はじめに
こんにちは!
今日は、ChatGPTの力を借りて、データ分析初心者から「なんちゃってデータサイエンティスト」として独り立ち出来るように、データサイエンティストとしての作業の大枠をご紹介します。
この記事を読むと、データサイエンスでよく使われる機械学習の実務の流れが分かり、読み終わったらすぐに、この記事で身につけたスキルを活かすことが出来ます。
前提
まず前提として、この記事はビジネスの観点から、AI・データサイエンスを使って、それっぽい仕事をこなせるようになることを目的としているため、アカデミックの観点からデータサイエンスを学びたい方には、あまりオススメしません。
また、今回はChatGPTでコードを出力してもらうのですが、その出力されたコードを、ググって読み解ける方を想定しております。本記事で利用しているChatGPTはGPT4。
対象となる読者層(イメージ)
・普段は営業職などで、データサイエンスを仕事で使ってみたい初心者
・「AIをどうにか活用したい」と無茶振りされた会社員
※AI・データサイエンス・機械学習という言葉の定義を、この記事ではだいぶ曖昧に扱っています。予めご了承ください。
そもそも、なんちゃってデータサイエンティストとは?
「なんちゃってデータサイエンティスト」のスキルとは、上司から突然、AI・データサイエンスを使って良い感じにデータ分析・予測してほしいという要求(無茶振り)があったとき、それっぽい対応・説明が出来るスキルセットを想定しています。この記事では、つい昨日までデータサイエンスという言葉しか知らなかった初心者でも、それっぽい仕事をこなせるスキルセットを持つことをゴールとします。
なんちゃってデータサイエンティストが力を発揮する環境では、AIやデータサイエンスについて、あまり知見がない人たちが多いため、そういった環境で力を発揮するには、全くのど素人にも分かりやすい説明が求められます。
したがって、細かいモデルやコードの説明よりも、「この分析は〇〇を検証するためのもの」「データは△△の条件で取得したものを使用」といった、いわゆる「そもそも」の説明・対応が出来るようになれば、「なんちゃってデータサイエンティスト」になれるわけです。
ChatGPTを使うメリットは?
ChatGPTは、機械学習の複雑なコーディングを簡単に、そして速く行うことができる優れたツールです。
しかし、これを最大限に活用するためには、データサイエンスに関する基礎知識が必要になります。
適切な質問を投げかけることで、有益なコードやアドバイスを得ることができるのです。今回は、この便利なChatGPTを最大限活用出来るよう、よりデータサイエンスの解像度が高い指示を出せるようになっていきましょう。
秘伝の手順①:目的を設定しよう
データ分析を始める前に、まずは何を解決したいのか、明確な目的を設定しましょう。目的がなければ、分析は方向性を見失い、時間と労力の無駄につながります。
例えば、「新規顧客」を対象に分析する場合、その定義を明確にすることが重要です。「新規顧客=過去1年間に一度も購入経験がない顧客」といった具体的な条件をあらかじめ設けることで、分析の方向性が誰でも分かるようになります。(「過去1年と1日前に買っていたらそれは新規とは言わないじゃないか!」みたいなことを後出しで言う人が偶にいますが、そういう奴は遠慮なくはっ倒しましょう)
秘伝の手順②:データを集めよう
データ分析の土台となるのが、データ収集です。ここが一番の重要ポイント。良い結果を得るためには、良いデータが不可欠です。
データを集める際には、5W1H
・誰が:信用に足る組織・個人なのか?
・何を:何のデータか?データの定義は?
・いつ:データの期間はどれくらいか?どのくらいの頻度で取ったか?
・どこで:日本で取られたデータか?
・なぜ:どういった目的で取ったデータなのか?
・どのように:オンラインのアンケートで取ったものか?
