はじめに
Lightgbmで構築したモデルに対してscikit-learnのplot_partial_dependenceを実行したときにNotFittedErrorが表示され、うまく実行できませんでした。
その対処についての備忘録です。
環境
環境は以下の通り。
$sw_vers
ProductName: Mac OS X
ProductVersion: 10.13.6
BuildVersion: 17G14042
Jupyterlab (Version 0.35.4) 上で作業していたので、python kernelのバージョンも記載しておきます。
Python 3.7.3 (default, Mar 27 2019, 16:54:48)
IPython 7.4.0 -- An enhanced Interactive Python. Type '?' for help.
やったこと
モデル構築
予測するためのデータとモデルを用意します。
データはscikit-learnで用意されているボストンデータセットを使用しました。
import pandas as pd
import sklearn.datasets as skd
data = skd.load_boston()
df_X = pd.DataFrame(data.data, columns=data.feature_names)
df_y = pd.DataFrame(data.target, columns=['y'])
以下の通り、506行13列のデータで全列がnon-nullのfloat型なのでこのままモデルを作ります。
df_X.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 506 entries, 0 to 505
Data columns (total 13 columns):
CRIM 506 non-null float64
ZN 506 non-null float64
INDUS 506 non-null float64
CHAS 506 non-null float64
NOX 506 non-null float64
RM 506 non-null float64
AGE 506 non-null float64
DIS 506 non-null float64
RAD 506 non-null float64
TAX 506 non-null float64
PTRATIO 506 non-null float64
B 506 non-null float64
LSTAT 506 non-null float64
dtypes: float64(13)
memory usage: 51.5 KB
LightGBMで、ハイパーパラメタはでほぼデフォルトのままでモデルを構築しておきます。
Training APIの場合
Training APIで用意されているtrainの関数でモデル構築した場合は、Boosterが返されます。
結論からいうと、Boosterをそのままscikit-learnのplot_partial_dependenceに渡すとエラーとなります。
どのようなエラーになるのか見ていきたいと思います。
まずはモデルを学習させます。
import lightgbm as lgb
from sklearn.model_selection import train_test_split
df_X_train, df_X_test, df_y_train, df_y_test = train_test_split(df_X, df_y, test_size=0.2, random_state=4)
lgb_train = lgb.Dataset(df_X_train, df_y_train)
lgb_eval = lgb.Dataset(df_X_test, df_y_test)
# Booster
params = {
'seed':4,
'objective': 'regression',
'metric':'rmse'}
lgbm_booster = lgb.train(params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=200,
early_stopping_rounds=20,
verbose_eval=50)
(省略)
Training until validation scores don't improve for 20 rounds
[50] valid_0's rmse: 3.58803
[100] valid_0's rmse: 3.39545
[150] valid_0's rmse: 3.31867
[200] valid_0's rmse: 3.28222
Did not meet early stopping. Best iteration is:
[192] valid_0's rmse: 3.27283
これで学習させたモデルlgbm_boosterをplot_partial_dependenceに渡します。
from sklearn.inspection import plot_partial_dependence
plot_partial_dependence(lgbm_booster, df_X_train, ['CRIM', 'ZN'])
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-7-9a44e58d2f50> in <module>
1 from sklearn.inspection import plot_partial_dependence
----> 2 plot_partial_dependence(lgbm, df_X_train, ['CRIM', 'ZN'])
(中略)
/anaconda3/lib/python3.7/site-packages/sklearn/inspection/_partial_dependence.py in partial_dependence(estimator, X, features, response_method, percentiles, grid_resolution, method)
305 if not (is_classifier(estimator) or is_regressor(estimator)):
306 raise ValueError(
--> 307 "'estimator' must be a fitted regressor or classifier."
308 )
309
ValueError: 'estimator' must be a fitted regressor or classifier.
というわけでValueErrorが出ることが確認できました。
Scikit-learn APIの場合
それではScikit-learn APIでモデルを学習させます。
回帰問題のため、LGBMRegressorを使います。
lgbm_sk = lgb.LGBMRegressor(objective=params['objective'],
random_state=params['seed'],
metric=params['metric'])
lgbm_sk.fit(df_X_train, df_y_train)
LGBMRegressor(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0,
importance_type='split', learning_rate=0.1, max_depth=-1,
metric='rmse', min_child_samples=20, min_child_weight=0.001,
min_split_gain=0.0, n_estimators=100, n_jobs=-1, num_leaves=31,
objective='regression', random_state=4, reg_alpha=0.0,
reg_lambda=0.0, silent=True, subsample=1.0,
subsample_for_bin=200000, subsample_freq=0)
これで学習させたモデルlgbm_skをplot_partial_dependenceに渡します。
plot_partial_dependence(lgbm_sk, df_X_train, ['CRIM', 'ZN'])
---------------------------------------------------------------------------
NotFittedError Traceback (most recent call last)
<ipython-input-9-d0724528e406> in <module>
----> 1 plot_partial_dependence(lgbm_sk, df_X_train, ['CRIM', 'ZN'])
(中略)
/anaconda3/lib/python3.7/site-packages/sklearn/utils/validation.py in check_is_fitted(estimator, attributes, msg, all_or_any)
965
966 if not attrs:
--> 967 raise NotFittedError(msg % {'name': type(estimator).__name__})
968
969
NotFittedError: This LGBMRegressor instance is not fitted yet. Call 'fit' with appropriate arguments before using this estimator.
