本記事はSQLの単体パフォーマンス検証について記載してます。
尚、本記事のSQL単体パフォーマンス検証とは無風(他に負荷が発生していない)状態でSQLの実行計画や性能を検証することを指しています。また対象とするDBはoracleを想定しています。
実行計画取る方法と特徴を知る
まずは方法と特徴を記載します。
| 実行計画の取得方法 | 特徴 |
|---|---|
| EXPLAIN PLAN | SQLを実行せずに実行計画を取得できる。 ただし実際に実行していないため実行時間やIO量はわからない。 待機イベントなどの発生状況も分からない。 実行計画を確認するだけなら便利な方法。 |
| AUTOTRACE | SQLを実際に実行し実行計画や実行時の統計を取得する。 実際に発生するIOなどは分かるが実行計画のどこで発生したか内訳までは分からない。 待機イベントなどの発生状況も分からない。 |
| DBMS_XPLAN.DISPLAY_CURSOR | SQLを実際に実行し実行計画や実行時の統計を取得する。 IOの発生タイミングなども詳細に分かるのでSQL単体での性能検証に適している。 ただし待機イベントなどは分からないため複数の負荷が影響を与えるような高負荷検証(WEBページのPV数分の負荷に耐えられるか判断するような検証等)には不向きなイメージ。 |
| SQLトレース | SQLを実行し実行計画や実行統計、設定によっては待機イベントまで分かる。 かなり詳細な情報まで取得できる。 ただし情報取得自体のオーバーヘッドが発生する。 結果はファイル出力されるがTKPROFというユーティリティで整形しないと読みにくい。 |
| OEMを利用する | OEM = Oracle Enterprise Managerのこと。 そもそも実行計画だけを取得するためのツールでは無いが便利なので記載しておく。 実行されたSQLを検索し実行計画や様々な情報、AWRやASHレポートの確認ができる。 また、SQL監視機能では実行時間が長いSQLやパラレル実行されたSQLの詳細情報が確認できる。 SQL監視にはMONITORヒントを付けてSQLを実行することで強制的に監視対象として出力する事も可能。 |
自分の経験的には
SQL”単体”でのパフォーマンス検証では主に「DBMS_XPLAN.DISPLAY_CURSOR」を使う事が多いです。
「DBMS_XPLAN.DISPLAY_CURSOR」でSQLが遅い原因が分からない場合は「OEM」を併用したり、「SQLトレース」を取ってみたりするのが良いと思います。
以降では「DBMS_XPLAN.DISPLAY_CURSOR」の取り方を説明していきます。
「DBMS_XPLAN.DISPLAY_CURSOR」による検証の実施方法
準備
実際に検証する前には色々と考慮しなくてはいけない事があります。
準備段階として以下のような事をします。
実行計画を取る環境を選定する
まずは検証を実施するための環境を選定する必要があります。
注意すべき点はできるだけ実際に運用される本番環境に近い環境で実施する事です。
【本番環境で検証できる場合】
データの揃っている本番環境で検証できる場合
実際にSQLが実行される環境なので検証の精度も高くなります。
ただし本番環境がカットオーバーされている場合は
検証による負荷が影響を与えるかもしれません。
特に後述するSGAキャッシュクリアは注意が必要です。
クリア後に負荷が高騰してしまう危険性があります。
【本番相当の環境で検証する場合】
| 環境イメージ | |
|---|---|
| 本番環境の各種設定の再現 | |
| テーブルやINDEX等のオブジェクトの再現 | |
| 登録されたデータの再現 | |
上記イメージの様な本番相当の環境で検証する場合でもそれなりに精度は高くなります。