などなど、このように集めるデータの条件を整理しましょう。
このステップをいかに丁寧にやるかで、その後の作業の工数や精度に大きく影響します。
秘伝の手順③:集めたデータを眺めてみよう
データを収集したら、まずはそのデータをじっくりと観察します。
欠損値や外れ値のチェックはもちろん、グラフを使ってデータを視覚化してみるのも良いでしょう。また、カテゴリカル変数の傾向を見ることも大切です。この段階で、データに含まれるパターンや異常値を把握することができます。
もし何のグラフを使って、データを見ればよいか分からなかったらChatGPTに相談してみましょう。こんな感じで返してくれます。

気になるグラフがあったら、それをChaTGPTにコーディングしてもらえばOK。
ここでのポイントは、私のプロンプトにあるように「PythonのPandasで」という具体的な条件を組み込むと、欲しいデータの出力がされやすくなります。
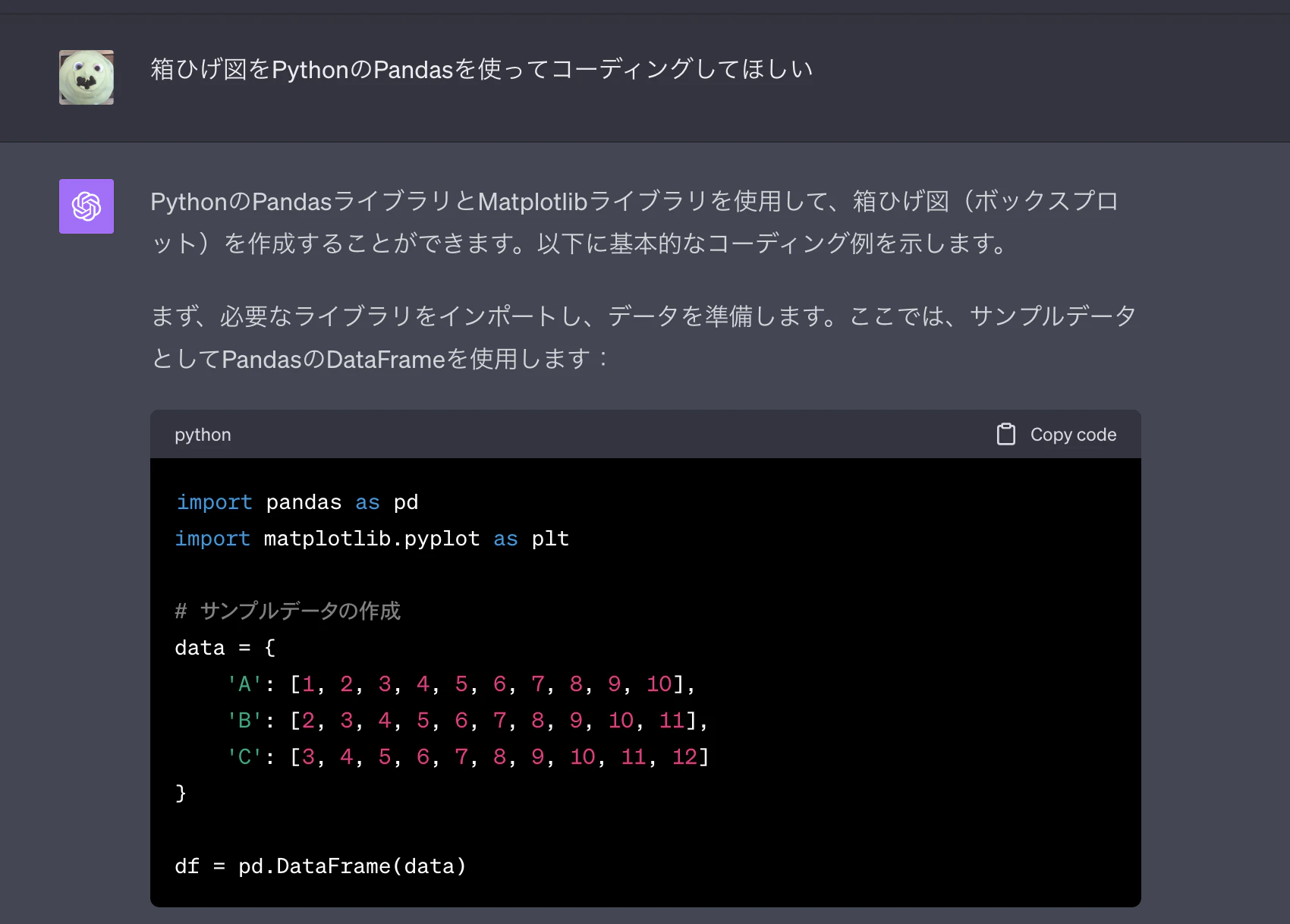
あとは、出力されたコードを自分の環境に合うように修正すれば完璧!
