最近はDifyでLLMのアプリをサクッと作るのが楽しくてLangChainを触れていなかったので、あまり日本語記事がなさそうな、AlibabaのRAG(Vector Retrieval Service)を使ってみようと思いました。
AlibabaのVector Retrieval Serviceは DashVector とも呼ばれるそうです。
DashVector is a vector search service based on Proxima, an efficient vector engine developed by Tongyi Lab. The service is cloud-native, fully-managed, and horizontally scalable. DashVector offers diverse capabilities, such as vector management and search.
今回はローカルに保存したテキストファイルをベクトルに埋め込み、DashVectorにアップロードして格納します。その後クエリとなる文字列で、DashVectorに保存されたドキュメントから類似検索を行いたいと思います。
Pythonで実装したコードも貼っておきます。
前提条件
- OpenAIのAPI Keyを発行済み
- Pythonの開発環境を構築済み
手順
- Alibaba CloudコンソールからDashVectorを有効化しクラスターを作成
- DashVectorのAPI Keyを発行
- LangChainでDashVectorにコレクションとドキュメントを作成:ローカル環境でPythonの実行
- LangChainで類似検索を実行:ローカル環境でPythonの実行
1. Alibaba CloudコンソールからDashVectorを有効化しクラスターを作成
AlibabaのコンソールからVector Retrieval Serviceの画面にいきます