ただしブロック内のレコードの配置や運用で発生するような劣化要因(行移行やインデックスの断片化など)まで再現することは難しいと思います。
そのため本番環境よりはどうしても精度は落ちてしまいます。
【データを再現していない環境で検証する場合】
| 環境イメージ | |
|---|---|
| 本番環境の各種設定の再現 | |
| テーブルやINDEX等のオブジェクトの再現 | |
| 登録されたデータの再現 | |
上記イメージのようにデータが再現されていない環境で
検証する意味はほとんど無いのでお勧めしません。
データの内容が異なると統計情報も異なってしまいます。
そのため実行計画も異なる物になる可能性があるからです。
ただし、裏技的な方法かもしれませんが
DBMS_STATSには統計情報を直接設定できるプロシージャが存在します。
(SET_TABLE_STATSやSET_INDEX_STATS等)
これを利用し本番環境と同じ統計情報を再現すれば実行計画は再現できるかもしれません。
ただし実際に発生するIOなどは再現できません。
統計情報を取得する
正しい実行計画を作成するのには統計情報が必要になります。
統計情報の取得方法や取得時の設定値は本番環境と合わせましょう。
合わせないとその食い違いにより、取得される統計情報も異なる物になる可能性があります。
(とはいえ本番環境かつサンプリング率100%で検証しない限り多少なり食い違いは発生するとは思いますが、、、)
【ヒストグラム統計を取得する場合の注意点】
統計情報の一つにヒストグラム統計という物があります。
ざっくり説明すると
「where条件にカラムが指定された時にどんなアクセス方法が妥当か判断する材料」
となる情報の一つです。
このヒストグラム統計をとる場合は少し注意が必要です。
ヒストグラム統計の材料としてSQLで実行された実績(where条件にカラムがどのように指定されたか)が必要です。
そのため検証したいSQLを一度実行してから統計情報を取得する必要があります。
※ヒストグラム統計については以下の「しばちょう先生」の記事が参考になりました。
参考:オプティマイザ統計情報の管理 ~ヒストグラムの効果を体験してみる~
SQLのバインドパラメータを選定する
検証するSQLの仕様を考慮しつつ設定するバインドパラメータを選定します。
oracleにはバインドピークという機能が存在し、9i以降のバージョンではデフォルトで有効となっています。
この機能が有効な場合はSQLがハードパースされる際
そのバインドパラメータを覗き見し、バインドパラメータの内容を考慮して効率の良い実行計画を作るようになります。
※バインドピークについては下記の記事が参考になります。
参考:Oracleデータベースの頭脳 「オプティマイザ」徹底研究-
※バインドピーク(Bind peek)を参照
このバインドピーク機能ですが実行計画が安定しなくなる等のデメリットもあります。
あえてOFFにしてある可能もあるかもしれません。事前に設定を確認しておいた方が良いでしょう。
【どんなパラメータを選ぶか?】
バインドパラメータの内容について、まずは負荷が高い組み合わせや値で検証した方が良いと思います。
例えば数千件や数万件、それ以上のレコードを処理対象とするSQLに対し
1、2件しか処理対象にならないようなバインドパラメータを設定して検証して
問題なしと判断するのはちょっと無理があります。
また実行計画が読めるようになり、検証に慣れてくると経験からこんなパラメータにすると(実行計画上の)結合方法が変わるんじゃないか、駆動表が変わりそう等の予想ができるようになってきます。
そういう点を考慮してバインドパラメータの選定もできるようになると良いと思います。
実施
準備ができたら実際に検証を行なっていきます。
以下の手順の通り実行してみます。
