はじめに
はじめまして。竜太(仮名)です。テクニカルアーティストしてます。最近はAIによるアセット生成にも興味持ってます。
本記事では、DeepL翻訳の検証がてらNetEaseさんの論文「Face-to-Parameter Translation for Game Character Auto-Creation」(2D顔画像→3C顔CG制御用パラメータ生成)の理解を深めるために冬休み中に読んでみました。ソウルキャリバーのようなキャラクリシステムがないと応用利かない技術ではありますがゲーム開発会社には有益そうだったので日本語化してみました。良ければご活用ください。また誤訳や詳しい人いたらフィードバックお待ちしています。
抄録(Abstract)
キャラクターカスタマイズシステムは、ロールプレイングゲーム(RPG)において重要な要素であり,プレイヤーはデフォルトのテンプレートを使用するのではなく,自分の好みに合わせてゲーム内キャラクターの顔写真を編集することができる.本論文では、入力された顔写真に応じて、プレイヤーのゲーム内キャラクターを自動的に作成する方法を提案する。本論文では、物理的に意味のある顔のパラメータの大集合に対して最適化問題を解くことで、顔の類似度測定とパラメータ探索のパラダイムの下で上記の「芸術的な創造」プロセスを定式化する。作成された顔と実物の顔との距離を効果的に最小化するために、「識別的損失(Discriminative Loss)」と「顔内容損失(Face Content Loss)」の2つの損失関数を特別に設計する。ゲームエンジンのレンダリングプロセスは微分不可能であるため、ゲームエンジンの物理的な挙動を模倣する「イミテータ(Imitator)」として生成ネットワークをさらに導入し、ニューラル形式の変換フレームワークの下で提案手法を実装し、パラメータを勾配降下法(Gradient Decense)で最適化することを可能にしました。実験の結果,本手法は,入力された顔写真と作成されたゲーム内キャラクターとの間で,大域的な外観と局所的なディテールの両方において,高い生成類似性を達成していることが示された.本手法は、昨年の新作ゲームに導入され、現在までに100万回以上の利用実績があります。
1. 序章
キャラクターカスタマイズシステムは、ロールプレイングゲーム(RPG)の重要な要素であり、プレイヤーはデフォルトのテンプレートを使用するのではなく、自分の好み(例えば、ポップスターや自分自身)に応じてゲーム内のキャラクターのプロフィールを編集することができます。
最近のRPGではそのため、キャラクターのカスタマイズシステムは、プレイヤーの没入感を高めるために、ますます洗練されてきています。その結果、多くのプレイヤーにとって、キャラクターのカスタマイズは時間と手間のかかるものとなっています。例えば、『Grand Theft Auto Online1』、『Dark Souls III2』、『Justice3』などでは、実際の顔写真をもとに希望の顔を持つゲーム内キャラクターを作成するために、プレイヤーはかなりの練習をしても、何百ものパラメータを手動で調整するのに数時間を費やさなければなりません。
RPGにおけるキャラクターの顔を作成するための標準的なワークフローは、まず顔のパラメータを大量に設定することから始まります。ゲームエンジンは、ユーザーが指定したパラメータを入力として取り込み、3Dの顔を生成します。おそらく、ゲームキャラクターのカスタマイズは、「単眼3D顔再構成」[2, 34, 37]や「スタイル変換」[10-12]の問題の特別なケースと考えることができます。画像の意味的内容と三次元構造を生成することは、コンピュータビジョンの分野では長い間困難な課題でした。
近年、深層学習技術の発展のおかげで、コンピュータは深層畳み込みニューラルネットワーク(CNN)の利点を利用して、新しいスタイルの画像を自動的に生成し[12, 16, 25]、単一の顔画像から3D構造を生成することさえできるようになりました[34, 37, 39]。
しかし、残念ながら上記の方法をゲーム環境に直接適用することはできません。その理由は3つあります。
- **第1**に、これらの方法は、パラメータ化されたキャラクタを生成するように設計されていませんが、これは、ほとんどのゲームエンジンにとって不可欠なものであり、通常、画像や3Dメッシュグリッドではなく、ゲームキャラクタのカスタマイズされたパラメータを取り込むためです。
- **第2**に、これらの方法は、ほとんどのユーザが3Dメッシュグリッドまたはラスタライズされた画像を直接編集することが非常に困難であるため、ユーザのインタラクションに優しくありません。
- **最後**に、ユーザが指定したパラメータを与えられたゲームエンジンのレンダリングプロセスは微分できないため,ゲーム環境でのディープラーニング手法の適用性がさらに制限されています。
以上の問題点を考慮して,本論文では,ゲーム内キャラクターの自動生成のための手法を提案する.