秘伝の手順④:目的変数に関係ありそうな説明変数を整理しよう
目的変数と説明変数の関係を探ります。どの変数が目的変数にどのような影響を与えるのか、相関関係などを見て調べてみましょう。
図のように地道に目的変数や説明変数同士の関連を探るのが、結構大事な作業ポイント
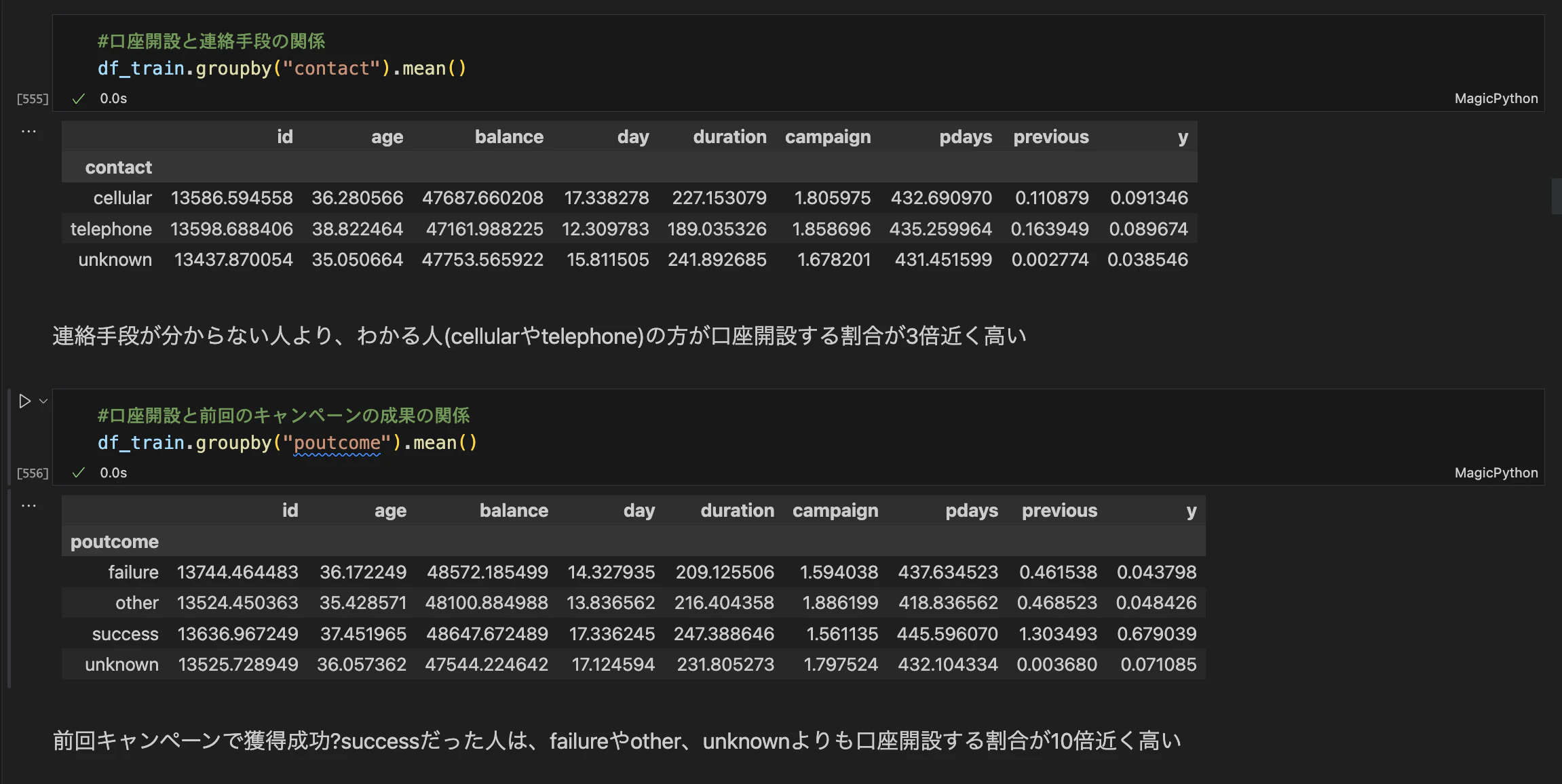
また、ダミー変数を使って目的変数の傾向を探ることも大切ですが、多重共線性には注意が必要です。
多重共線性についての説明はめんどくさいので端折ります。
