はじめに
文字列データの列を含むDataFrameで、欠損値補完を行おうとしてハマったのでメモします。
欠損値補完とは
存在しないデータを周囲のデータを利用して、補完すること。
欠損値の例
例えば、以下のようなデータがあったとしよう。gender列の5行目がunknownとなっている。補完の方法は平均値、中央値を使うなどいろいろあるが、今回は単純に多い方の性別であるmaleで補完したい。

やったこと
学習器にデータを入力するためには、文字列データを数値データに変換する必要がある。そこで、maleを0、femaleを1に変換したのち、欠損値補完を行うコードを書いた。つまりunknownを0(male)に置き換える。
import pandas as pd
from sklearn.preprocessing import Imputer
df_sample = pd.read_csv('sample.csv')
gender_map = {'male':0, 'female':1}
df_sample['gender'] = df_sample['gender'].map(gender_map) # male を 0 に female を 1 に置き換え
imr = Imputer(missing_values='unknown', strategy='most_frequent', axis=0)#補完器オブジェクト作成
imputed_data = imr.fit_transform(df_sample) #補完を適用
missing_values に欠損値、 strategyに補完方法(平均なら mean, 中央値なら median)を指定する。
ここで、以下のようなエラーに遭遇。
TypeError: ufunc 'isnan' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''
文字列を数値に置き換えた後のDataFrameを見てみると以下のようになっていた。
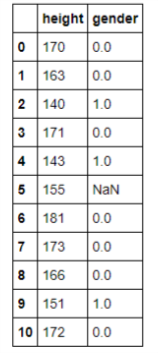
これは、DataFrameの各列はSeriesオブジェクトとなっていて、全ての値が同じ型となっていることが原因だった。
つまり、文字列の unknown と数値の 0,1 は共存できない。
解決法
コードの'unknown'の部分を'NaN'に変えてみると上手く行った。
import pandas as pd
from sklearn.preprocessing import Imputer
df_sample = pd.read_csv('sample.csv')
gender_map = {'male':0, 'female':1}
df_sample['gender'] = df_sample['gender'].map(gender_map) # male を 0 に female を 1 に置き換え
imr = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)#補完器オブジェクト作成
imputed_data = imr.fit_transform(df_sample) #補完を適用
参考文献
Python 機械学習プログラミング 達人データサイエンティストによる理論と実装 (インプレス社)