自社の後輩にJavaの参照の仕組みをスタック領域とJavaヒープ領域を用いて説明する機会がありました。
自分自身、この領域同士の関係性をまだ知らなかった頃はJavaの参照について色々と混乱していた記憶があります。
良い機会なので記事にまとめてみようと思います。
Javaの参照を実現する仕組み
Javaの参照を実現する為にJVMにはスタック領域とJavaヒープ領域が存在します。
この2つの領域によりJavaの参照は実現されます。
| 領域名 | 概要 |
|---|---|
| スタック領域 | 主にヒープ領域への参照情報を保持します。またプリミティブ型の値も保持します。 |
| JAVAヒープ領域 | オブジェクトの実際の値はこちらのメモリに保持します。 |
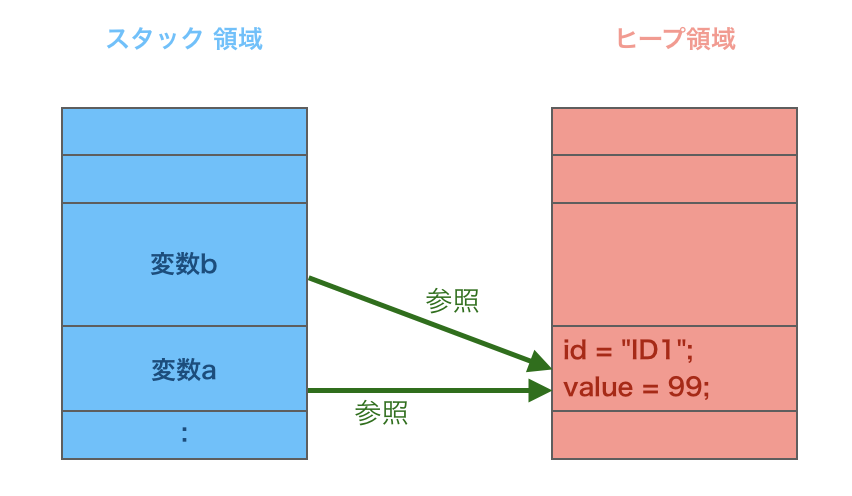
オブジェクトとプリミティブ型の値の保持方法の違い
Javaのオブジェクト(Classや配列など)はスタック領域にヒープ領域の参照情報を持ちます。
実際の値はヒープ領域に保持します。
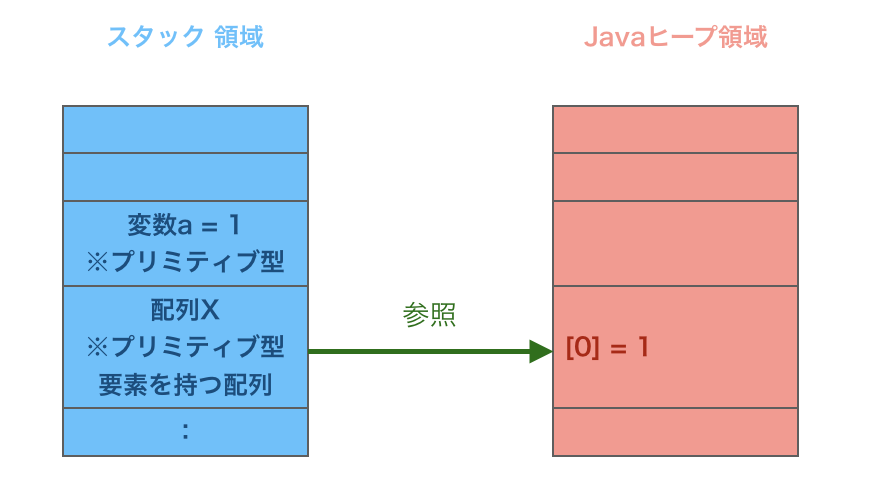
プリミティブ型はオブジェクトとは異なるメモリ管理が行われます。
プリミティブ型の変数を作成するとスタック領域に値を保持します。
