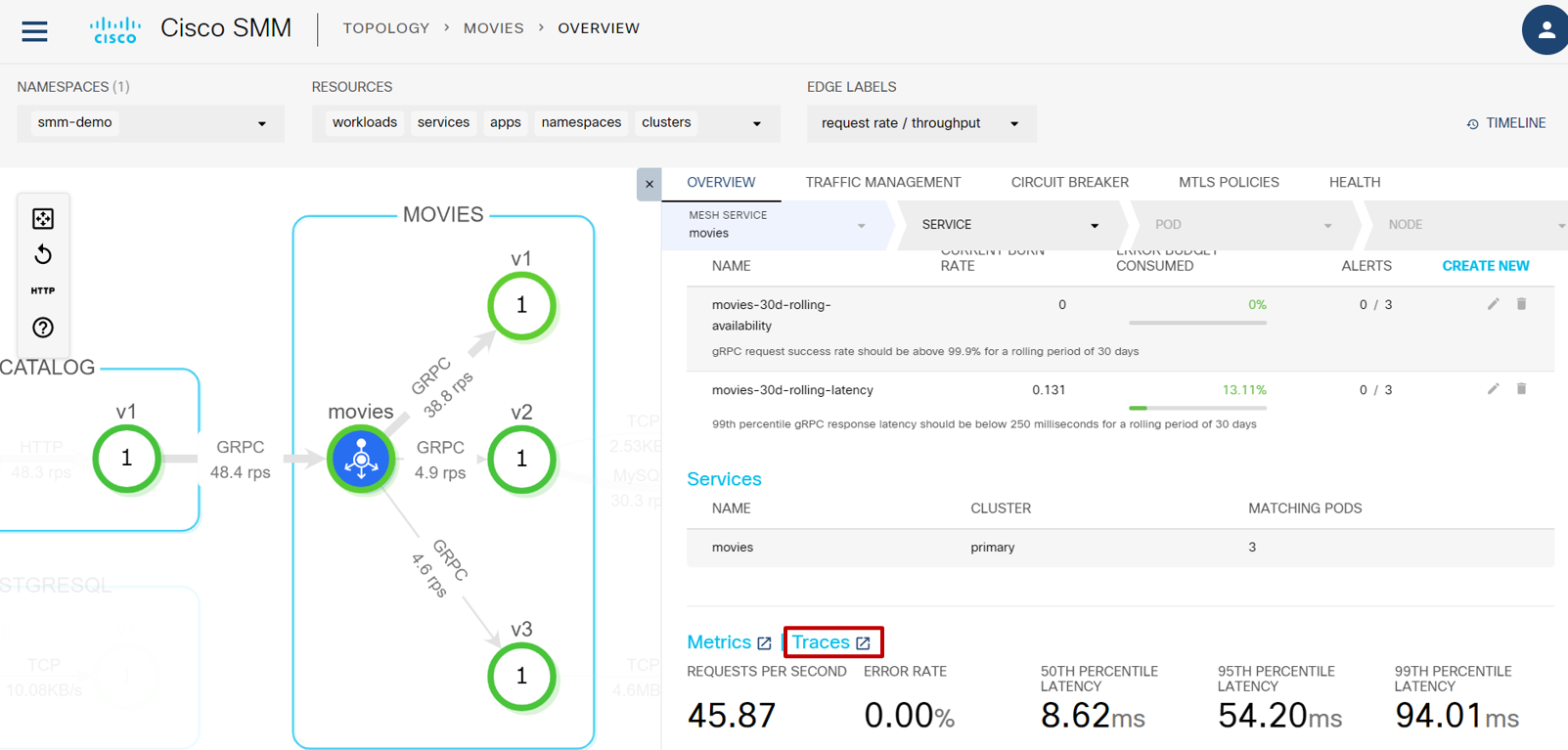
Traces の横のアイコンをクリックするとブラウザの別タブで Jaeger が開きます:
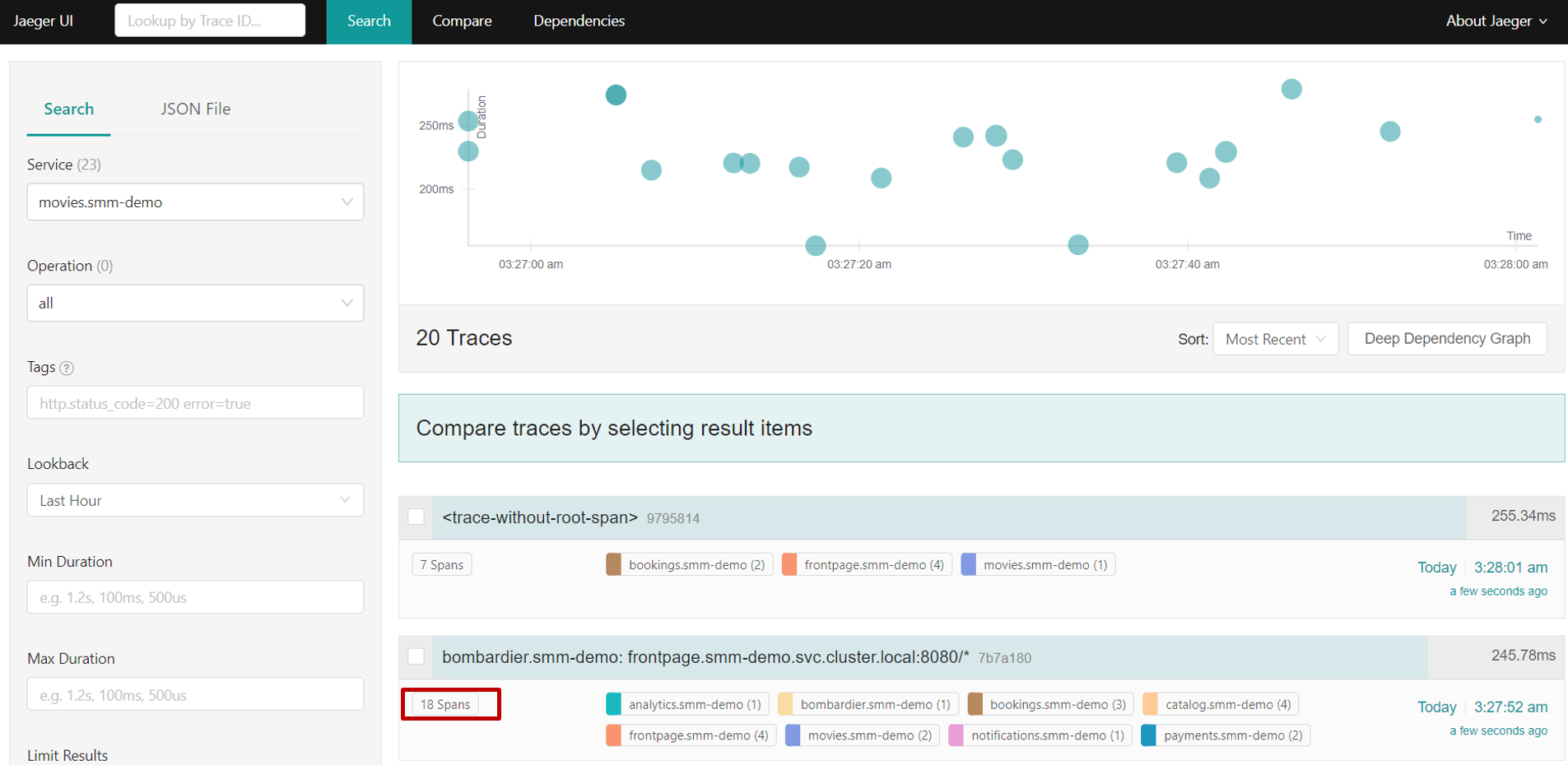
Spans をクリックすると、各サービスへ順にアクセスした際の詳細の遅延時間や、プロトコルの詳細を見ることができます:
