比較対象
- Pythonのreモジュール
python --version
Python 3.10.14
- Rustのregexモジュール
rustc --version
rustc 1.75.0 (82e1608df 2023-12-21) (built from a source tarball)
今回は特に並列化せずに比較を行う。
タスク
- リスト内に含まれる各単語が、英語か日本語かを正規表現で判断
- 結果をBooleanのリストとして返す
ベンチマークデータセット
下記のようなデータを用意した。
はい you're welcome おはよう はい いいえ
you're welcome hello good night すみません いいえ
hello はい ありがとう please どういたしまして
ありがとう excuse me さようなら いいえ さようなら
すみません good night yes おやすみ good night
上記データは下記コードにより適当に生成した。
import random
# 日本語と英語の単語リスト
japanese_words = ["こんにちは", "ありがとう", "さようなら", "おはよう", "おやすみ", "すみません", "はい", "いいえ", "お願いします", "どういたしまして"]
english_words = ["hello", "thank you", "goodbye", "good morning", "good night", "excuse me", "yes", "no", "please", "you're welcome"]
# 文を生成する関数
def generate_mixed_sentence():
sentence = []
for _ in range(5): # 各文に5つの単語を含める
if random.choice([True, False]):
sentence.append(random.choice(japanese_words))
else:
sentence.append(random.choice(english_words))
return " ".join(sentence)
# 1万件の文を生成
mixed_sentences = [generate_mixed_sentence() for _ in range(10000)]
with open('test_cases.txt', 'w') as f:
for sentence in mixed_sentences:
f.write(sentence + '\n')
実験詳細
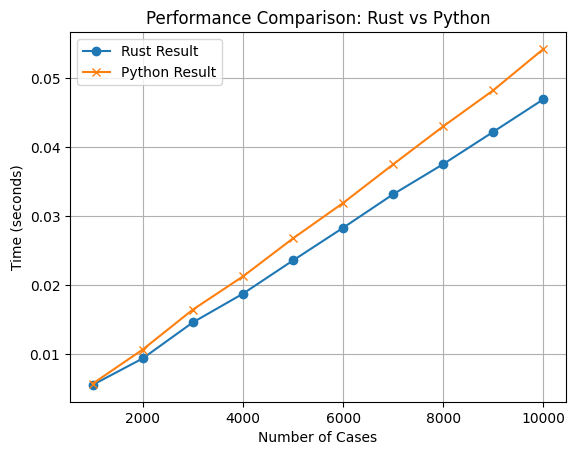
上記ベンチマークデータセットについて、使用する割合を1割ずつ変化させていき、速度の変化を図にまとめる。
使用するコード
import re
import time
def is_alphabetic(word):
return bool(re.match(r"^[a-zA-Z0-9]+$", word))
def read_test_cases(file_path):
with open(file_path, 'r') as f:
lines = f.readlines()
test_cases = []
for line in lines:
words = line.strip().split()
test_cases.append(words)
return test_cases
def test_alphabetic(test_cases):
start_time = time.time()
results = []
for case in test_cases:
for word in case:
results.append(is_alphabetic(word))
end_time = time.time()
return end_time - start_time
def main():
test_cases = read_test_cases('test_cases.txt')
total_cases = len(test_cases)
for i in range(1, 11):
subset_size = int(total_cases * (i / 10))
subset = test_cases[:subset_size]
elapsed_time = test_alphabetic(subset)
print(f"Processed {subset_size} cases in {elapsed_time:.5f} seconds")
if __name__ == "__main__":
main()
use regex::Regex;
use std::fs;
use std::time::Instant;
use once_cell::sync::Lazy;
static RE: Lazy<Regex> = Lazy::new(|| Regex::new(r"(?-u)^[a-zA-Z0-9]+$").unwrap());
fn is_alphabetic(word: &str) -> bool {
RE.is_match(word)
}
fn read_test_cases(file_path: &str) -> Vec<Vec<String>> {
let contents = fs::read_to_string(file_path).expect("Failed to read file");
let mut test_cases = Vec::new();
for line in contents.lines() {
let words: Vec<String> = line.split_whitespace().map(|s| s.to_string()).collect();
test_cases.push(words);
}
test_cases
}
fn test_alphabetic(test_cases: &[Vec<String>]) -> (f64, Vec<bool>) {
let start = Instant::now();
let mut results = Vec::new();
for case in test_cases {
for word in case {
results.push(is_alphabetic(word));
}
}
let elapsed_time = start.elapsed().as_secs_f64();
(elapsed_time, results)
}
fn main() {
let test_cases = read_test_cases("../test_cases.txt");
let total_cases = test_cases.len();
for i in 1..=10 {
let subset_size = (total_cases as f64 * (i as f64 / 10.0)).ceil() as usize;
let subset: Vec<Vec<String>> = test_cases.iter().take(subset_size).cloned().collect();
let (elapsed_time, _results) = test_alphabetic(&subset);
println!("Processed {} cases in {:.5} seconds", subset_size, elapsed_time);
}
}
結果
あまり変わらない。