※ただしプリミティブ型の配列はオブジェクトとして扱われる為ヒープ領域に値を保持します。
メソッドの引数に渡す時の挙動
メソッド引数へオブジェクトやプリミティブ型の変数を渡す際
スタック領域の内容が別のスタック領域にコピーされます。
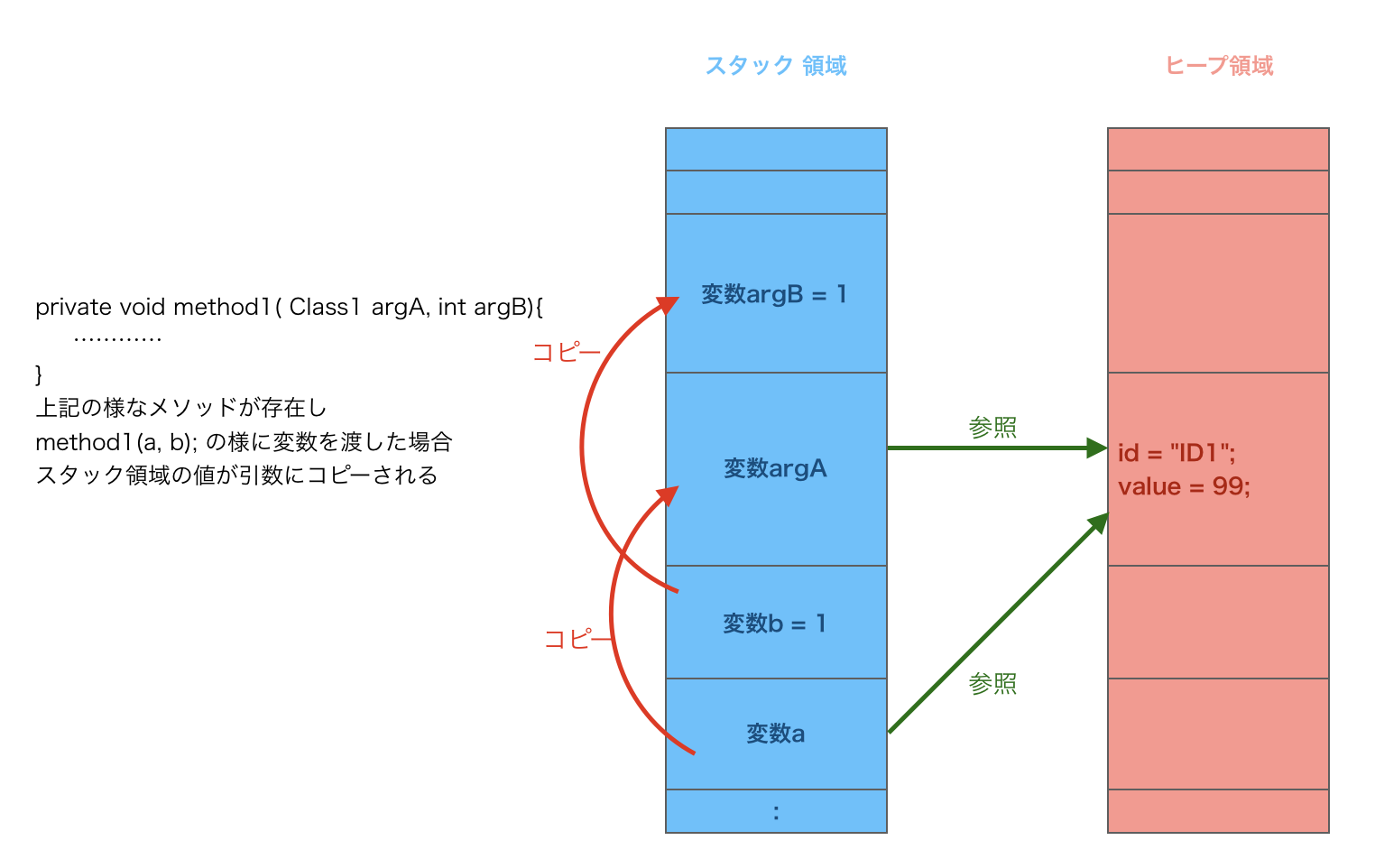
上記の様な場合、argAの参照は変数aと同じになる為
method1の内部で参照先の値を変更すると変数aにも影響を与えます。
※argBはプリミティブ型なので変数bとは切り離されています。
ソースコードサンプル
ここまで記載した内容が正しいか確認するため、ソースコードとその出力結果を照らし合わせて説明していきます。
例1
package test;
class Class1 {
String id;
int value;
}
public class Test {
public static void main(String[] args) {
Class1 a = new Class1();
a.id = "ID1";
a.value = 1;
// 操作【1】
Class1 b = a;
// 操作【2】
b.id = "ID2";
b.value = 2;
// 操作【3】
b = null;
// ここで出力される値は何になるか?
