こんにちは!
BeatFit エンジニアの飯塚です。
半年ぶりの投稿となります。
エンジニアになって半年たち、今は、フロントエンドとバックエンドを主に担当しております。
が、そろそろ社内のインフラを Heroku から AWS へ完全移管する話が出たため、今年の6月頃から、AWSの勉強を開始しました。
先日、AWS ソリューションアーキテクトの資格をとりました。(1回落ちました。。)
が、実務では、まだまだ全然使いこなせていないので、これからも頑張っていきたいところです。
今回、職場のコンテンツチーム(社長)より、動画の音声起こしができたら嬉しいと言う声が上がりました。
ちょうど、AWS Transcribe が 11/21に日本語対応されたので、この機会に触ってみたいと思います。
S3 アップロード → Lambda → Transcribe と言う流れで、実装します!
Lambda は全然詳しくないため、間違いや不適切な表現等ございましたら、優しめのマサカリをよろしくお願いいたします! \(≧∇≦)
S3の設定
まずは、S3 にバケットを作りましょう。
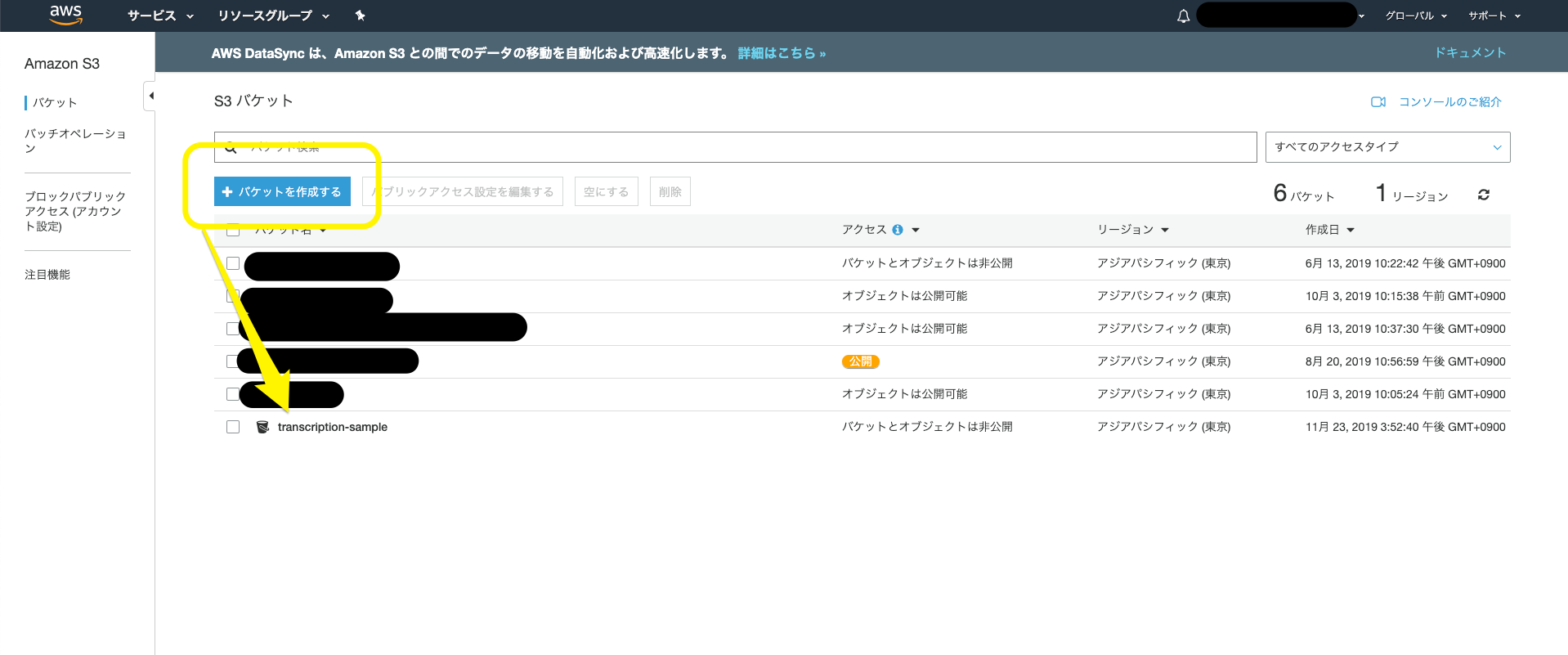
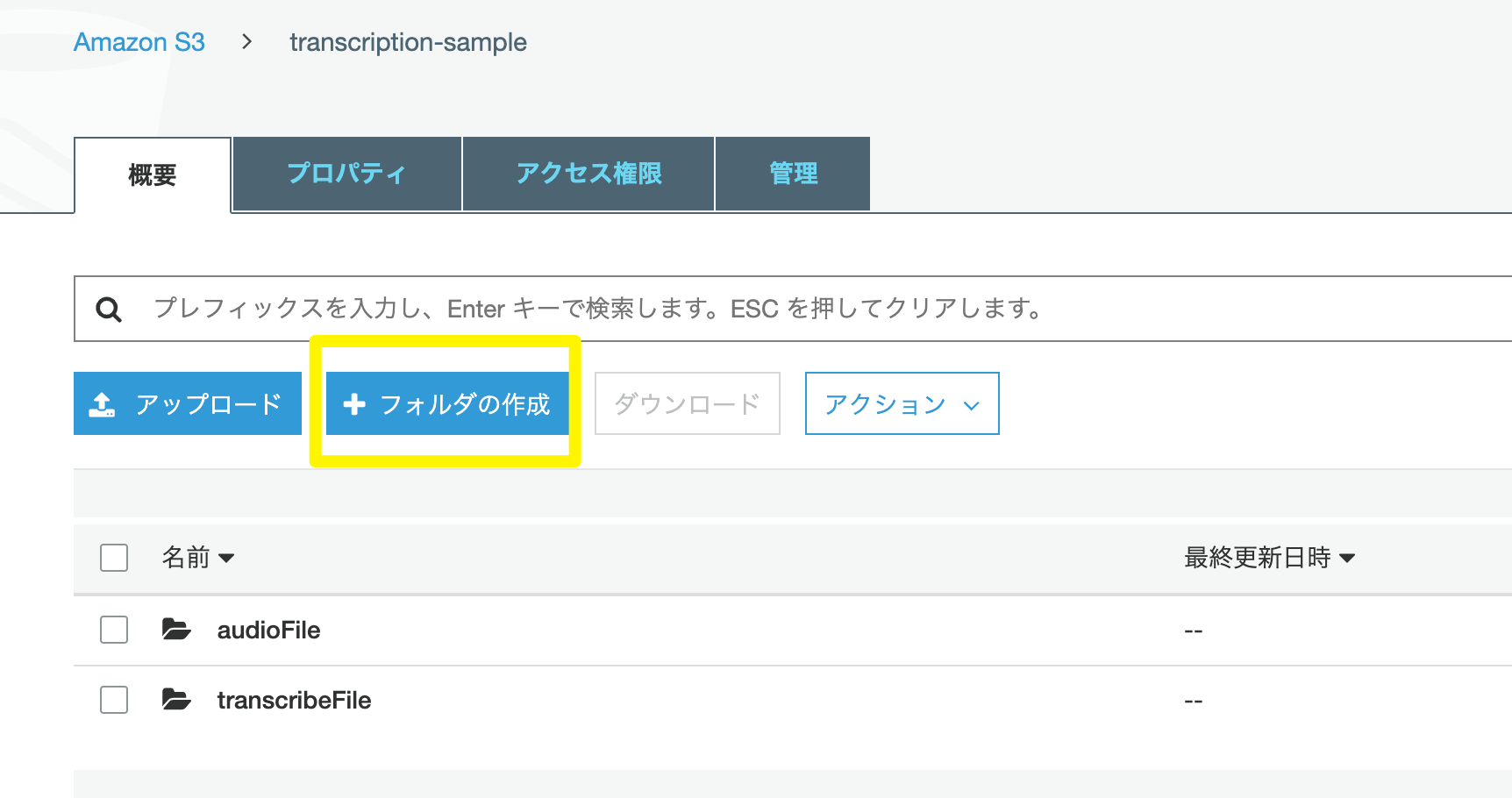
バケットを作ったら、フォルダの作成をクリックし、下記のように、二つからのフォルダを作ります。
IAM ロールの設定
続いて、Lambda に設定する、IAM ロールを作ります。
必要なロールは、AWS Transcribe にアクセスするロールと、cloudWatch Logsに書き込むロールとなります。
サービスで IAM を検索 → 左サイドバーのロールをクリック → ロールの作成をしてください。
