はじめに
(Autoregressiveな)自然言語モデルによるテキスト生成は、文章の前(左)にある単語から次の単語を予測していくことで行われるのが通常だと思いますが、逆に文章の後ろ(右)の単語から前の単語を予測していく言語モデルを学習させ、文末を指定したツイート生成bot的なものを作ってみようというのがこの記事の趣旨です。
方法
方法は単純で、入力テキストの順番を逆転させるだけです。例えば、
おはようございます
を
すまいざごうよはお
に変換します。
これを学習させる全てのテキストに適用して、モデルに学習させます。
訓練データ
今回はおよそ4万件のツイートを収拾し、これを学習データとして使用しました。
コード
今回使用したコードは以下の通りです。
まずは学習テキストを逆転させます。
import pandas as pd
# 使用するCSVファイル
path = "./tweet.csv"
texts = pd.read_csv(path)['tweet'].to_list()
data = []
for t in texts:
#順序を逆転
reversed_text = ''.join(list(reversed(str(t))))
data.append(reversed_text)
# CSVファイルとして保存
df = pd.DataFrame(data, columns=['text'], dtype=str)
df.to_csv('reversed_data.csv', index=False)
次にトークナイザですが、sentencepieceを使用します。
まずは上記のコードで作成したCSVファイルをsentencepieceに学習させます。
import sentencepiece as spm
spm.SentencePieceTrainer.train('--input=./reversed_data.csv \
--model_prefix=rev \
--vocab_size=10000 \
--character_coverage=0.995 \
--user_defined_symbols=<pad>,<eos>')
学習データの準備に移ります。
まずはテキストの最大長の計算。
def tokenizer(text):
return sp.EncodeAsPieces(text)
def calc_max_len(src):
dst = [tokenizer(s) for s in src]
return max(len(d) for d in dst)
sp = spm.SentencePieceProcessor('./rev.model')
max_seq_len = calc_max_len(data) + 1
次にeosトークンとパディングトークンの追加。
from tqdm.auto import tqdm
def encode_tokens(text):
return sp.Encode(text)
def add_eos_and_pad(data, max_seq_len, eos, pad):
output = []
for d in tqdm(data):
d = tokenizer(d)
#eosトークンを追加
d.append(eos)
#パディング
for i in range(len(d), max_seq_len):
d.append(pad)
d = ''.join(d)
output.append(encode_tokens(d))
return output
pad = '<pad>'
eos = '<eos>'
data = add_eos_and_pad(data, max_seq_len, eos, pad)
次に学習データを訓練データと検証データに分けます。
from sklearn.model_selection import train_test_split
text_train, text_test = train_test_split(data,
test_size=0.2,
random_state=42)
それぞれのデータに対してデータローダーを作成。
バッチサイズは32としました。
import torch
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):
def __init__(self, dataset):
self.dataset = dataset
def __getitem__(self, idx):
return self.dataset[idx]
def __len__(self):
return len(self.dataset)
def to_tensor(data):
output = []
for seq in tqdm(data):
seq_tensor = torch.tensor(seq).long()
output.append(seq_tensor)
return torch.stack(output)
def make_dataloader(data, batch_size, shuffle=True):
data_tensor = to_tensor(data)
dataset = MyDataset(data_tensor)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=shuffle)
return data_loader
batch_size = 32
train_data = make_dataloader(text_train, batch_size, True)
test_data = make_dataloader(text_test, batch_size, False)
次にモデル定義ですが、今回はPerformer(Transformerの一種)を使用しました。
オプティマイザはAdamを選択。
from performer_pytorch import PerformerLM, AutoregressiveWrapper
num_tokens = len(sp)
dim = 512
depth = 4
heads = 8
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = PerformerLM(
num_tokens = num_tokens,
max_seq_len = max_seq_len,
dim = dim,
depth = depth,
heads = heads,
causal = True,
reversible = True,
use_scalenorm = True
).to(device)
model = AutoregressiveWrapper(model)
lr = 1e-4
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
準備ができたので訓練を開始します。20エポックの訓練としました。
import os
import time