System.out.println("id:" + a.id);
System.out.println("value:" + a.value);
}
}
【操作内容】
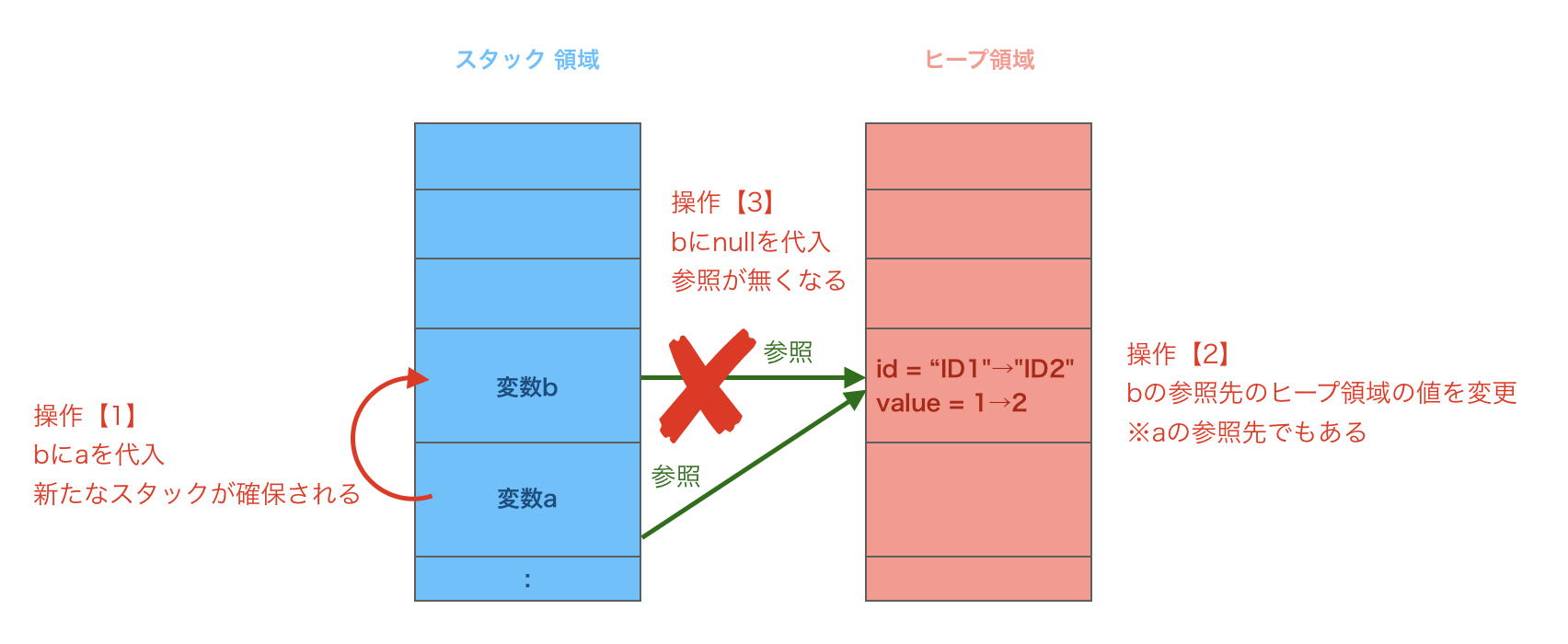
操作【2】により変数aの参照先の値も書き換えていることになります。
操作【3】により変数bの参照は削除されますがスタックが異なる変数aには影響はありません。
よって出力内容は下記の通りとなります。
id:ID2
value:2
例2
package test;
class Class1 {
String id;
int value;
}
public class Test {
public static void main(String[] args) {
Class1 a = new Class1();
a.id = "ID1";
a.value = 1;
// 操作【1】
method1(a);
// ここで出力される値は何になるか?