ちなみに多重共線性への対応方法について、ChatGPTに聞いてみたら、このような回答が返ってきました。
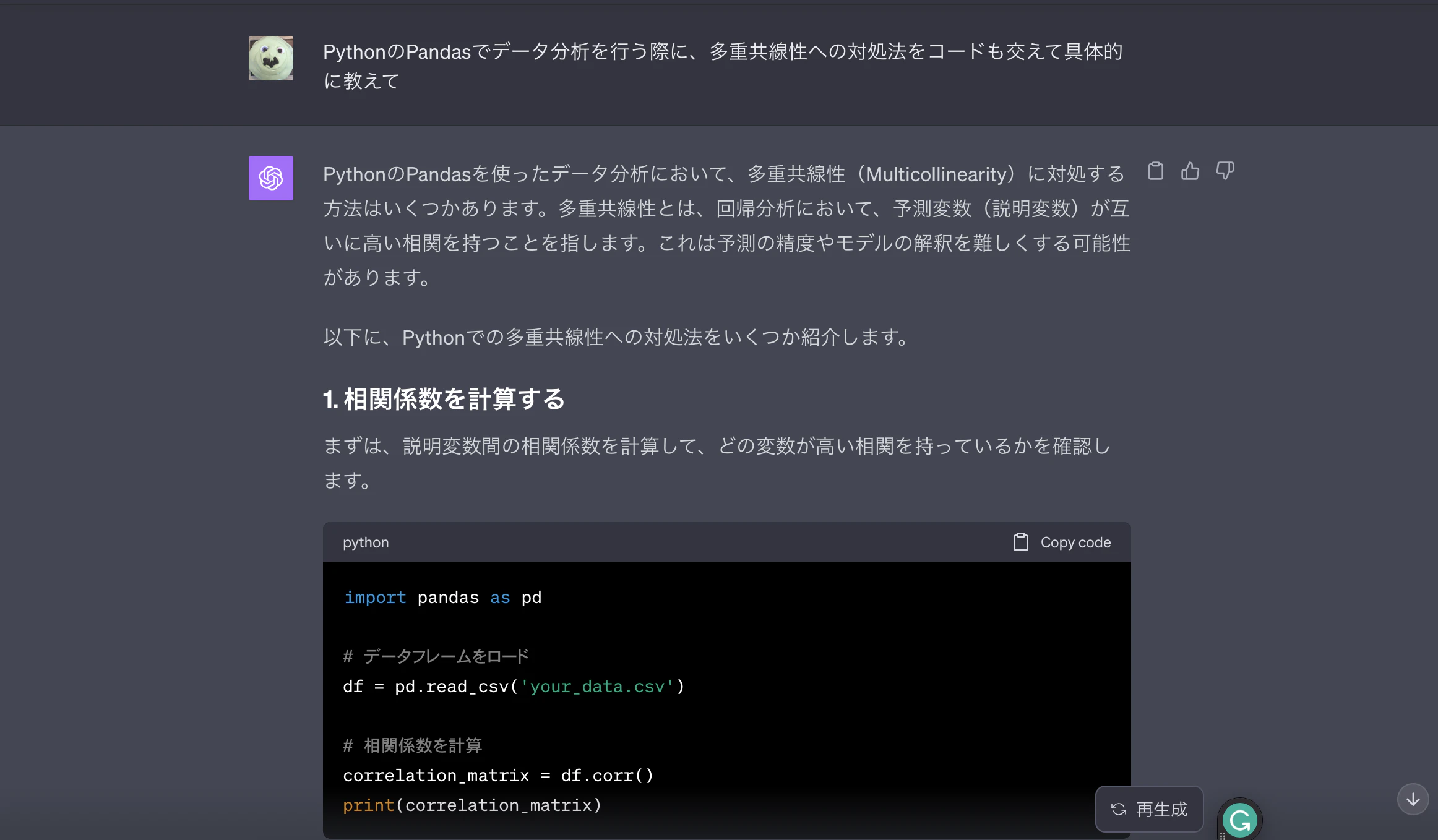
秘伝の手順⑤:特徴量エンジニアリングしよう
特徴量エンジニアリングでは、データ内の重要な変数を見つけ出し、新しい特徴量を作成したり、分析しやすいように、データの標準化などを行ったりします。手順④までの分析で、例えばキャンペーンまでの接触した回数が多ければ多いほど、口座の開設数が多い場合、その特徴量を新たに追加する。