下記の画面になり、Lambdaをクリックし、次のステップに進みます。

検索窓から、AWSLambdaExecute と、AmazonTranscribeFullAccess を選択し、ロールの設定は完成です。
Lambda 準備編
続いて、Lambda へ移ります。
Lambda → 関数の作成 → 1から作成 を選択します。
任意の名前をつけ、ロールには、既存のロールを使用するを選択し、先ほど作ったロールを適応します。
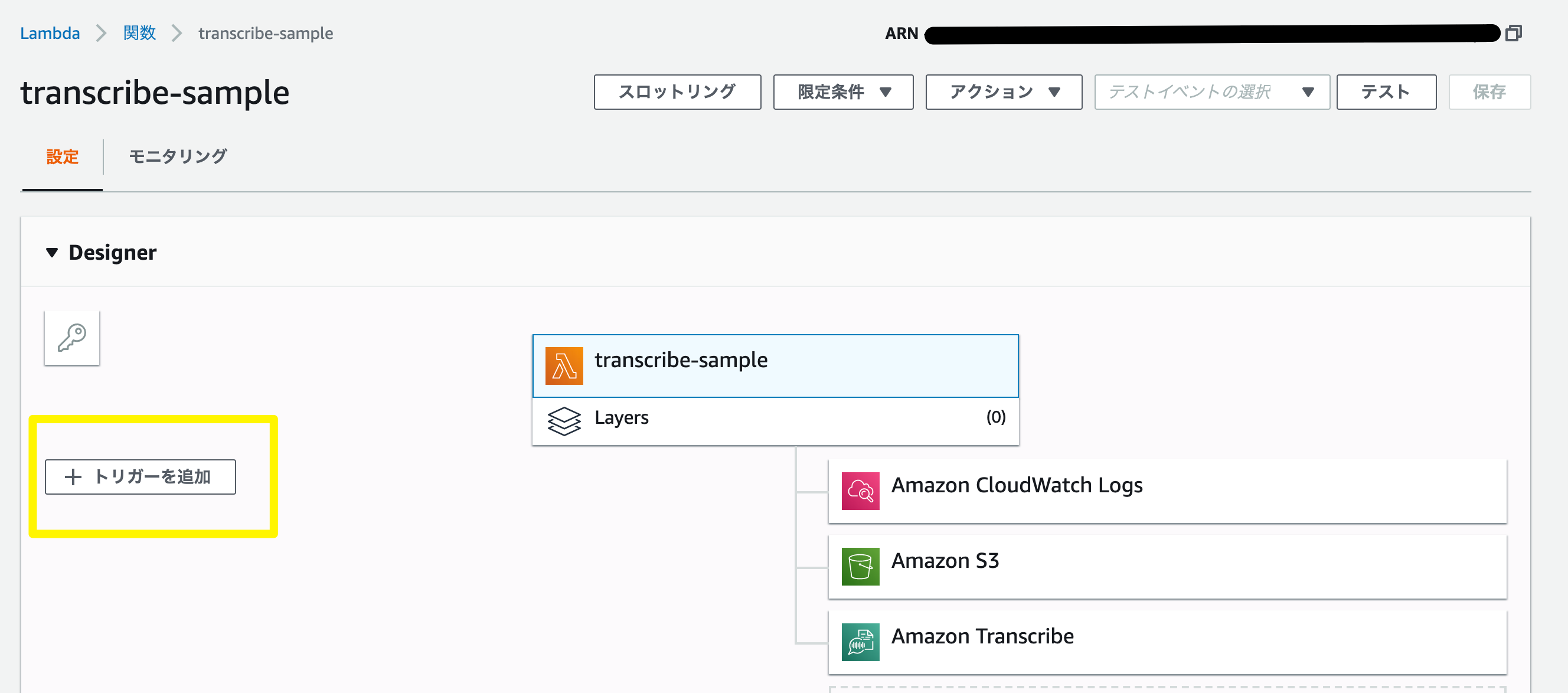
関数が作成されましたら、下記の画面になりますので、左のトリガーを追加をクリックし、S3 を選択し、下記のように設定します。

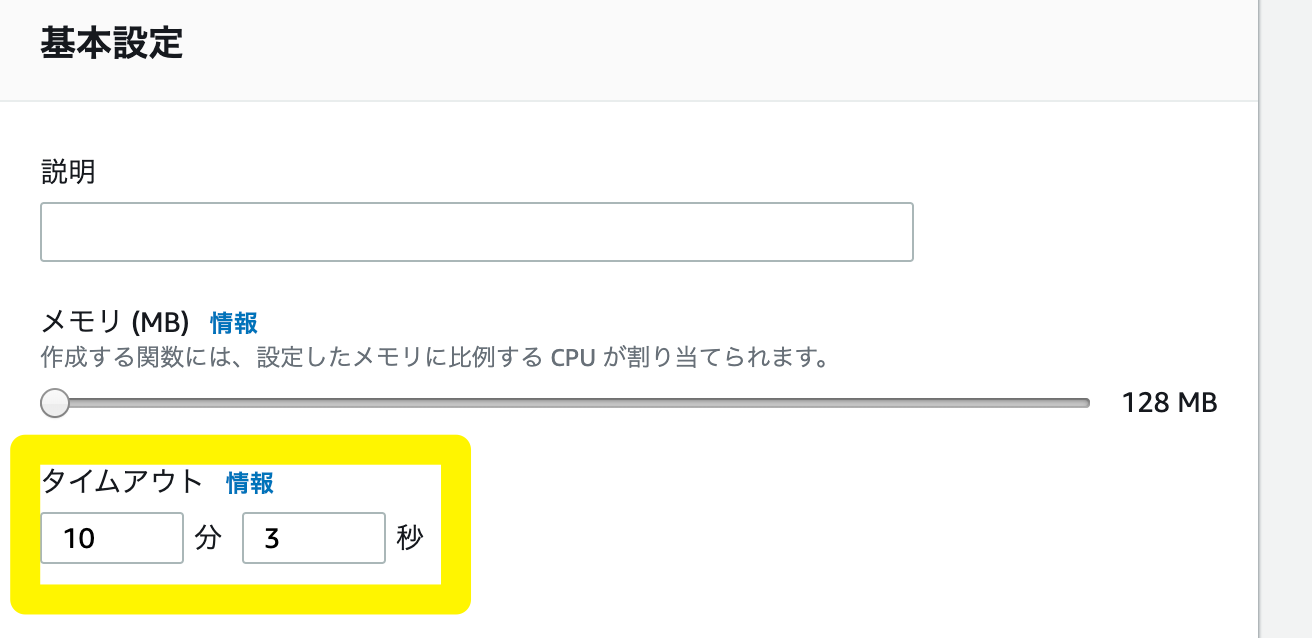
最後に、画面を下にスクロールし、基本設定の、タイムアウトを長めに設定します。
これで、準備は整いました。
これから、コードの実装をしていきます。
Lambda 実装編
Lambda を初めて触る方もおられると思いますので、少し解説をします。
熟練者のかたは、この辺りは読み飛ばしてくださいませ。。
S3 にアップロードした後、通知メッセージが JSON 形式で送信されます。
このメッセージは、Lambda に、event という形で、伝達されます。
exports.handler = async (event, context) => {
};
今回、S3 のバケットにアップロードする場合、PUTリクエストを行っていることになります。
より正確な表現をすると、Amazon S3 が s3:ObjectCreated:Put イベントを発行することになります。