クラスター作成ボタンを押してクラスターの作成画面でクラスター名を入力します
「langchain-test」という名前でクラスターを作っていきます

入力が完了したらActivateをします

Activateが完了したらこのような画面になります

クラスターが作成されたらこのように「langchain-test」が画面に表示されます

後にDashVectorのEndpointもコード実行時に必要となるため、コピーしておきます。
作成したクラスター名を選択します。

ローカル環境から参照するためInternet AccessのEndpointをコピーします。

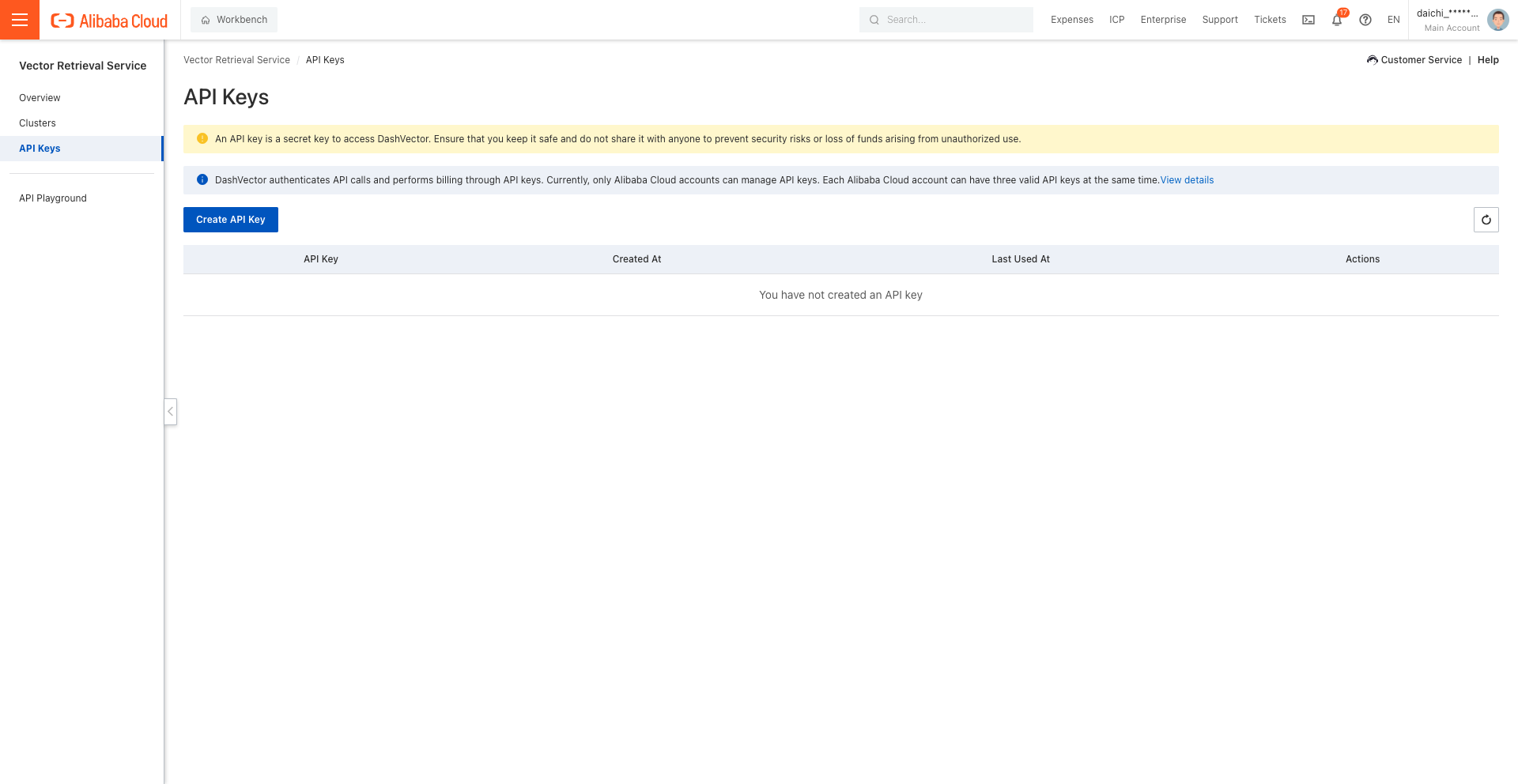
2. DashVectorのAPI Keyを発行
次にDashVectorのAPI Keyを発行します
非常にシンプルで「Create API Key」を押すだけ
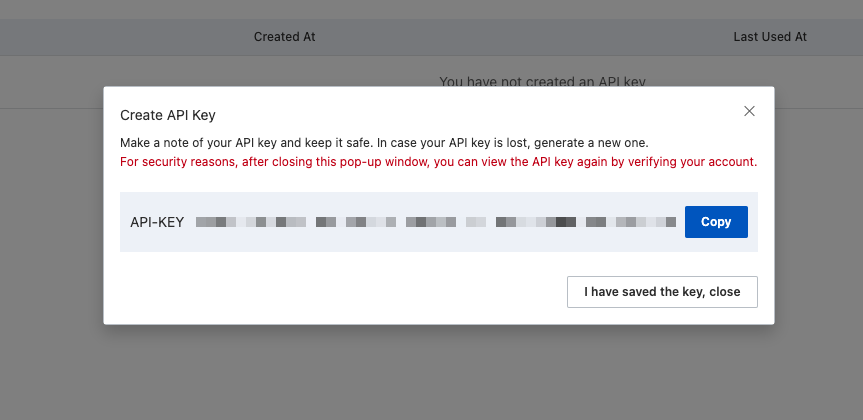
作成したら、API Keyが表示されるので大事に保存しておきましょう。あとでコードで使用します。
3. LangChainでDashVectorにコレクションとドキュメントを作成:ローカル環境でPythonの実行
DashVectorのSDKのインストールが必要になります。今回はpoetryを使用しているので、
poetry add dashvector
pipでインストールする場合
pip3 install dashvector
※ 参考リンク
Install a DashVector SDK - Vector Retrieval Service - Alibaba Cloud Documentation Center
準備として環境変数を .env に記載して、読み込みます
ここで先ほど発行したDashVectorのAPI Keyを使用します
config.py
import os
from os.path import join, dirname
from dotenv import load_dotenv
dotenv_path = join(dirname(__file__), ".env")
load_dotenv(dotenv_path)
DASHVECTOR_API_KEY = os.getenv("DASHVECTOR_API_KEY", "")
DASHVECTOR_ENDPOINT = os.getenv("DASHVECTOR_ENDPOINT", "")
DASHVECTOR_COLLECTION_NAME = (
"test-collection" # os.getenv("DASHVECTOR_COLLECTION_NAME")
)
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY", "")
DashVectorのクライアントを初期化します
client.py
import config
from dashvector import Client
# DashVectorクライアントを初期化
dashVectorClient = Client(
api_key=config.DASHVECTOR_API_KEY, endpoint=config.DASHVECTOR_ENDPOINT
)
assert dashVectorClient is not None
ローカルにおいたテキストファイルを参照して、DashVectorにcollectionを作成して、データを追加します。collection_name には 「test-collection」を指定しています。
import config
from typing import List
from os.path import join, dirname
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import DashVector
def create_docs() -> List[Document]:
"""ドキュメントを作成する関数。
この関数は、指定されたテキストファイルからドキュメントをロードし、
テキストを指定されたサイズのチャンクに分割し、各ドキュメントに
メタデータを追加します。
Returns:
List[Document]: 作成されたドキュメントのリスト。
"""
# テキストローダーを作成
loader = TextLoader(join(dirname(__file__), "../data/sample.txt"))
documents = loader.load()
# テキストを分割するための設定
text_splitter = CharacterTextSplitter(
chunk_size=100, chunk_overlap=0, separator="。"
)
docs = text_splitter.split_documents(documents)
# メタデータを設定
for doc in docs:
doc.metadata = {
"source": "sample.txt"
} # ローカルPCの絶対パスが使用されるため、sourceを明示的に更新.それ以外のmetadataを付与することも可能
return docs
if __name__ == "__main__":
print("コレクションを作成し、ドキュメントを追加します")
# 埋め込みを作成
embeddings = OpenAIEmbeddings(
openai_api_key=config.OPENAI_API_KEY,
model="text-embedding-3-large",
)
# ドキュメントを作成
docs = create_docs()
for document in docs:
print("ドキュメント: ", document.page_content)
# コレクションを作成し、ドキュメントを追加
vectorstore = DashVector.from_documents(
docs,
embeddings,
collection_name=config.DASHVECTOR_COLLECTION_NAME, # collection_nameを指定(add_texts関数をwrapしているため)
)
これを実行すると、Alibabaのコンソール画面でデータが入っていることが確認できます。