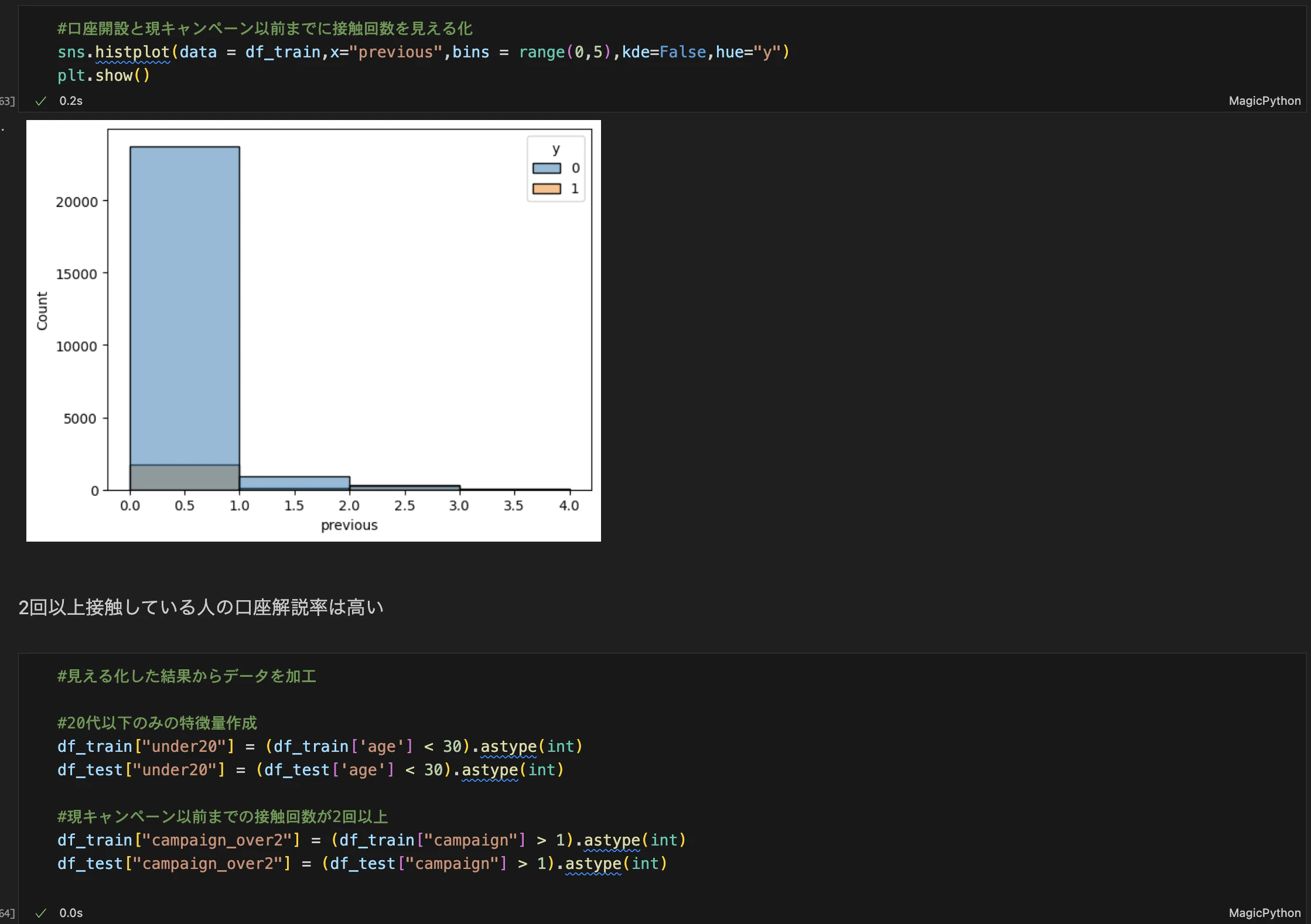
必要に応じてデータの標準化・正規化・対数化を行うことで、機械学習で使うモデルの精度が上がったりするので、そこの調整も大事です。
また、何の特徴量を使えばモデルの予測精度が良くなるか分からない場合、特徴量の選択を丸投げすることも出来ます。これだけで予測の精度がグッと上がることがありますが、デメリットとしては、なぜその特徴量が選ばれたのかが明確に説明出来ない...