SQL*Plusにて接続する
まずはDBへSQL*Plusにて接続を行います。
検証のための設定を行う
検証をやり易くするような設定や結果を見易くするような設定。
実行統計を残すための設定も行います。下記のコマンドをSQL*Plusにて実行してください。
-- SQLBLANKLINESはSQL内に空行を許容するか否かの設定、別に設定しなくてもOK
set SQLBLANKLINES ON
-- 以下の5つは表示に関する設定
set linesize 5000
set pagesize 1000
set newpage none
col plan_plus_exp for a120
set trimspool on
-- 内部的なSQLの実行計画を取ってしまうのを避ける設定
set serveroutput off
-- セッション内の実行統計を残すための設定
alter session set statistics_level=all;
SGAキャッシュクリアをする
SGA領域に検証対象のSQLが既にハードパースされていると、既存の実行計画で実行される可能性があります。
(ただし絶対ではありません。条件を満たせばオプティマイザが1つのSQLに対して複数の実行計画を作る場合があります。)
また処理対象となるブロックがバッファキャッシュにのっている場合
その量次第で処理時間や後述するReads列の結果にムラが生じてしまう可能性があります。
そのため以下のコマンドを実施しSGA領域のキャッシュをクリアします。
ALTER SYSTEM FLUSH SHARED_POOL;
ALTER SYSTEM FLUSH BUFFER_CACHE;
【キャッシュクリアに関するメモ1】初回だけ極端に遅い
毎回キャッシュクリアしているのに初回や久しぶりに実行したSQLが異常に遅い場合があります。
この様な場合、もっとも怪しいのはOracleのデータが保存されているストレージ側のキャッシュが影響を与えている可能性があります。ストレージ側のキャッシュはSGAのキャッシュクリアでは消えないため差が生じてしまいます。
【キャッシュクリアに関するメモ2】キャッシュクリアしたら異常なIO負荷が発生した
キャッシュクリア後は様々なデータをキャッシュにあげなおすため負荷が上がりやすいです。
サービス稼働中の本番環境で行うのは危険な可能性があります。
またキャッシュが無い状態だとPre-Warming機能が発動する可能性もあります。
Pre-Warming機能については下記の記事の「Pre-Warming機能(演習5)」が参考になります。
参考:AWRレポートを読むステップ1.バッファキャッシュ関連の待機イベントと統計情報
※Pre-Warming機能(演習5)を参照
実行計画を取得するSQLを実行
次に実行計画を取りたいSQLを実行します。
| 物理名 | 型 | 論理名 | 補足 | |
|---|---|---|---|---|
| PK | MY_NUMBER | CHAR(10) | マイナンバー | |
| NAME | VARCHAR2(20) | 名前 | 例:Tanaka Taro | |
| AGE | NUMBER(3) | 年齢 | ||
| GENDER | CHAR(1) | 性別 | M:男性 F:女性 |
今回は上記のPERSONテーブルに対し、下記の様なSQLを実行してみます。
var myNumber CHAR(10);
exec :myNumber := '0000000001';
select * from PERSON where MY_NUMBER = :myNumber;
結果を取得する
SQLの実施が完了したら下記のSQLを発行することで実行計画を確認します。
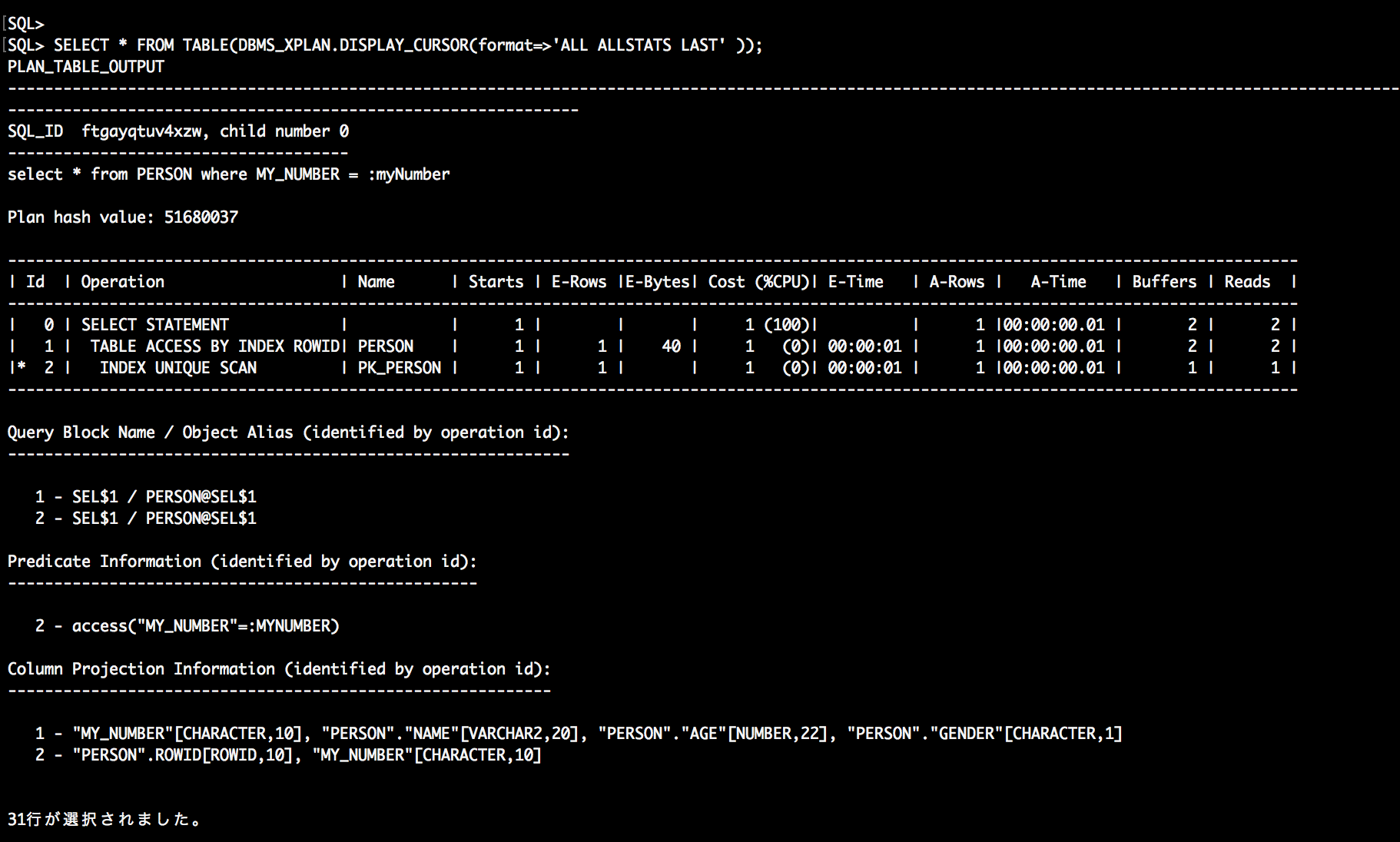