System.out.println("id:" + a.id);
System.out.println("value:" + a.value);
}
private static void method1(Class1 argA) {
// 操作【2】
argA.id = "ID2";
argA.value = 2;
}
}
【操作内容】
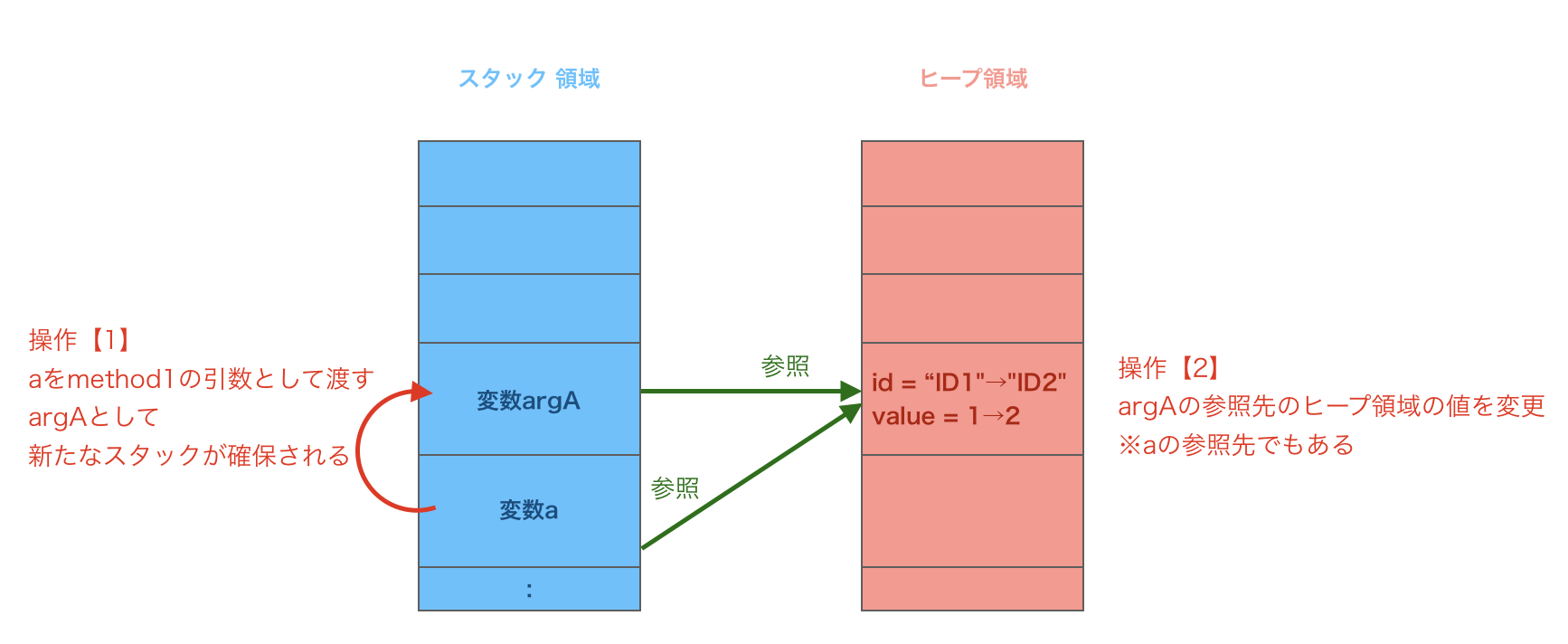
操作【2】により変数aの参照先の値も書き換えていることになります。
よって出力内容は下記の通りとなります。
id:ID2
value:2
例3
package test;
class Class1 {
String id;
int value;
}
public class Test {
public static void main(String[] args) {
Class1 a = new Class1();
a.id = "ID1";
a.value = 1;
// 操作【1】
method1(a);
// ここで出力される値は何になるか?