格納した元データはこちら:https://github.com/dychi/langchain-dashvector/blob/main/data/sample.txt
-
元データ
ワインは、豊かな風味と香りを持つ飲み物であり、さまざまな種類があります。
それぞれのワインは、ブドウの品種や栽培地域、醸造方法によって異なる特徴を持っています。
赤ワインは、果実味とタンニンのバランスが重要で、肉料理やチーズと相性が良いです。
白ワインは、爽やかな酸味とフルーティーな香りが特徴で、魚料理や軽い前菜にぴったりです。
ロゼワインは、赤と白の中間的な存在で、さまざまな料理に合わせやすい柔軟性があります。
ワインは、食事を引き立てるだけでなく、友人や家族との特別な時間を共有するための素晴らしい選択肢です。
また、ワインのテイスティングは、香りや味わいを楽しむだけでなく、ワインの背景や文化を学ぶ機会でもあります。
最近では、サステナブルな農法で作られたオーガニックワインも注目されており、環境への配慮が求められています。
ワインの世界は奥深く、探求することで新たな発見があることでしょう。
日本酒は、日本の伝統的な醸造酒であり、米を主成分としています。
その製造過程は非常に繊細で、米の精米、発酵、そして熟成が重要な役割を果たします。
日本酒には、純米酒、吟醸酒、大吟醸酒など、さまざまな種類があり、それぞれの風味や香りが異なります。
特に、吟醸酒はフルーティーで華やかな香りが特徴で、食事との相性も良いです。
日本酒は、冷やして飲むことも、温めて飲むこともでき、季節や料理に応じて楽しむことができます。
また、日本酒のテイスティングは、香りや味わいを楽しむだけでなく、地域ごとの特色や文化を学ぶ貴重な機会でもあります。
最近では、海外でも日本酒の人気が高まり、さまざまな料理とのペアリングが注目されています。
日本酒の世界は奥深く、探求することで新たな発見があることでしょう。
4. LangChainで類似検索を実行:ローカル環境でPythonの実行
最後にクエリを投げて類似する文章を取得してみます。
query.py
import config
from client import dashVectorClient
from langchain_community.vectorstores import DashVector
from langchain_openai import OpenAIEmbeddings
if __name__ == "__main__":
# コレクション名を指定
collection = dashVectorClient.get(config.DASHVECTOR_COLLECTION_NAME)
# 埋め込みを作成
embeddings = OpenAIEmbeddings(
openai_api_key=config.OPENAI_API_KEY,
model="text-embedding-3-large",
)
# 初期化
vectorstore = DashVector(collection, embeddings, "text")
# ドキュメントをクエリ
query = "ロゼワイン"
simDocScore = vectorstore.similarity_search_with_relevance_scores(query, k=3)
for simDoc, Score in simDocScore:
print("類似ドキュメント: ", simDoc.page_content)
print("類似ドキュメントのスコア: ", Score)
実行結果↓
❯ python src/query.py
類似ドキュメント: ロゼワインは、赤と白の中間的な存在で、さまざまな料理に合わせやすい柔軟性があります。
ワインは、食事を引き立てるだけでなく、友人や家族との特別な時間を共有するための素晴らしい選択肢です
類似ドキュメントのスコア: 0.3794
類似ドキュメント: 赤ワインは、果実味とタンニンのバランスが重要で、肉料理やチーズと相性が良いです。
白ワインは、爽やかな酸味とフルーティーな香りが特徴で、魚料理や軽い前菜にぴったりです
類似ドキュメントのスコア: 0.5906
類似ドキュメント: ワインは、豊かな風味と香りを持つ飲み物であり、さまざまな種類があります。
それぞれのワインは、ブドウの品種や栽培地域、醸造方法によって異なる特徴を持っています
類似ドキュメントのスコア: 0.6463
クエリの文字列は 「ロゼワイン」で、結果を見るとちゃんとロゼワインが入ったドキュメントを返してくれていることがわかります。
まとめ
LangChainを使ってDashVectorからドキュメントの類似検索を簡単に試すことができました!
DashVector公式のSDKを使ってcollectionを作らずとも、LangChainを使えば簡単にcollectionを作ってくれますし適切なフォーマットにしてドキュメントを登録してくれるので実装がシンプルで済みました。
久々にLangChainを触ってみましたが、DashVectorも対応してくれてたので簡単に検証ができました。