このようにNotFittedErrorが発生しました。
ここで使用しているscikit-learnとlightgbmのバージョンはそれぞれ0.22.2.post1と2.3.0です。
from sklearn import __version__ as sk_ver
print(lgb.__version__)
print(sk_ver)
2.3.0
0.22.2.post1
ここで発生したNotFittedErrorについて調べていると、GithubのIssueでこのエラーについてレポートされていました。
どうもscikit-learnのcheck_is_fittedという関数を使ってモデルがフィット済みか確認しているのですが、check_is_fittedで確認するattributeがlightgbmのfitで設定されていないために起こっているようです。
バージョンアップすることで解決できそうなので、lightgbmをバージョンアップします。
2021年1月14日の段階で最新バージョンは3.1.1だったため、このバージョンを指定しました。
conda install -c conda-forge lightgbm=3.1.1
バージョンを確認します。
from sklearn import __version__ as sk_ver
print(lgb.__version__)
print(sk_ver)
3.1.1
0.23.1
改めてモデルを学習させます。
lgbm_sk = lgb.LGBMRegressor(objective=params['objective'],
random_state=params['seed'],
metric=params['metric'])
lgbm_sk.fit(df_X_train, df_y_train)
LGBMRegressor(metric='rmse', objective='regression', random_state=4)
lgbm_skをplot_partial_dependenceに渡します。
plot_partial_dependence(lgbm_sk, df_X_train, ['CRIM', 'ZN'])
今回はエラーなく実行でき、下図のような結果を得られました。
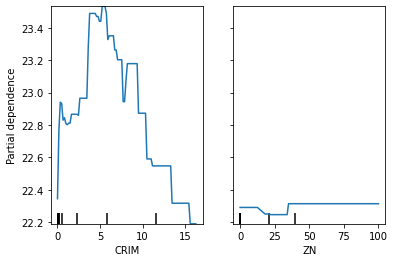
ついでにscikit-learnの他にpdpboxを使ってpartial dependenceを出してみます。
from pdpbox import pdp, get_dataset, info_plots
fig = plt.figure(figsize=(14,5))
pdp_goals = pdp.pdp_isolate(model=lgbm_sk, dataset=df_X_train, model_features=df_X_train.columns, feature='LSTAT')
# plot it
pdp.pdp_plot(pdp_goals,'LSTAT')
plt.show()
下図のような出力を得られました。scikit-learnよりも見た目はいいです。
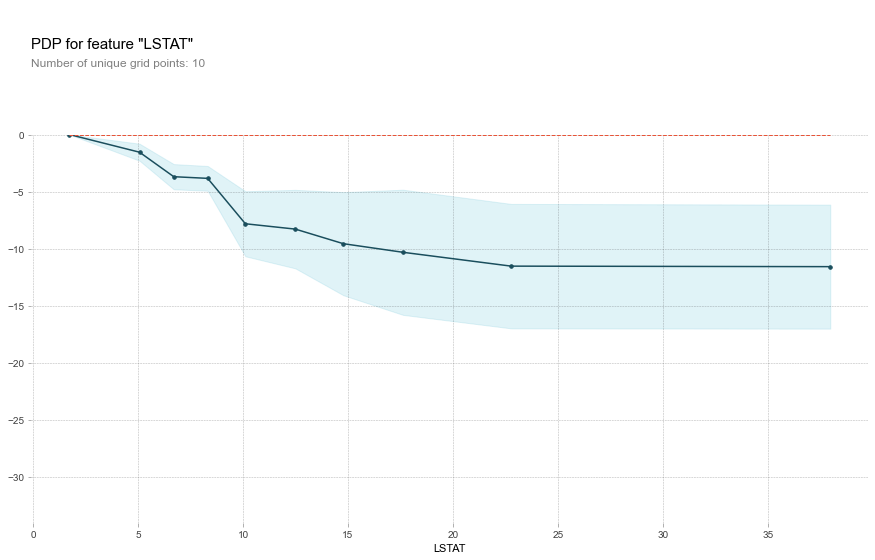
まとめ
Lightgbmをscikit-learnのplot_partial_dependenceに渡したときに発生したNotFittedErrorはLightgbmをバージョンアップすることで解決しました。