図1に示すように、本研究では、顔の類似度測定とパラメータ探索のパラダイムの下で、顔のパラメータの大集合に対する最適化問題を解くことで、上記のような「芸術的な創造」プロセスを定式化しています。本研究では、顔の類似度測定とパラメータ探索のパラダイムの下で、顔のパラメータの大集合に対する最適化問題を解くことで、上記のような「芸術的な創造」プロセスを定式化しています。これまでの3次元顔再構成アプローチ[2, 34, 37]は、3次元顔メッシュグリッドを生成するものであったが、本手法では、物理的に明確な意味を持つ顔パラメータの集合を予測することで、骨駆動モデルの3次元プロファイルを生成する。我々の手法では、パラメータの各々は、位置、向き、スケールを含む各顔コンポーネントの個々の属性を制御する。さらに重要なことに、本手法は、作成結果に基づいて、プレイヤーが必要に応じてプロファイルをさらに改良することができるように、追加のユーザーインタラクションをサポートしている。
図1. 本手法の概要。我々は、入力された顔写真に基づいて、顔の類似度測定と物理的に意味のある顔パラメータの大規模なセットの検索の下で定式化することができるゲームキャラクターの自動作成のための方法を提案します。ユーザーは、必要に応じて顔のパラメータを微調整することができます。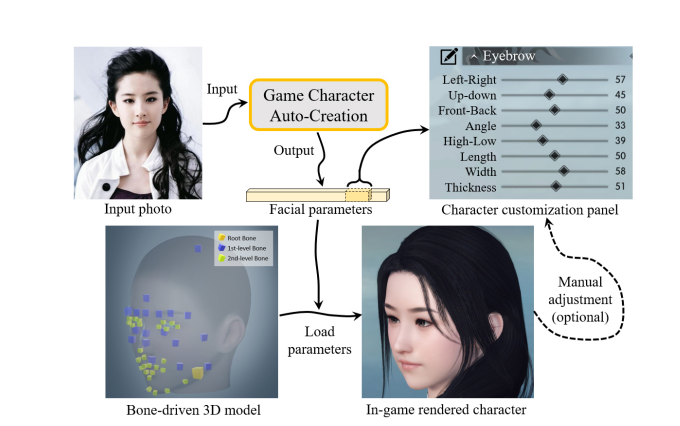
ゲームエンジンのレンダリングプロセスは微分できないため、ゲームエンジンの物理的な動作を模倣する「イミテータ」として生成ネットワークGを設計し、ニューラルスタイル変換フレームワークの下で実装し、勾配降下を用いて顔のパラメータを最適化することで、本手法を「Face-to-Parameter (F2P)」変換手法と呼ぶことにする。本手法における顔パラメータ探索は、基本的に領域横断的な画像類似度測定問題であるため、ディープCNNとマルチタスク学習の利点を活かして、「識別損失(Discriminative Loss)」と「顔コンテンツ損失(Facial Content Loss)」の2種類の損失関数を具体的に設計している。
前者は大域的な顔貌の類似度測定に対応し,後者は局所的な詳細に焦点を当てている.すべてCNNで設計されているため、我々のモデルは統一されたエンドツーエンドのフレームワークで最適化することができます。このようにして、作成された顔と実際の顔との距離を最小化することで、入力された写真を効果的にリアルなゲーム内キャラクターに変換することができます。本手法は2018年10月から新規ゲームに導入され、現在では100万回以上のサービスを提供しています。
我々の貢献をまとめると以下の通りである。
- 1) 顔からパラメータへの変換とゲームキャラクターの自動作成のためのエンドツーエンドアプローチを提案する。我々の知る限りでは、このトピックに関する先行研究はほとんどない。
- 2) ゲームエンジンのレンダリングプロセスは微分可能ではないため、ゲームエンジンの挙動を模倣するためのディープジェネレーティブネットワークを構築し、イミテータを導入する。このようにして、勾配(Gradient)を入力にスムーズに逆伝播させることで、勾配降下法によって顔のパラメータを更新することができるようにする。
- 3) 2つの損失関数は、クロスドメイン顔類似度測定のために特別に設計されている。提案された 目的はマルチタスク学習のフレームワークで共同最適化することができます。
2. 関連研究
ニューラルスタイル変換 (Neural Style Transfer)
ある画像から別の画像へのスタイル変換は、長い間、画像処理における挑戦的な課題であった[10, 11]。近年、ニューラルスタイル変換(NST)は、深い畳み込み特徴(Deep Convolutional Features)を統合することで、入力画像から「コンテンツ」と「スタイル」を明示的に分離することを可能にするスタイル変換(Style Transfer)タスクにおいて大躍進を遂げている[10-12]。最近のNSTモデルのほとんどは、以下の目的関数を最小化するように設計されている。