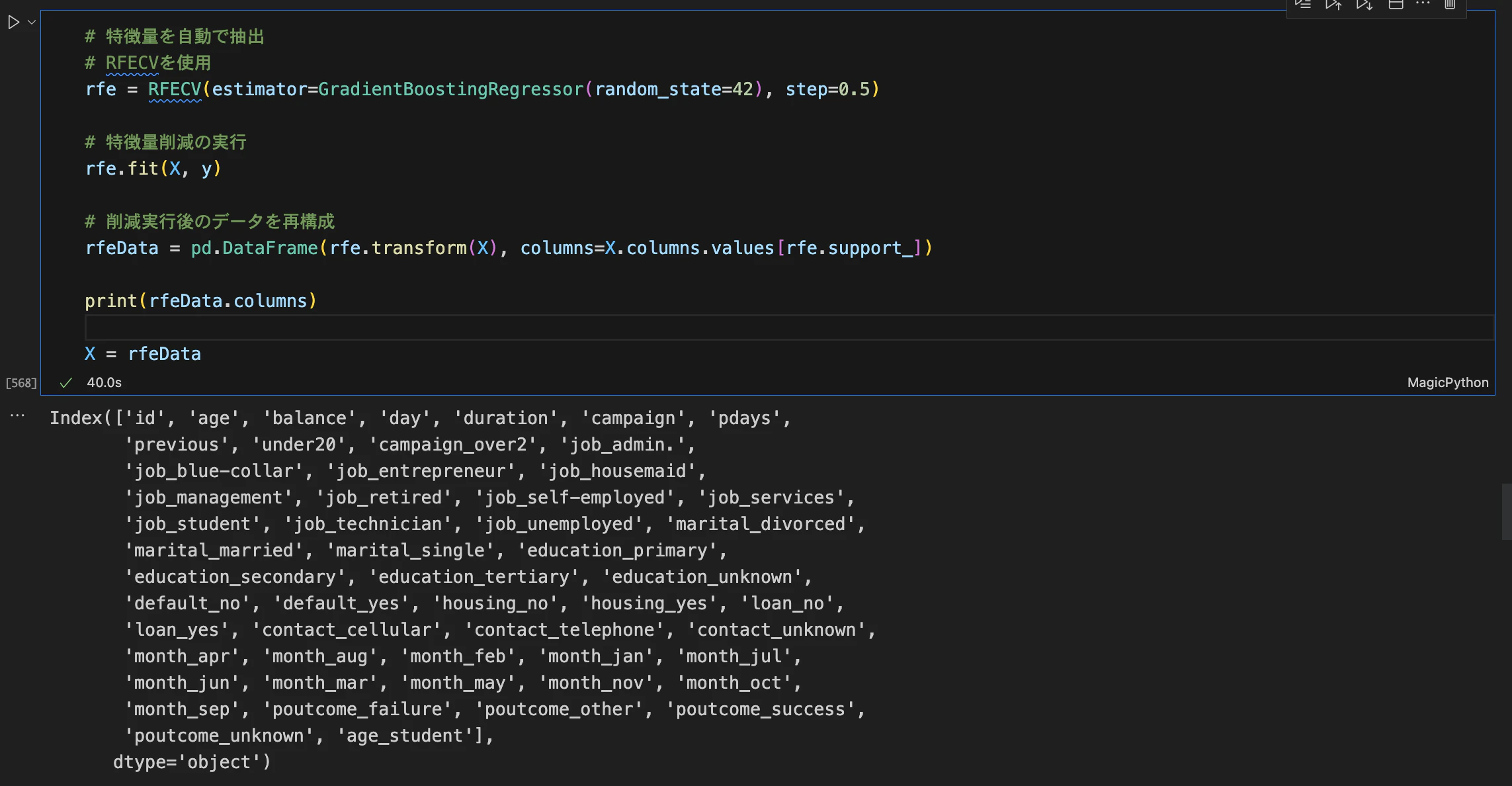
秘伝の手順⑥:モデルを選ぼう
次に、分析の目的に合ったモデルを選択します。モデルの選択は、分析の成果に大きく影響します。迷ったら、GBDTやGBRTなどの高性能なモデルを試してみるのも良いと思います。(困ったらこれを使っておけば、間違いない笑)
なんちゃってデータサイエンティストなので、モデルを選ぶ時間にはあまり時間を割きません。とりあえず一般的に高精度といわれるものを使えばOK。
秘伝の手順⑦:検証しよう
作成したモデルが正確に機能しているかを確認するために、ホールドアウト法や交差検証を行います。これにより、モデルが過学習に陥っていないかをチェックし、モデルの信頼性を高めることができます。