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(format=>'ALL ALLSTATS LAST' ));
そうすると下記の様な結果が得られます。
【さらに詳細な情報を見たい場合】
formatをALLからADVANCEDに変更することで、更に詳細な情報が参照できます。
※ADVANCEDは隠しパラメータだったと思います。マニュアルなどには載っていないかもしれません。
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(format=>'ADVANCED ALLSTATS LAST' ));
実際に実行してみると
- 実際に付与されたヒント(Outline Data)
- バインドピークで照会されたバインド値(Peeked Binds)
等が追加で表示されます。
【SQLIDを指定して情報を見たい場合】
下記の様にSQLIDを指定して取得することもできます。
※XXXXXXの部分をSQLIDで置き換えて実施します。
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('XXXXXX', null, 'ADVANCED ALLSTATS' ));
結果の確認
出力された実行計画を確認します。
実行計画はインデントの一番深いId、もし同一のインデントが複数存在する場合は上に位置するIdからスタートします。
今回取得した実行計画ではId2からスタートし下記の様に処理されています。
| 順番 | 対応Id | 処理の流れ |
|---|---|---|
| 1. | Id2 | PK_PERSONに対するINDEX UNIQUE SCANが発生 Idに※印がついていた場合 Predicate Information (identified by operation id) を確認します。 するとIdに対応したaccessが発生しており、MY_NUMBERカラムを元にインデックスにアクセスした事が分かります。 |
| 2. | Id1 | TABLE ACCESS BY INDEX ROWIDが発生 インデックスのROWIDを元にテーブルの対象レコードにアクセスしています。 |
| 3. | Id0 | 終了 |
その他、結果の見方については下記のリンク先が参考になると思います。
参考:Oracle Database Technology Night~集え!オラクルの力(チカラ)~
パフォーマンス・チューニングの極意 ※SQLチューニングの項目を参照
また1点注意しておくと下記の値はオプティマイザが立てた予想値です。
予想なので実際の値と比べ乖離している可能性があります。
- E-Rows = 予想行数
- E-Bytes = 予想行数に対象の平均列サイズの合計を掛けた値
- Cost (%CPU) = 予想コスト
- E-Time = 予想処理時間
参考:オプティマイザとオプティマイザ統計の収集について(2)
※CBOのコストについてを参照
下記は実行統計なので実際にSQLを流して発生した情報です。
この辺りは注視すべきです。
- Starts = そのIdの処理が実行された回数
- A-Rows = 実際の処理行数(※取得行数と必ず一致するわけではない。あくまで処理した行数)
- A-Time = 実際の処理時間
- Buffers = 実際のバッファ読み込みブロック数
- Reads = 実際の物理読み込みブロック数(※バッファ読み込みよりIOネックになりやすい)
Readsはバッファキャッシュに処理対象のブロックが存在すると0となります。
全て存在すると列自体が表示されません。
また、パラレル実行した場合やメモリー操作の有無など処理の内容によって出力される列の種類が変わることがあります。