式(1)で、_Lcontent_と_Lstyle_は画像内容と画像スタイルの制約に対応し、_λ_は上記2つの目的のバランスを制御する。現在のNST手法は、グローバル手法[5, 9, 12, 19, 21, 26, 29, 35, 36]とローカル手法[6, 25, 27]の2つのグループに分けることができ、前者はグローバルな特徴統計量に基づいてスタイルの類似度を測定し、後者はローカルな詳細をより良く保存するためにパッチレベルのマッチングを行う。グローバル手法とローカル手法の両方の利点を統合するために,最近ではハイブリッド手法 [16] が提案されている.しかし、これらの手法は、骨駆動型の 3D 顔モデルではなく、画像から画像への変換に特化して設計されているため、ゲーム環境には適用できません。
単眼3D顔再構成 (Monocular 3D face reconstruction)
単眼3D顔再構成は、単一の2D顔画像から人間の顔の3D構造を復元することを目的としています。このグループの伝統的なアプローチは、3D morphable model (3DMM) [2] とその変種[3, 32]であり、3D顔モデルは最初にパラメータ化され[14]、その後、2D顔画像と一致するように最適化されます。近年、ディープラーニングに基づく顔再構成手法は、2D画像から3Dメッシュグリッドへのエンドツーエンド再構成を実現することができるようになってきています[8, 34, 37-40]。しかし,これらの手法は3Dメッシュグリッド上での編集が容易ではなく,生成された顔パラメータが明示的な物理的意味を欠いているため,ユーザのインタラクションには不親切である。
我々と似たような研究としてGenovaの「微分可能レンダラ」[13]があり,微分可能なラスタライザを用いてパラメータ化された3D顔モデルを直接レンダリングする.本論文では、CNNモデルを用いて、ゲームエンジンの種類や3Dモデル構造に関係なく、より統一的に差別化して模倣するソリューションを紹介する。
Generative Adversarial Network(GAN)
上記のアプローチに加えて、GAN[15]は画像生成[1, 30, 31, 33]で大きな進歩を遂げており、画像スタイルの変換タスク[4, 20, 28, 44, 46]で大きな可能性を示している。我々の手法と類似したアプローチとして、Tied Output Synthesis (TOS) [41]があり、これは人間の写真に基づいてパラメータ化されたアバターを生成するために敵対的訓練を利用している。しかし,この手法は連続的な顔のパラメータではなく,離散的な属性を予測するように設計されている.また、RPGにおいて、2D写真から3Dの顔パラメータの大集合を直接予測する学習は、2Dから3Dへの内在的な対応関係が「1対多」の写像であるため、パラメータが曖昧になるという欠陥が生じる。このため、連続的な顔パラメータを直接学習して予測するのではなく、生成された顔と実物の顔の類似度が最大になるように入力顔パラメータを最適化することで、NSTフレームワークの下で顔生成をフレーム化します。
3. 方法
我々のモデルは、イミテータG(x)と特徴抽出器F(y)から構成されており、前者は、ユーザがカスタマイズした顔パラメータxを取り込み、「レンダリングされた」顔画像yを生成することでゲームエンジンの動作を模倣することを目的とし、後者は、顔パラメータを最適化するために顔の類似度測定を行うことができる特徴空間を決定します。本手法の処理パイプラインを図2に示します。
図2. 提案手法の処理パイプライン 。提案手法のモデルは、イミテータG(x)と特徴抽出器F(y)から構成されています。前者は、ユーザがカスタマイズした顔パラメータxを取り込み、「レンダリングされた」顔画像yを生成することで、ゲームエンジンの動作をシミュレートすることを目的としています。後者は、顔のパラメータの最適なセットを探索するために、顔の類似度測定を実行することができる特徴空間を決定する。