System.out.println("1回目=========");
System.out.println("id:" + a.id);
System.out.println("value:" + a.value);
// 操作【2】
method2(a);
// ここで出力される値は何になるか?
System.out.println("2回目=========");
System.out.println("id:" + a.id);
System.out.println("value:" + a.value);
}
private static void method1(Class1 argA) {
argA = null;
}
private static void method2(Class1 argA) {
argA = new Class1();
argA.id = "ID2";
argA.value = 2;
}
}
【操作内容】
例2と同じ様にメソッドの引数として変数aを渡しています。
操作【1】のメソッドはnullを代入してargAの参照を削除していますがスタックが異なる変数aに影響はありません。
操作【2】のメソッドは新たにClass1をnewしているため参照先が変数aと変わっています。
参照先が変わった後にidとvalueに値を設定しても変数aに影響はありません。
よって出力内容は下記の通りとなる。
1回目=========
id:ID1
value:1
2回目=========
id:ID1
value:1
例4
package test;
public class Test {
public static void main(String[] args) {
int a = 1;
// 操作【1】
int b = a;
// 操作【2】
b = 99;
// ここで出力される値は何になるか?
System.out.println("1回目=========");
System.out.println("a:" + a);
System.out.println("b:" + b);
// 操作【3】
method1(a);
// ここで出力される値は何になるか?
System.out.println("2回目=========");
System.out.println("a:" + a);
}
private static void method1(int argA) {
// 操作【4】
argA = 99;
}
}
【操作内容】
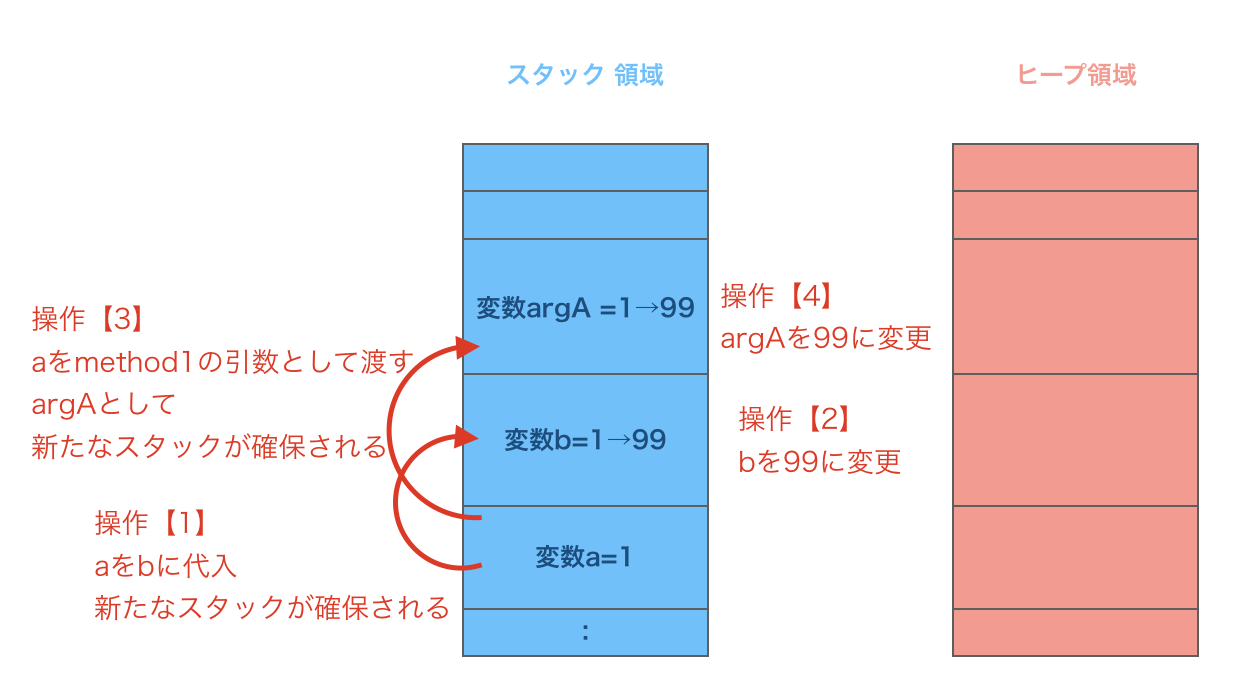
プリミティブ型の変数はそれぞれ独立してスタック領域に値を保持します。
それぞれの操作が別の変数に影響を及ぼす事はありません。
よって出力内容は下記の通りとなる。
1回目=========
a:1
b:99
2回目=========
a:1
例5
package test;
public class Test {
public static void main(String[] args) {
int a = 1;
// 操作【1】
int[] b = {a};
// 操作【2】
method1(b);
// ここで出力される値は何になるか?