参考:実行計画の確認方法
※「statistics_level=all+dbms_xplan.display_cursorで確認する(9i~)」を参照
【おまけ】観点や過去経験した事象
自分が気にする観点とか過去経験した事象などを取り止めとなく記載しています。
【スキャン方法について】
■ INDEXスキャンすべき箇所が「TABLE ACCESS FULL」になっていないか?
逆に「TABLE ACCESS FULL」すべき箇所がINDEXスキャンになっていないか?
「TABLE ACCESS FULL」よりINDEXスキャンの方が絶対的に早いとは限りません。
それぞれブロックの読み込み方に特徴があります。
| スキャン方法 | ブロック読み込みの特徴 |
|---|---|
| TABLE ACCESS FULL | 複数のブロックを同時に読み込みます |
| INDEXスキャン | ほとんど(例外有り)はブロックをシーケンシャルに読み込みます |
TABLEの大半のレコードにアクセスしたり、あまりにアクセスするレコードが多い場合
INDEXスキャンより複数ブロック読み込みができる「TABLE ACCESS FULL」の方が早い事があります。
■ INDEX UNIQUE SCANやINDEX RANGE SCANが発生している場合
「Predicate Information (identified by operation id):」を注視する
Predicate Informationにはaccessやfilterといった情報が表示されます。
accessはINDEXのリーフノードのブロックにどのようにアクセスするか記載されています。
特にINDEX RANGE SCANはaccessによって(インデックスのリーフノードを横へ移動する)範囲が決まるので性能に直結します。
accessはとても重要な情報なので、もし妥当な条件になっていない場合はインデックスのカラム定義順が正しいか確認します。
またfilterはアクセスする範囲を決める条件にはなりません。
アクセスする範囲内で必要なレコードのみ取得していくための条件が記載されています。
とはいえ、こちらも性能に影響を与える重要な情報です。
■ INDEX FULL SCANが発生している場合はレコード数に注意
INDEX FULL SCANはリーフノードのブロック全てを並び順を保持しながらシーケンシャルに読み込み、取得条件があればfilterしていきます。
インデックスの並びを保持しているためソート処理などを省略できる事があります。
しかしFULLスキャンするのに複数ブロック読み込みができません。
レコードが少ないテーブル以外はこのスキャン方法は不向きです。
■ INDEX FAST FULL SCANが発生している場合は本当にそれが必要か考える
INDEX FAST FULL SCANはINDEXのスキャン方法ですが、「TABLE ACCESS FULL」に近いアクセス方法です。
複数ブロックを読み込む事ができます。インデックスの並び順は保持しません。
発動する条件はINDEXが処理に必要なカラム全てを保持している事。
多くの場合インデックスは保持しているカラムがテーブルより少ないので1ブロックに含まれるレコード数は多くなるはずです。そのため「TABLE ACCESS FULL」よりも読み込みIOや速度は有利になるはずです。
しかしアクセスすべきレコードが少量の場合は他のINDEXスキャンの方が良いでしょう。
■ INDEX SKIP SCANが発生している場合はINDEX設計を見直す
INDEX SKIP SCANはインデックスの第一キーをaccessに利用せずインデックスをスキャンします。