こちらによると、PUTリクエストにより、Lambda へ渡される event は、以下になります。
{
"Records":[
{
"eventVersion":"2.1",
"eventSource":"aws:s3",
"awsRegion":"us-west-2",
"eventTime":"1970-01-01T00:00:00.000Z",
"eventName":"ObjectCreated:Put",
"userIdentity":{
"principalId":"AIDAJDPLRKLG7UEXAMPLE"
},
"requestParameters":{
"sourceIPAddress":"127.0.0.1"
},
"responseElements":{
"x-amz-request-id":"C3D13FE58DE4C810",
"x-amz-id-2":"FMyUVURIY8/IgAtTv8xRjskZQpcIZ9KG4V5Wp6S7S/JRWeUWerMUE5JgHvANOjpD"
},
"s3":{
"s3SchemaVersion":"1.0",
"configurationId":"testConfigRule",
"bucket":{
"name":"mybucket",
"ownerIdentity":{
"principalId":"A3NL1KOZZKExample"
},
"arn":"arn:aws:s3:::mybucket"
},
"object":{
"key":"HappyFace.jpg",
"size":1024,
"eTag":"d41d8cd98f00b204e9800998ecf8427e",
"versionId":"096fKKXTRTtl3on89fVO.nfljtsv6qko",
"sequencer":"0055AED6DCD90281E5"
}
}
}
]
}
ごちゃごちゃしてますが、大事なところは、以下のようになります。
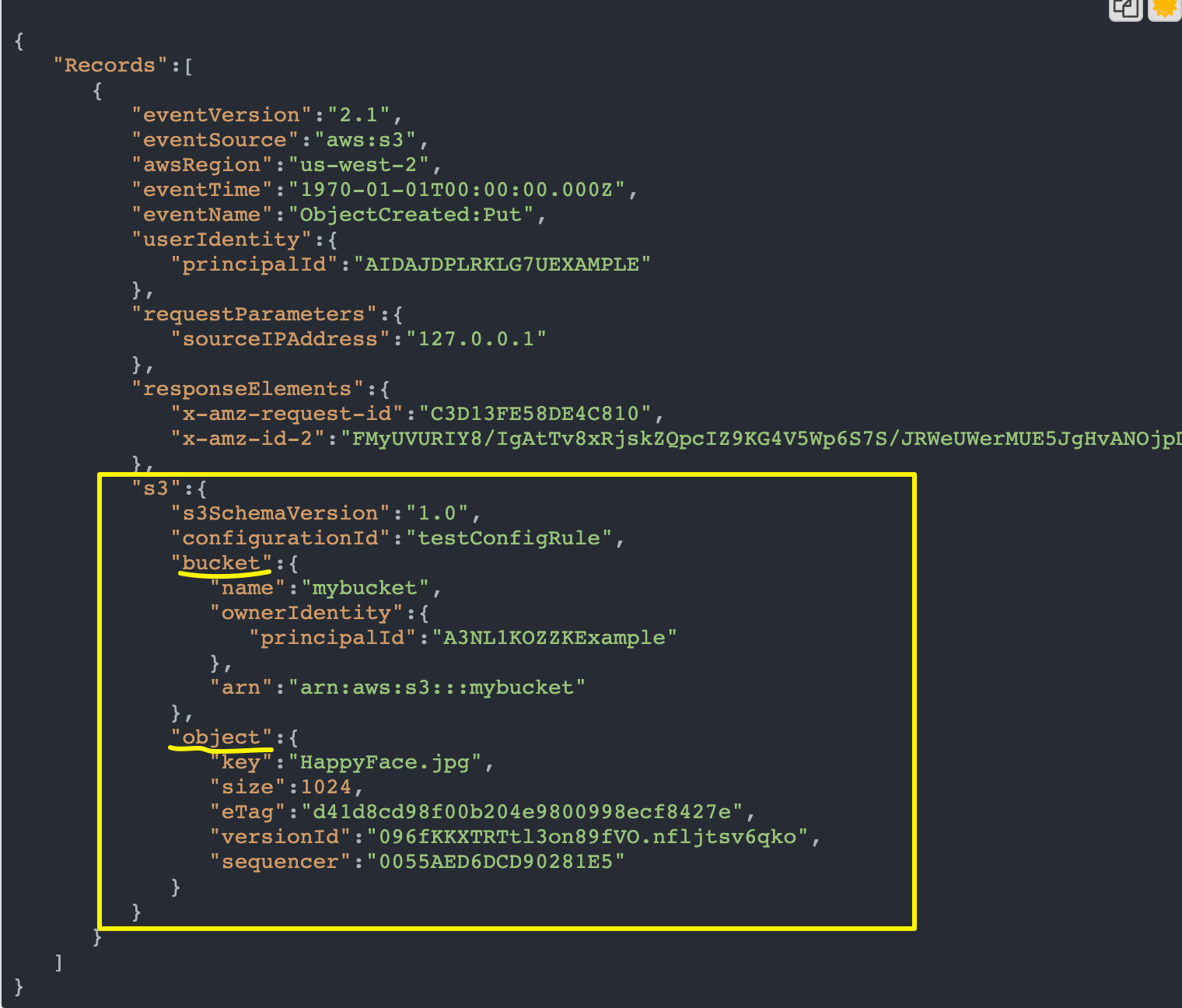
つまり、
・bucket名 → event.Records[0].s3.bucket.name
・ObjectKey → event.Records[0].s3.object.key
となります。
オブジェクトのファイルのパスは、今までなら、s3://バケット名/ObjectKey で良かったのですが、自分の場合
An error occurred (BadRequestException) when calling the StartTranscriptionJob operation: The S3 URI that you provided can't be accessed. Make sure that you have read permission and try your request again.
と言うエラーログが出てしまい、こちら を参考にして修正しました。
FilePath → "https://s3-ap-northeast-1.amazonaws.com/" + bucket名 + '/' + ObjKey
これで動きました。
しかし、こちらの記事によると、2020年9月30日以降、この形式で S3 API リクエストしても受け付けられなくなるとのことで、有識者の方、適切な書き方を教えてください・・・
では、早速、Lambda を書いていきましょう。