System.out.println("a:" + a);
System.out.println("b[0]:" + b[0]);
}
private static void method1(int[] argB) {
// 操作【3】
argB[0] = 99;
}
}
【操作内容】
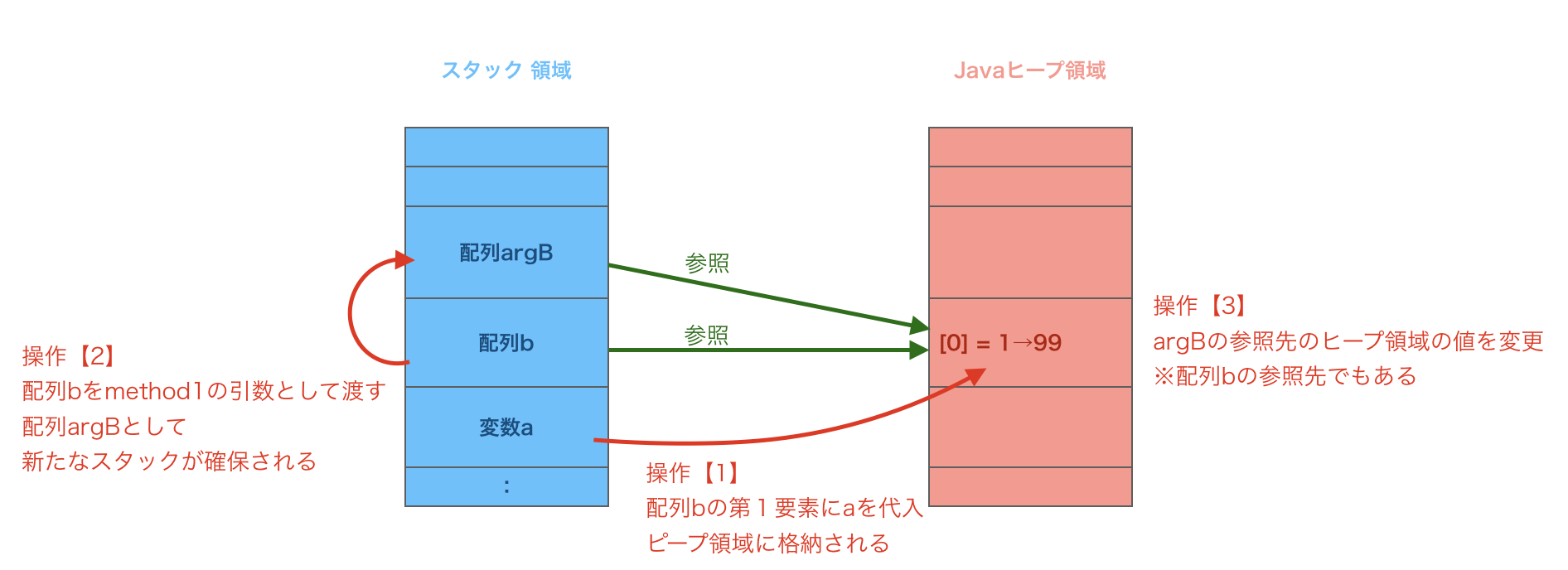
プリミティブ型でも配列として保持するとその値はヒープ領域に保存されます。
操作【3】で配列argBに変更を行うと同じ参照先を持つ配列bに影響を与えます。
よって出力内容は下記の通りとなる。
a:1
b[0]:99