1.はじめに
UnitV2で任意の画像認識をさせたいのですが、「Online Classifier」では任意の物体の学習はできるものの、認識範囲がカメラ中央固定なのが不都合でした。
M5Stackより提供されている「V-Training」というサービスを使うと、任意の画像学習をさせて、「Object Recognition」で学習させたAIモデルを使用できるようになります。
Object Recognitionを使うと任意の場所の物体認識が可能になるので、こちらのトレーニングサービスを使ってみたいと思います。
トレーニングサービスのチュートリアルはこちら
2.準備
・学習させたい画像ファイル(できるだけ多く)
・M5Stack Communityアカウント
→V-Trainingのログイン時に必要
→新規アカウント登録時は管理者承認までしばし待つ必要あり(自動発行ではない模様)
→夜に登録したら翌朝10時過ぎに登録承認メールが届きました
3.学習
3-1.V-Trainingにログインして「Start」押下

3-2.学習画像のアップロード
 画像をDrag&Dropか、AddImagesで追加。アップが完了したら「Next」押下
画像をDrag&Dropか、AddImagesで追加。アップが完了したら「Next」押下

3-3.Annotate
「Next」を押下するとProject Typeとして「Object Recognition」が選択されます(2021/10/09時点では他に選択肢はない模様)

「Annotate」は学習画像上の学習させたい物体の領域とラベル付けをする作業です。
※ここら辺で今回の私の作業テーマが薄々見えてきたかと思いますが、めざましじゃんけんのAI画像認識をさせたいと考えていて、ラベルは「gu」「choki」「pa」の3つを設定しています
ラベルの追加は左上の「+」ボタンを押下
ラベルが設定できたら「Start project」を押下

学習させたい物体の領域設定(bounding box)をし、右上でラベルを設定します。(今回はlabel:choki)

これをアップロードした学習画像分全て実施します(この作業が結構大変)
途中2人のパターンがでてきたので、両方Annotationしておきます。

このAnnotate作業には「AI自動マーキング機能」という機能もV-Trainingにはあるそうです。
今回は一旦手動作業で進めてみます。
3-4.モデルトレーニング
Annotate作業が完了したら、「Next」押下でモデルトレーニング作業が始まります
Modeが選択できますが、2021/10/09時点では「Efficient Mode」しか選べないので、「UPLOAD!」ボタン押下で処理を進めます。
「Okay」押下
トレーニング処理が始まった直後にFaildになってしまいました。
「Detail」リンクでエラー原因を見てみましょう。

アップロードした画像が少なすぎるそうです。(30枚以上必要なようです)
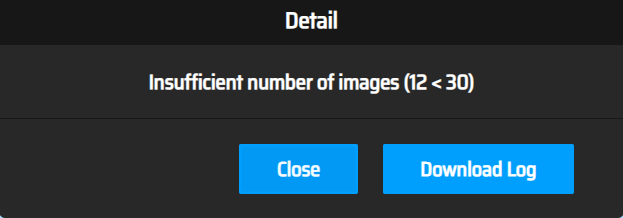
20枚追加(計32枚)してトレーニングを開始

「Refresh」押下で処理状況を更新
枚数が少なかったのであっという間に学習完了

「View Loss」リンクで学習曲線が確認できます

100epoch学習してくれているようです。
ちょっとみかたがわからないのですが、なぜdfl loss、qfl lossの組み合わせが2つあるのか。。。?
dfl、qflとは何なのか?
タイトルがlossなので、損失関数のグラフなのでしょう。
勾配の特性から青:dflが訓練時、緑:qflがテスト時のグラフと推測されます。
損失関数は正解とのずれであり、小さければ小さいほど良いので、学習が進む(Epochカウントが大きい方)につれ、学習が進んでいることがわかります。
縦軸の値がわからないのがイマイチですが、訓練と学習で同じような下がり方なので、このグラフを見る限りでは過学習にはなっていないようにも思われます。
4.カスタムモデルの動作確認
学習させたカスタムモデルをUnitV2に反映したいと思います。
「Download」リンクよりモデルをダウンロードできます。
今回は3.6Mのファイルでした。

UnitV2を起動して「Object Recognition」を開きます
「add」ボタンを押下し、新規モデルのアップロード枠を作成して、作成したカスタムモデルをアップロードします。

アップロードが完了したら「run」で実行します。
さぁ、めざましじゃんけんスタート!

ということで、45%ながらも、chokiで認識させることができました!
が、実際は録画動画で試してみると、UnitV2の処理速度に対してじゃんけんがでて終わるのが速すぎるのであまりうまく認識できませんでした。
ので、一時停止して認識させたのが上記です。
元々これは訓練画像にも入れているのでほぼ正解を知っている状況になるわけで、逆に言えばその割には確度が低い(自信がない)とも言えます。
あと、じゃんけん終わりに「バイバーイ!」の手が一瞬「pa」で判定されちゃいました。
うん、間違ってない、、、。間違ってないけど。。。!
5.終わりに
やってみて分かったこと
・V-Trainingで学習させることで、任意の物体を認識させることができる
・動画じゃんけんは物体(手)が表示されて消えるのが速すぎてUnitV2では認識しづらい。
認識させたい物体は10秒ぐらい表示され続けないとUnitV2では荷が重いかもしれない
(よりスペックの良いエッジAI端末ならじゃんけん動画認識もできるかも?)
・背景白に手が白いとUnitV2カメラでは白飛びしたような色味になりやはり物体認識が難しくなる
・UnitV2向けに、認識できる物体数は少なくてもよいので、もっと軽い(認識速度が速い)モデルはないものか探す余地はあるかもしれない
小型でAI処理ができて画像認識処理がプリインストールされていることは強みなので、スペックにあったシチュエーションにうまくハメてあげることが活用のポイントなのかなと思われます。