何回かINDEX SKIP SCANが発生して性能問題が発生した場面を見た事があります。
大抵の場合は性能が悪いのでINDEX RANGE SCANになるようなINDEXを作り直した方が良いです。
【結合方法について】
■ 結合方法の選択が妥当か確認します
各結合方法の特徴により妥当かどうか判断します。
| 結合方法 | 特徴 |
|---|---|
| NESTED LOOPS JOIN | 片方のテーブル(駆動表)を検索条件(where)で絞り込んだレコードを元にループし もう片方のテーブルと結合条件(ON句)を元に紐付けます。 駆動表には検索条件(where句)で絞り込むためのインデックス、 もう片方のテーブルには結合条件(ON句)でアクセスするインデックスがあると良いです。 駆動表がとても重要で、正しいテーブルを選択しているかは気にするべきです。 駆動表の絞り込み後にレコードが小さくなる(カーディナリティが低い)ほど効率が良くなります。 逆に駆動表が大きくなるとループ数が増加し、性能が悪くなります。 処理途中でも順次レコードの返却できる特徴もあり 「COUNT STOPKEY」が発生するような最初の数行を返す処理との相性が良いです。 |
| HASH JOIN | 両方のテーブルを検索条件(where句)で絞り込んだ後、少ない方をハッシュ関数を用いてハッシュテーブル化します。 その後もう片方とハッシュ関数を用いて結びつけます。 そのため両方のテーブルに対し検索条件(where句)で絞り込むためのインデックスがあると良いです。 どちらかのテーブルに対する絞り込みに偏りがあまり無い場合 両方とも多めのレコードにアクセスする必要がある場合に向いています。 ただしハッシュテーブル化するレコードが多すぎた場合 メモリ内で処理仕切れず一時表に書き込みが行われる事があります。 その場合はパフォーマンスの劣化が発生する事があります。 |
| MERGE JOIN | 両方のテーブルを絞り込んだ後にソートし、順番に比較していく事で紐付けを行います。 結合条件(ON句)が不等号の場合に発生する事があります。 等号の場合はHASH JOINの方が効率が良いのでそちらを選ぶと思います。 実際に発生しているのを見たのは数回しかありません。 |
| MERGE JOIN CARTESIAN | 直積結合、結合条件を記載しないSQLなどで発生しているのを見た事があります。 発生していたらSQLの間違いではないか、本当にそれでいいのかを疑います。。。 結合対象のレコードがかなり少量でない限りパフォーマンスは大変なことになると思います。 |
【WITH句について】
OracleにはWITH句があり、副問合せを切り出すような形で記載する事ができます。
可読性が良くなったり複数箇所で利用したりできるメリットがあります。
このWITH句ですが、一時表を作る場合があります。
それ自体は悪い事では無いです。パフォーマンス的にメリットを生むことだってあると思います。
しかし、あまりに高頻度で利用されるSQLだったり
必要以上にあちこちで利用し一時表の作成頻度が多すぎる場合
内部的な一時表の削除処理により負荷が高まってしまった。。。という事が過去にありました。
もし上記のような事が起きた場合、対策としては下記が考えられます。
- WITH句を辞めてインラインビューに変更する
- INLINEヒントを付与する
INLINEヒントはオプティマイザにWITH句をインラインビューに変換するよう促すヒントです。
逆に一時表を作成させたい場合はMATERIALIZEヒントを付与します。
※ただしINLINEヒント、MATERIALIZEヒントは共に隠しヒントなのでその点は認識した上で使用する必要があります。
【特殊なアクセス方法】
| INDEX SCANからのTABLEアクセス | |
|---|---|