exports.handler = async (event, context) => {
const Bucket = event.Records[0].s3.bucket.name
const ObjKey = event.Records[0].s3.object.key
const FilePath = "https://s3-ap-northeast-1.amazonaws.com/" + Bucket + '/' + ObjKey
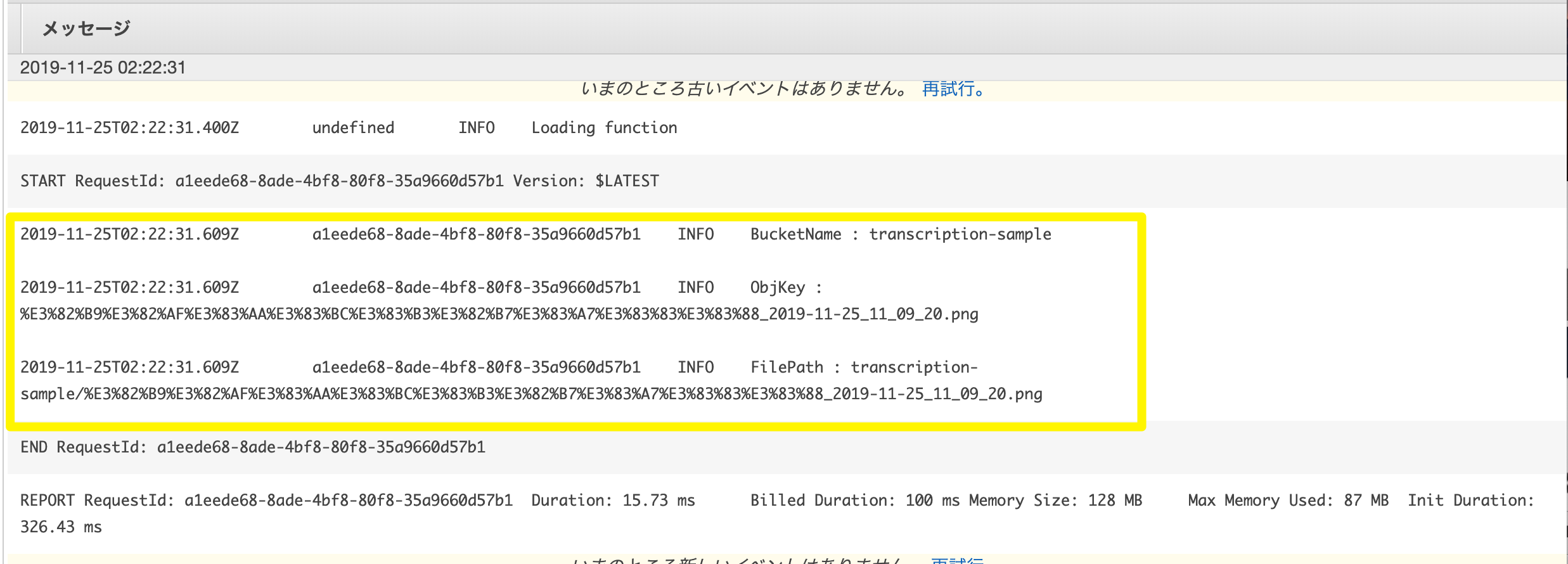
console.log('BucketName : ' + Bucket);
console.log('ObjKey : ' + ObjKey);
console.log('FilePath : ' + FilePath);
};
これで、S3 にアップロードして、ログを吐く実装ができました。
では、早速S3 にアップロードして、cloudWatch にlog が飛んでいるかを試してみましょう!
S3 アップロード → CloudWatch Logs でのログ確認
S3に戻り、最初の作成したバケットのフォルダへ、任意のファイルをアップロードします。
次に、Lambda へ戻り、上部のモニタリングタブをクリックし、CloudWatch の ログを表示をクリックします。

下記のように、無事、ログが飛んでいるのを確認できました。

では、続いて、Amazon Transcribe と連携していきます。
Amazon Transcribe 連携
Amazon Transcribe が起動するには、StartTranscriptionJob API が必要になります。
公式DOC によると、以下のように書きます。
