はじめに
こちらの記事でintel compilerが無料で使えることを知り,自分のPCにも入れてみました.
intelコンパイラのMKLを使えば,きっとCPU使用率をパンパンにして大規模連立方程式を解くことができるでしょう.
Pardisoとは
PARDISOはスイスのバーゼル大学(Universität Basel)で開発され、提供されている疎行列連立一次方程式の直接法ソルバーで、 Parallel Sparse Direct Solver の略です。
PARDISOはインテル®マス・カーネル・ライブラリー (インテル®MKL)にも含まれており、 次のような特徴があります。
実数または複素数、対称、構造対称または非対称、正定値、不定値またはエルミートの行列に対応
Fortran、C/C++から利用可能
高速で、メモリー効率が良い
共有メモリ型のプロセッサーでの並列計算に対応し、並列化効率がよい
引用元:計算力学研究センター
Eigenとは
Eigenは、線形代数、行列およびベクトル演算、幾何学的変換、数値ソルバー、および関連するアルゴリズム用のテンプレートヘッダーの高レベル C ++ ライブラリです。Eigenは、バージョン3.1.1以降のMozilla Public License2.0でライセンスされているオープンソースソフトウェアです。
引用元:Wikipediaを翻訳
マシン情報
ディストリビューション: Ubuntu
バージョン: 18.04.5 LTS
Intel(R) Core(TM) i9-10900X CPU @ 3.70GHz
物理コア数:1
総スレッド数:20
公式にもある通り,Xeonを使うのが最適だと思いますが,Xeonでなくとも動くと思います.
今回はお試しなので,dockerでサクッとみるだけにします.
手順
dockerで導入
公式からdockerイメージをpullしてrunするだけです.
Intel® C++ Compiler Classicを使うので,"High-Performance Computing"から落としてきます.
docker pull intel/oneapi-hpckit
docker run -it intel/oneapi-hpckit
intel oneAPIが入ったコンテナが立ち上がるので,このターミナルは一旦置いておきます.
Eigenを使ったコードを作る
Eigenには,pardisoを簡単に使えるような"PardisoSupport" wrapperがデフォルトで入っています.
Eigenをダウンロードして適当なところ(ここでは相対パス"../vendor/")に置き,
下のようなコード"test_pardiso.cpp"を作りました.
Xという中身がランダムな10000×10000の疎行列について解きます.
一応比較対象としてEigen自身のLU分解も入れました.
# include <iostream>
# include <random>
# include <chrono>
# include <Eigen/Sparse>
# include <Eigen/PardisoSupport>
using namespace Eigen;
typedef Eigen::Triplet<double> T;
int main()
{
std::default_random_engine gen;
std::uniform_real_distribution<double> dist(0.0, 1.0);
int rows = 10000;
int cols = 10000;
std::vector<T> tripletList;
for (int i = 0; i < rows; ++i)
for (int j = 0; j < cols; ++j)
{
auto v_ij = dist(gen); //generate random number
if (v_ij < 0.1)
{
tripletList.push_back(T(i, j, v_ij)); //if larger than treshold, insert it
}
}
SparseMatrix<double> X(rows, cols);
X.setFromTriplets(tripletList.begin(), tripletList.end()); //create the matrix
VectorXd b = VectorXd::Zero(rows);
b(0)=1.0e-5;
std::cout << "start to computation" << std::endl;
auto t_start = std::chrono::system_clock::now();
PardisoLU<SparseMatrix<double>> solver;
solver.compute(X);
auto x = solver.solve(b);
if (solver.info() == Eigen::Success)
std::cout << "successed." << std::endl;
else
std::cerr << "failed." << std::endl;
for (int i = 0; i < 5; i++)
std::cout << x[i] << std::endl;
auto t_end = std::chrono::system_clock::now();
SparseLU<SparseMatrix<double>> solver2;
solver2.compute(X);
auto x2 = solver2.solve(b);
if (solver2.info() == Eigen::Success)
std::cout << "successed." << std::endl;
else
std::cerr << "failed." << std::endl;
for (int i = 0; i < 5; i++)
std::cout << x2[i] << std::endl;
auto t_end2 = std::chrono::system_clock::now();
auto t_dur = t_end - t_start;
auto t_dur2 = t_end2 - t_end;
auto t_sec = std::chrono::duration_cast<std::chrono::seconds>(t_dur).count();
auto t_sec2 = std::chrono::duration_cast<std::chrono::seconds>(t_dur2).count();
std::cout << "PARDISOLU Computation time: " << t_sec << " sec \n";
std::cout << "EigenLU Computation time: " << t_sec2 << " sec \n";
}
コンパイル
OpenMP並列で解いていきます.
まず,ホスト側のターミナルを操作します.コードとEigenが入ったディレクトリをdockerコンテナの適当なディレクトリに送ります.
docker cp <your code> <docker ID & pass>
次に,コンテナ側のターミナルを操作します.コードが入ったディレクトリに移動し,コンパイルします.
cd <your code's pass>
icpc -std=c++11 -O3 -qopenmp -mkl -DESIGN_USE_MKL_ALL -I../vendor/ test_pardiso.cpp -o pardiso -lm -qopenmp -mkl
Eigenライブラリが"test_pardiso.cpp"に対して"../vendor"のパスにあります.
オプションは適当です.もっと良いコンパイルの方法を知っている方がいましたらお願いします.
結果
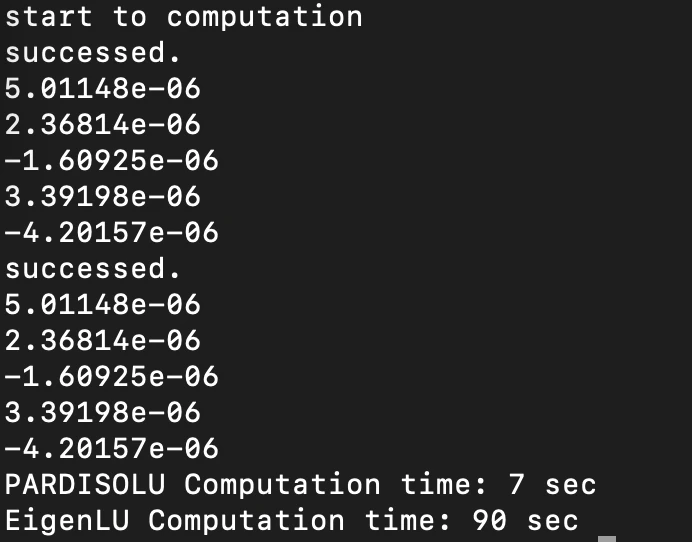
PARDISOのLU...7秒
EigenのLU...90秒
まとめ・感想
Eigenもかなり早いライブラリとして有名なので,そこから10倍もの差がつくのには驚きました.
topコマンドでCPU使用率を眺めていたのですが,確かにPARDISOのときはCPUフル稼働でした.
対称行列はCG法などが最適だと思いますが,行列の質によっては十分選択肢になると思います.
大規模計算を解くときは大抵スパコン等機関のマシンを使うとは思いますが,デバッグ用として個人PCにも入れる価値はあるのかもしれません.
intel oneAPIはたくさんの機能があるので,色々使いこなせるようになりたいです.
一応githubも公開しておきます.
https://github.com/dwatanabee/PardisoSolverinEigen
(4月21日追記)
Eigenのドキュメントによると、SparseLUクラスはopenmp非対応らしいです.まあsequentialでもpardisoの方が数倍早いですが…