| TABLE ACCESS BY INDEX ROWID | PERSON |
| INDEX RANGE SCAN | IDX_PERSON |
実行計画を見ていると上記のようなアクセスを良く見かけます。
何をしているかというと
1. インデックスによるスキャン(INDEX RANGE SCANの部分)
2. インデックスのROWIDを元にテーブルのレコードにアクセス(TABLE ACCESS BY INDEX ROWIDの部分)
というような流れで処理をしています。
「TABLE ACCESS BY INDEX ROWID」はインデックスを対象としたスキャンに比べ
処理対象のレコードが多くなるとIO(BuffersやReads)が増えやすい傾向にあります。
一般的なテーブルはインデックスと異なりレコードの並び順を保持しておらず
対象のレコードが同一ブロックにかたまり難いため取得対象のブロックがバラけやすくIOが増える要因となっています。
ここではこの「TABLE ACCESS BY INDEX ROWID」を省略させたり
IOを軽減させる少し特殊なアクセス方法を挙げます。
■ カバーリングインデックス
「TABLE ACCESS BY INDEX ROWID」はインデックスで取得対象を絞り込んだ後、
インデックスが保持していないカラムを参照するためにテーブルにアクセスします。
もしインデックスが必要なカラムを全て保持しているカバーリングインデックスの場合
テーブル参照が必要無くなり「TABLE ACCESS BY INDEX ROWID」は実行計画から省略されます。
■ 索引結合(INDEX_JOIN)
索引結合は一つのテーブルに対し複数のインデックスを使用してアクセスする結構珍しいアクセス方法です。
| 実行計画イメージ | |
|---|---|
| HASH JOIN | |
| INDEX RANGE SCAN | IDX_PERSON_1 |
| INDEX RANGE SCAN | IDX_PERSON_2 |
発生するとインデックススキャンの結果どうしをHASH JOINする実行計画になり
「TABLE ACCESS BY INDEX ROWID」が発生しなくなります。
ただし、発生させるにはSQLの問い合わせに必要なカラムを全て使用するINDEXでまかなわなくてはいけません。
任意条件が多い動的SQLに対し、効率の良いカバーリングインデックスの作成が困難な際
この索引結合をSQLチューニングに用いた事があります。
ただし発生条件の厳しさからうまく発生させるのが結構難しく
想定通りチューニングできたのは数回程度です。
またSQLに参照するカラムが追加になるとすぐ発生しなくなるのでその点も使い難いところかと思います。
ちなみにOracleのヒントにこの索引結合を促すINDEX_JOINヒントというものがあります。
■ ビットマップ・アクセス・パス(INDEX_COMBINE)
ビットマップ・アクセス・パスも一つのテーブルに対し複数のインデックスを使用してアクセスする結構珍しいアクセス方法です。
| 実行計画イメージ | |
|---|---|
| TABLE ACCESS BY INDEX ROWID | PERSON |
| BITMAP CONVERSION TO ROWIDS | |
| BITMAP AND | |
| BITMAP CONVERSION FROM ROWIDS | |
| INDEX RANGE SCAN | IDX_PERSON_1 |
| BITMAP CONVERSION FROM ROWIDS | |
| INDEX RANGE SCAN | IDX_PERSON_2 |
上記イメージのようなアクセスパスが発生します。
何が起こっているかというと下記のような事が起こっています。