const AWS = require('aws-sdk');
const transcribeservice = new AWS.TranscribeService({apiVersion: '2017-10-26'});
const params = {
LanguageCode: ja-JP /* required */
Media: { /* required */
MediaFileUri: 'STRING_VALUE'
},
TranscriptionJobName: 'STRING_VALUE', /* required */
MediaFormat: mp3 | mp4 | wav | flac,
OutputBucketName: 'STRING_VALUE',
};
transcribeservice.startTranscriptionJob(params, function(err, data) {
if (err) console.log(err, err.stack); // an error occurred
else console.log(data); // successful response
});
MediaFileUri は、S3へアップロードしたファイルのURI を入力します。
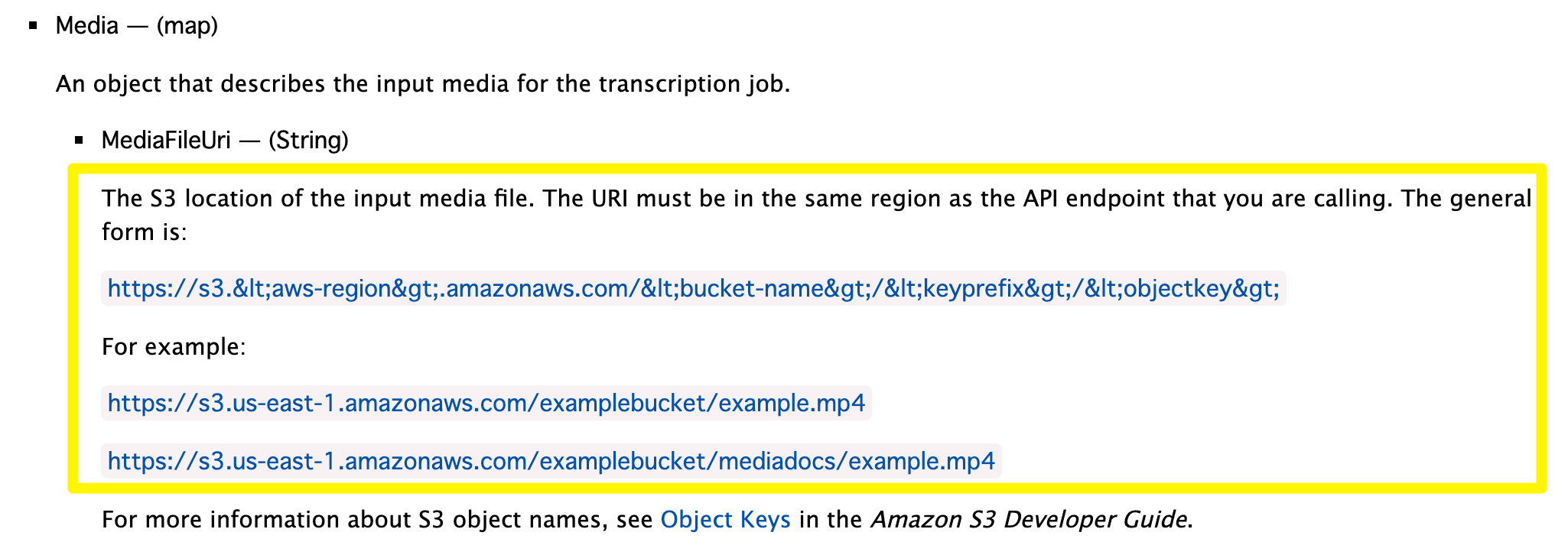
URI は、Amazon Transcribe と同一リージョンであることが必須のため、注意しましょう。
TranscriptionJobName は、AWS Transcribe のjob 名です。
S3 からevent と context (呼び出し、実行関数、関数に関する情報を提供する役割を持つ) が渡ってくるのですが、こちらを使います。