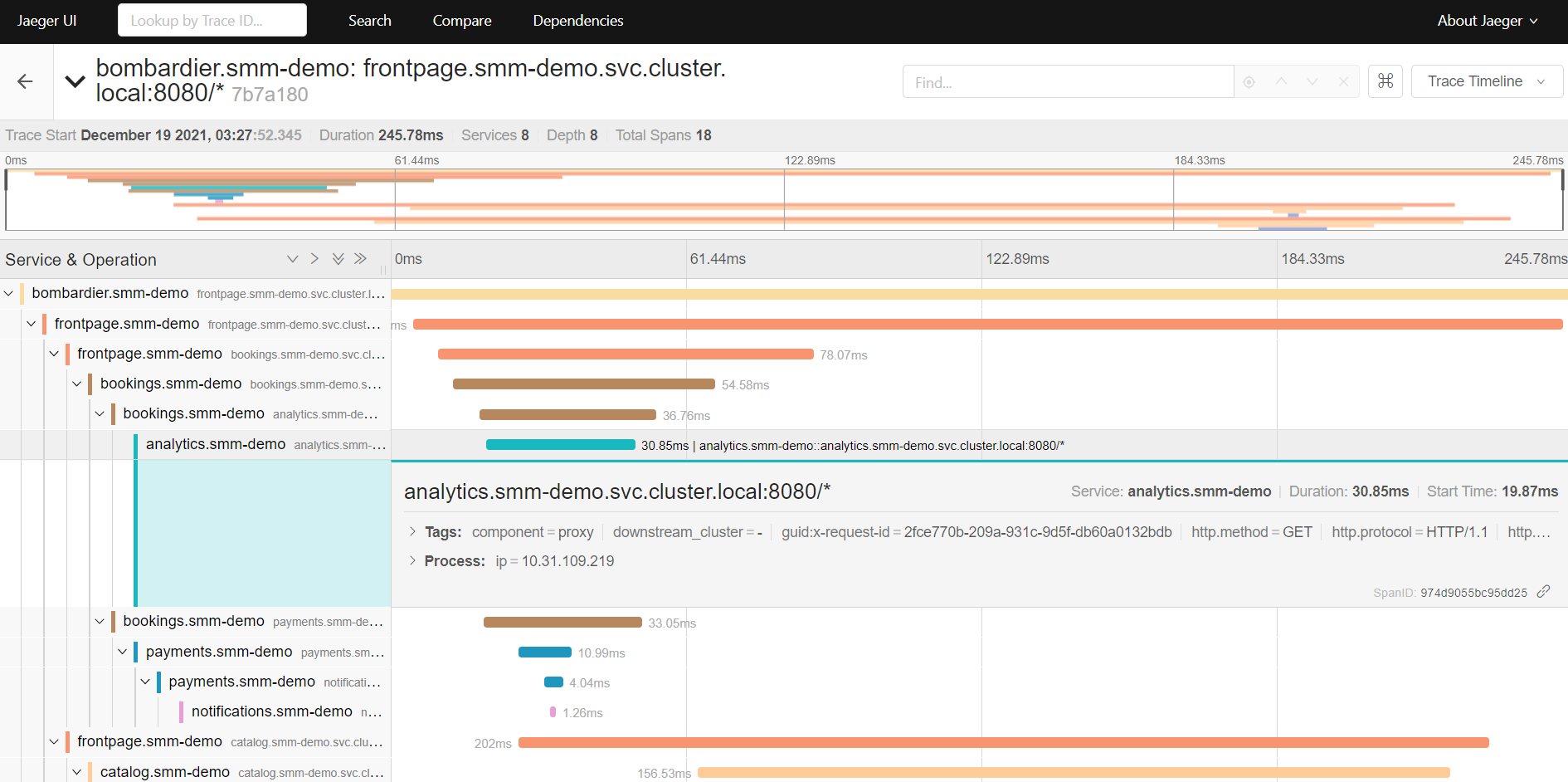
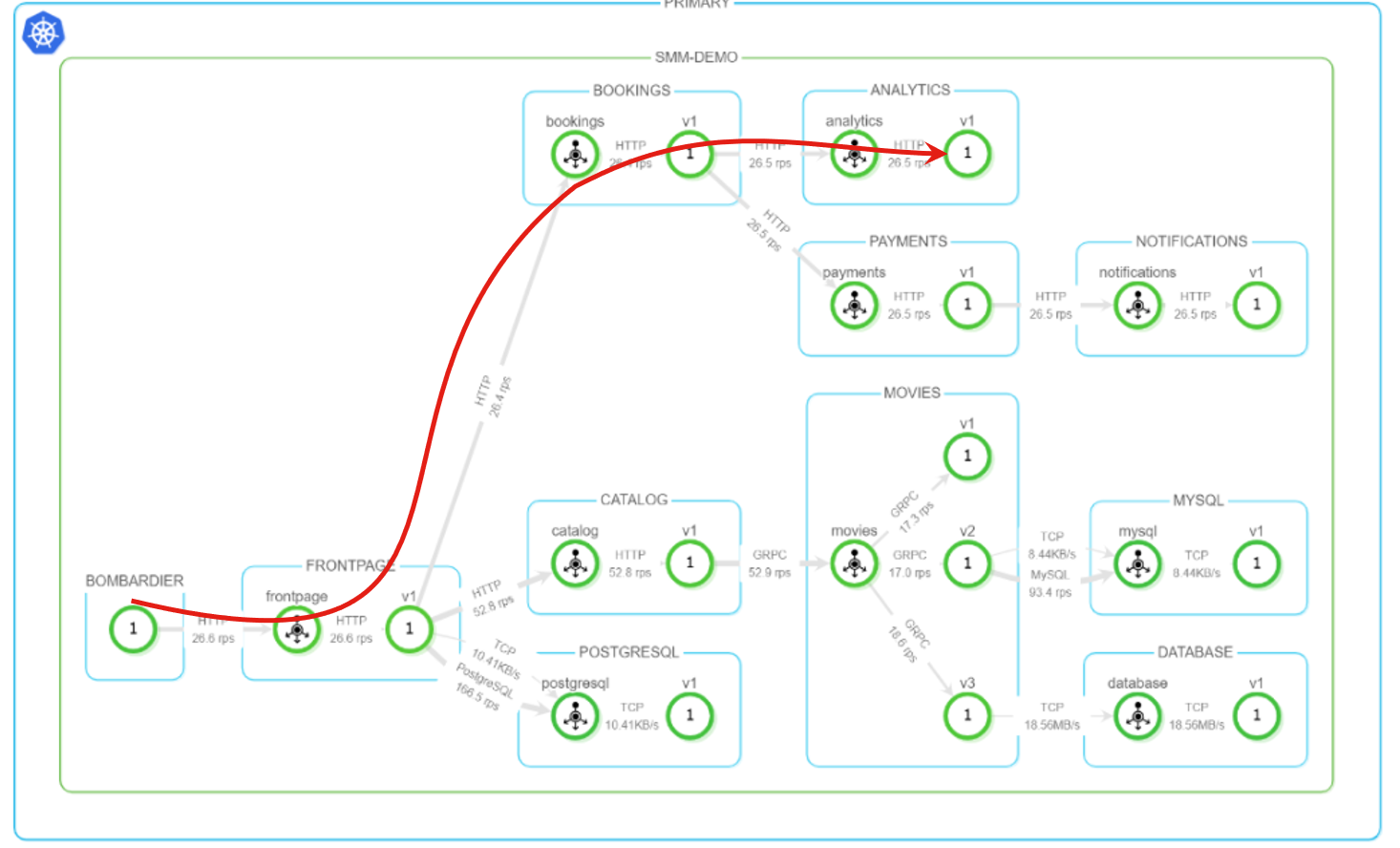
上図を詳しく見ていくと bombardier→frontpage→bookings→analytics と順にアクセスがあったことが示されており、特に analytics.smm-demo.svc.cluster.local:8080 へのアクセスに対する詳細を表示しています。トポロジーでは以下の通信に対応していることがわかります:
まとめ
以上「SMM 触ってみた」内容に基づいてまとめてみました。サービスレベル目標を設定して監視を開始し、TOPOLOGY や SERVICES 等の画面で全体を俯瞰しながら、異常を通知し、必要に応じて詳細を調べる、と言った流れで運用できることがわかりました。一部機能しか取り扱えませんでしたが、それでもこれらを組合わせて使うことで、複雑で大規模なサービスメッシュを管理する方法が理解できたように思います。
お読みいただきありがとうございました。
-
Backyards Pro と Service Mesh Manager は同等なはずですが、後者は Cisco Intersight と統合されている点が確実に異なります。今のところ SMM は Cisco Intersight Kubernetes Services の一機能として提供されています。 ↩