1. それぞれのインデックスをスキャン (INDEX RANGE SCAN部分)
2. 結果を元にメモリ内にBITMAPを作成 (BITMAP CONVERSION FROM ROWIDS部分)
3. BITMAPによるAND演算を行い両方のスキャン結果を満たすレコードを特定(BITMAP AND部分)
4. 特定したレコードのROWIDSに再変換 (BITMAP CONVERSION TO ROWIDS部分)
5. ROWIDを元にテーブルのレコードにアクセス(TABLE ACCESS BY INDEX ROWIDの部分)
索引結合(INDEX_JOIN)と異なり「TABLE ACCESS BY INDEX ROWID」は発生します。
1つ1つのインデックスでは絞り込みが不十分でも
複数のインデックスで絞り込めば「TABLE ACCESS BY INDEX ROWID」の発生前に対象レコードを
十分少なくさせられる場合にメリットが発生します。
こちらも任意条件が多い動的SQLに対し、効率の良いカバーリングインデックスの作成が困難な際
SQLチューニングの方法として用いた事があります。
こちらは索引結合(INDEX_JOIN)に比べて発生させやすいイメージがあります。
ちなみにOracleのヒントにこのビットマップ・アクセス・パスを促すINDEX_COMBINEヒントというものがあります。
【EXISTSについて】
EXISTSの方がINや結合を使用したSQLよりも優れているという記述をよく見ます。
ただしそれは絶対では無いはずです。EXISTSの特徴を理解して使用するべきです。
EXISTSの特徴は
- 親側(EXISTSの外)のテーブルを元に副問い合わせ側(EXISTSの中)のテーブルにアクセスする
- 副問い合わせ側(EXISTSの内)に紐づくレコードが1件紐づいた時点で取得対象と判断する
※よく比較されるINは逆に副問い合わせ側(IN句内)から処理するイメージ
親側(EXISTSの外)のテーブルには検索条件(where句)で絞り込むためのインデックス
さらに副問い合わせ側(EXISTSの内)に紐づくレコードをピンポイントでアクセスできるようなインデックスがあると、2番目の特徴が有効に作用し不必要なレコードにアクセスせず効率が良くなります。
上記の特徴により、
親側(EXISTSの外)のテーブルが少ない(十分に絞り込まれる)場合はEXISTSの使用が向き、
逆に親側(EXISTSの外)のテーブルが多い(十分に絞り込まれない)場合はアクセスする回数が多くなりすぎて効率が悪くなるはずです。
それでもあちこちでEXISTSが優れていると言われる理由は、
効率が悪いEXISTSのSQLを書いていても、オプティマイザが内部的に
効率が良い方法に変えてくれる事が多いからなのかなと思っています。
とはいえ仕様に則り効率を意識してSQLを書いた方が安全だというのが自分の見解です。
【補足】
効率の悪いEXISTSを効率が悪いまま実行する方法としてNO_UNNESTヒントを使用する方法があります。
NO_UNNESTを指定する事でオプティマイザに勝手に変換(ネストの解除)しないように命令できます。
EXISTSの使用を迷った際には使ってみるのも良いかもしれません。
SELECT
*
FROM TABLE_A A
WHERE
EXISTS (
SELECT /*+ NO_UNNEST */ 1 FROM TABLE_B B WHERE B.ID = A.ID
)
【パーティションが切られている場合】
パーティションを切った意図にもよりますが、以下の事は気にした方が良いと思います。
-
想定通りプルーニング(アクセスするパーティションの切り分け)が行われている事
-
必要が無いのにグローバルインデックス(パーティションをまたぐインデックス)を使用していない事