特に理由がなければ、交差検証をオススメします。理由は未知のデータ(説明変数だけ持つテストデータ)への汎用力が高いからです。
※ローカルPCの環境で行う場合、交差検証の中でもRandomizedSearchCVは処理が早く、そこそこのクオリティも魅せてくれるのでオススメ。
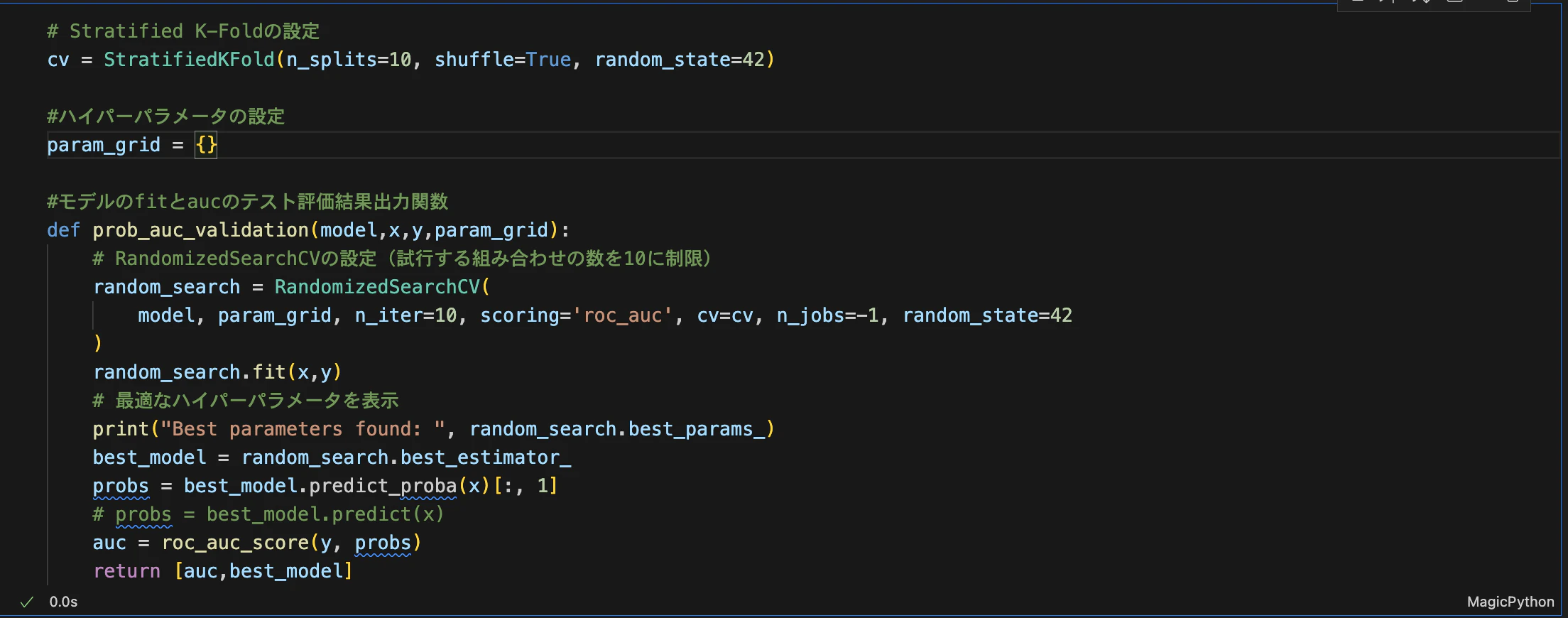
秘伝の手順⑧:パラメータを調整しよう
モデルの精度をさらに高めるためには、パラメータの微調整が必要です。ここでの調整は、分析結果の精度を大きく左右します。ChatGPTに適切なパラメータ設定を提案してもらうのも一つの方法です。
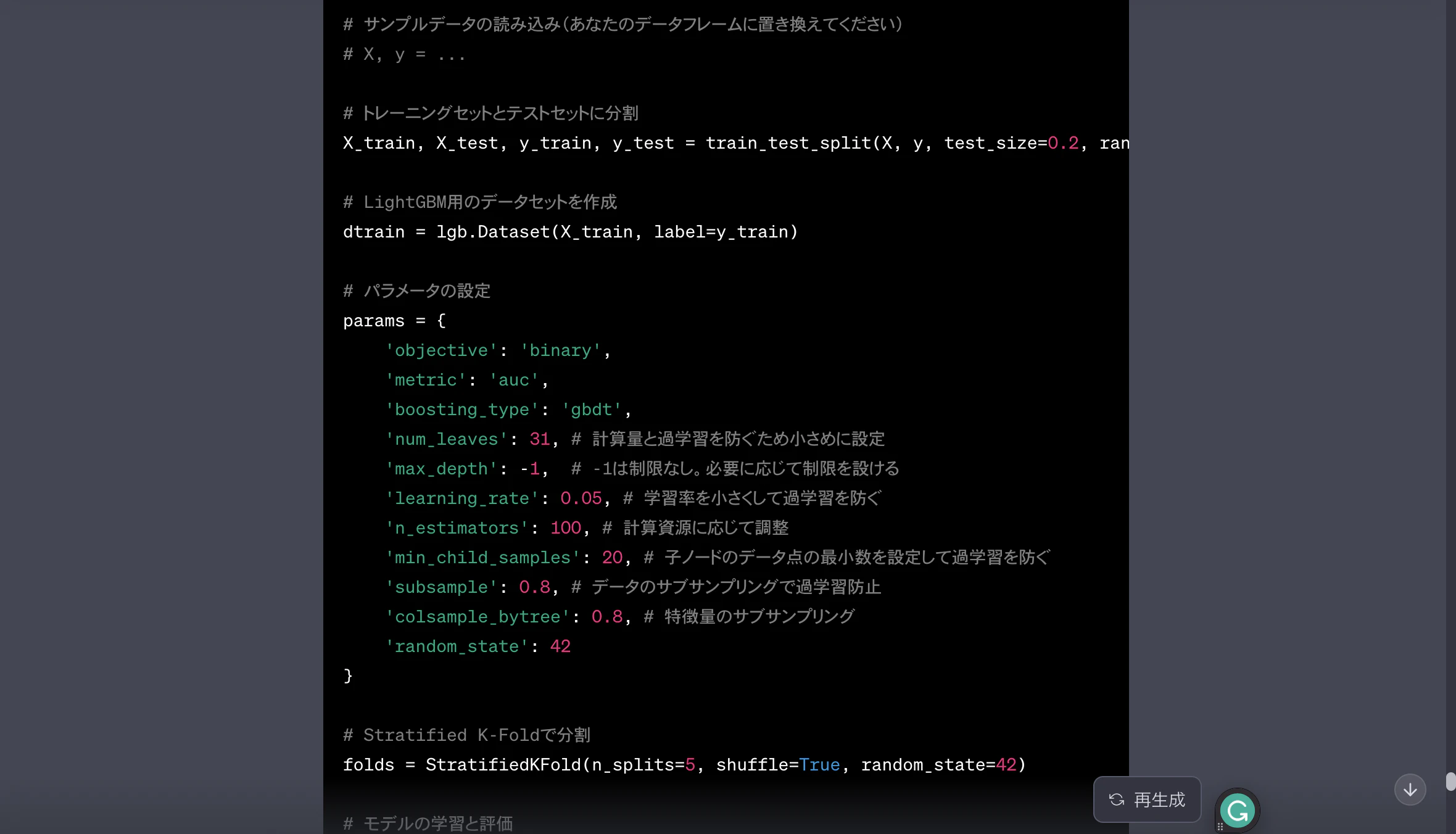
秘伝の手順⑨:壁打ちしよう
最後に、分析結果を他人・仕事の依頼者にも理解できるように、自分の言葉で説明できるようにしましょう。
これができれば、あなたも立派な「なんちゃってデータサイエンティスト」の仲間入りです。
おわりに
以上が、ChatGPTを使って「なんちゃってデータサイエンティスト」になるための秘伝の手順です。このステップを踏むことで、データサイエンス(厳密には機械学習)を使った分析が一通り出来るようになります。
但し、この記事でご紹介したスキルセットは、データサイエンスについて知ったかぶれる最低ラインのものなので、更なる高みを目指したい人・より高度な分析を実現したい人は、アカデミックな勉強も怠らずに....