# チェックポイントの保存
def save_model(path, model, optimizer, train_loss, val_loss):
torch.save({
"model_state_dict" : model.state_dict(),
"optim_state_dict" : optimizer.state_dict(),
"train_loss" : train_loss,
"val_loss" : val_loss
}, path)
# モデルの評価
def eval_model(model, data_loader, batch_size):
model.eval()
val = 0
num_batches = len(data_loader.dataset) // batch_size + 1
with torch.no_grad():
for _, data in enumerate(tqdm(data_loader)):
data = data.to(device)
loss = model(data, return_loss=True)
val += loss.item()
val /= num_batches
return val
# チェックポイントの保存ディレクトリ
output_dir = 'checkpoint'
os.makedirs(output_dir, exist_ok=True)
num_batches = len(train_data.dataset) // batch_size + 1
# エポック数
num_epochs = 20
# ロスの保存
train_loss = []
val_loss = []
# 訓練開始
start = time.time()
print('now training')
for epoch in range(num_epochs):
model.train()
print(f'EPOCH {epoch + 1}/{num_epochs}')
epoch_loss = 0
for _, data in enumerate(tqdm(train_data)):
data = data.to(device)
loss = model(data, return_loss=True)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_loss /= num_batches
train_loss.append(epoch_loss)
print('validating')
val = eval_model(model, test_data, batch_size)
val_loss.append(val)
end = time.time() - start
print(f'TRAIN LOSS {epoch_loss} : VAL LOSS {val} : TIME {end}')
file_name = f'checkpoint_epoch{epoch + 1}.pt'
save_model(os.path.join(output_dir, file_name),
model, optimizer, train_loss, val_loss)
print('done')
結果
各エポックのロスは以下のようになりました。
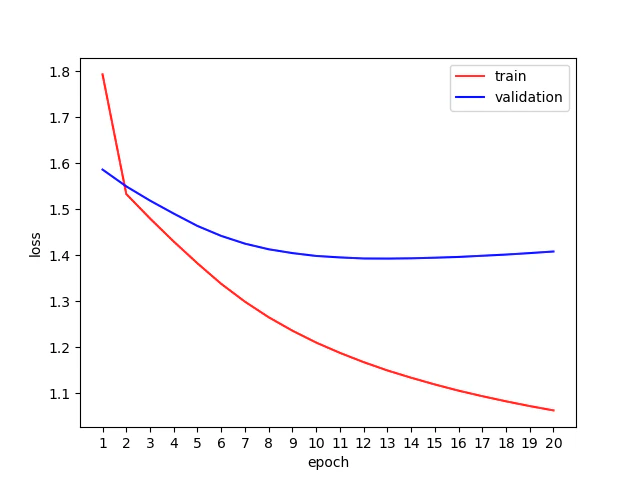
ツイート生成
検証データのロスが最も小さかったエポック13を採用しました。
p = 13
path = f'./checkpoint/checkpoint_epoch{p}.pt'
checkpoint = torch.load(path, map_location=torch.device('cpu'))
model.load_state_dict(checkpoint['model_state_dict'])
文章生成のためのコードは以下の通り。
sp = spm.SentencePieceProcessor('./rev.model')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
eos = '<eos>'
eos_token = sp.Encode(eos)[-1]
def encode_tokens(text):
return sp.Encode(text)
def decode_tokens(tokens):
return sp.Decode(tokens)
def generate_text(input, model, seq_len=140, temperature=1.0, eos_token=eos_token):
reversed_input = ''.join(list(reversed(str(input))))
input_tokens = encode_tokens(reversed_input)
start_tokens = torch.tensor(input_tokens).long().to(device)
generated_tokens = model.generate(start_tokens, seq_len, eos_token, temperature).tolist()
reversed_tokens = [t for t in generated_tokens if t != eos_token]
reversed_output = decode_tokens(reversed_tokens)
output = ''.join(list(reversed(reversed_output)))
return output + input
# 指定する文末
input = 'だと思う'
temperature = 0.9
t = generate_text(input, model, temperature=temperature)
print(t)
というわけで文末を指定したツイートを生成させてみました。
文末:てワロタ
全てがどうでもよくてワロタ
地味にバグ極めててワロタ
叩かれててワロタ
炭治郎がデブ犬のコメントでわかりやすくてワロタ
流石にダサくてワロタ
主張激しくてワロタ
文末:でしょ
突然の天気がもうごめん。モーション怖すぎでしょ
ただ、妻ツートップなら勝つんだ?クラス声かけるの?上手すぎて草僕の性格はゼロでしょ
あなたに流れてきて迷ったメッセージボードスが馬鹿なのバグでしょ
粘着力でしょ
いつもlog パソコンは強すぎだろwww決めたけど、天才だよこんなもんでしょ
たぶん、そのツイートのもあきらか誠実だ!ってガチャの駄目じゃないレベルでしょ
文末:だよな
大やることがとこもその君!...駅からねぇ......!! 1人うーん最高だよな
顔を見て告白されたのだよな
怪しすぎるんだよな
頭されてたのお姉さんは吹き出した神曲が良すぎるんだよな
地獄すぎるんだよな
【悲報】今週の続きはリプ欄から使われてるんだよな
文末:すぎる
バイトの解体、限界すぎる
それイカれてんのは異次元すぎる
素敵な一年飯テロすぎる
声が性癖すぎる
光属性の闇深すぎる
悲鳴らして飲みながらお金払っておきて、納豆知識は地獄すぎる
・・・・。