awsRequestId を使って、呼び出しリクエストのIDを、TranscriptionJobName に渡しましょう。
最終的に、以下のコードになります!
const AWS = require('aws-sdk');
const transcribeservice = new AWS.TranscribeService({apiVersion: '2017-10-26'});
exports.handler = async (event, context) => {
const Bucket = event.Records[0].s3.bucket.name
const ObjKey = event.Records[0].s3.object.key
const FilePath = "https://s3-ap-northeast-1.amazonaws.com/" + Bucket + '/' + ObjKey
const FileType = ObjKey.split(".")[1]
const jobName = context.awsRequestId
console.log('BucketName : ' + Bucket);
console.log('ObjKey : ' + ObjKey);
console.log('FilePath : ' + FilePath);
console.log(FileType)
const params = {
LanguageCode: "ja-JP",
Media: {
MediaFileUri: FilePath
},
TranscriptionJobName: jobName,
MediaFormat: FileType,
};
try{
const response = await transcribeservice.startTranscriptionJob(params).promise()
console.log(response)
return response
}catch(error){
console.log(error)
}
};
注意点として、
await の文章の最後に、promise() とつけるのを忘れないでください。
私は、このトラップで5時間無駄にしました・・・
参考文献:
AWS LambdaがNode.js8.10をサポートしたのでasync/awaitを試してみた
さあ、これで完成です!
S3 に mp3 か、mp4 ファイルを upload して、Transcribe が正常動作するか、確認しましょう!
AWS Transcribe
S3 に mp3 もしくは、mp4ファイルを アップロードし、Amazon Transcribe の画面にいきましょう。
すると・・・

ご覧のように、 In Progress のStatus を持つ、新たな文字起こしJob が出現しました。
気になる日本語の精度はというと、 (あくまで自分のサンプルの限りですが)

び、微妙すぎる・・・・
わからなくもないが、まだまだな印象があります。
今後の精度up に乞うご期待ですね・・・!
まとめ
ここまで、お疲れ様でした。今回
S3 → Lambda → Transcribe
という実装を行いました。
次回は、Job が完了したら、それをLambdaに伝え、S3 ファイルにupload するという実装を行いたいと思います。それでは、また〜