3.1. イミテーター
本研究では、ゲームエンジンの入出力関係に適合するように畳み込みニューラルネットワークをイミテータとして訓練し、キャラクターカスタマイズシステムを微分可能にした。我々のイミテータG(x)は、DCGAN[33]と同様のネットワーク構成を採用しており、8つの転置畳み込み層から構成されている。図3にイミテータのアーキテクチャを示す。簡単にするために、我々のイミテータGは、対応する顔のカスタマイズパラメータを持つ顔モデルの正面図にのみ適合する。
図3. イミテータG(x)のアーキテクチャ。入力された顔のカスタマイズパラメータxから、ゲームエンジンが生成したレンダリングされた顔画像yˆへのマッピングを学習するために、イミテータを訓練します。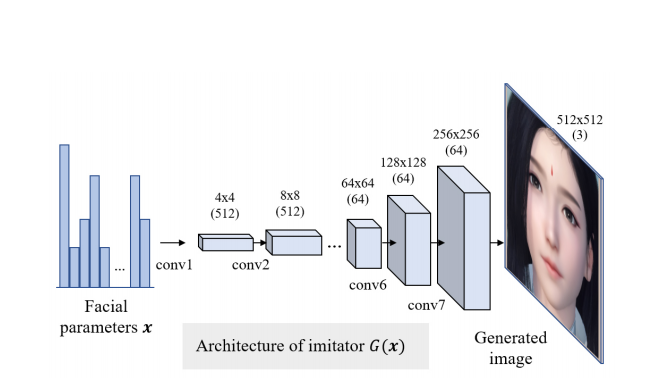
我々は、イミテーターの学習と予測を、標準的なディープラーニングに基づいた回帰問題としてフレーム化し、ゲーム内でレンダリングされた画像と生成された画像の間の差をそれらの生のピクセル空間で最小化することを目指します。
イミテータを学習するための損失関数は以下のように設計されています。
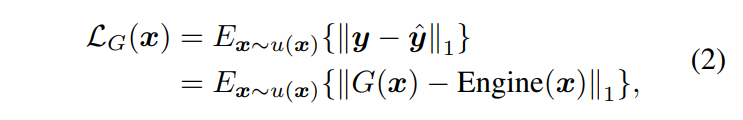
ここで、_x_は入力された顔のパラメータ、_G(x)_はイミテーターの出力、_yˆ = Engine(x)_はゲームエンジンのレンダリング出力を表します。l1の方がブレが少ないため、l2ではなくl1の損失関数を使用しています。入力パラメータxは、多次元一様分布u(x)からサンプリングされます。最後に、我々は次のような問題を解くことを目指しています。

トレーニングプロセスでは、対応する顔のカスタマイズを持つ20,000個の個々の顔をランダムに生成します。
図4. イミテータG(x)によって生成された顔画像とそれに対応する基底真理値の例。これらの画像の顔パラメータは手動で作成されています。
"Justice "のゲームエンジンを使用して、パラメータを設定しています。80%の顔サンプルがトレーニングに使用され、残りの部分が検証(テスト)に使用されます。図4は、我々のイミテーターの「レンダリング」結果の3つの例を示しています。これらの画像の顔のパラメータは手動で作成されています。トレーニングサンプルは、顔のパラメータの統一された分布からランダムに生成されているため、ほとんどのキャラクターにとっては奇妙に見えるかもしれません(補足資料を参照してください)。それでも、図4からわかるように、生成された顔画像とレンダリングされたGround Truthは、髪の毛などの複雑なテクスチャを持ついくつかの領域でさえ、高い類似性を共有しています。これは、我々のイミテータが、低次元の顔の多様体に訓練データを適合させるだけでなく、異なる顔のパラメータ間の相関関係を切り離すことを学習していることを示している。
3.2. 顔の類似度測定
十分に訓練されたイミテーターGが得られれば、顔パラメータの生成は本質的に顔の類似度測定問題となる。入力された顔写真とレンダリングされたゲームキャラクターは異なる画像領域に属しているため、顔の類似度を効果的に測定するために、グローバルな顔の外観とローカルな詳細の両方の観点から、2種類の損失関数を測定値として設計します。その損失関数を生のピクセル空間で直接計算するのではなく、ニューラルスタイル伝達のフレームワークを利用して、ディープニューラルネットワークで学習した特徴空間上で損失を計算する。パラメータの生成は、図 5 に示すように、イミテーターの多様体(manifold)上で、y と基準顔写真 yr との距離が最小となる最適な点 y ∗ = G(x∗) を見つけることを目的とした探索プロセスと考えることができます。
3.2.1 識別損失(Discriminative Loss)
本研究では、顔認識モデルF1を、顔の形状や全体的な印象など、2つの顔のグローバルな外観の測定値として導入する。我々は、画像スタイル変換(Image Style Transfer)[12]、超解像[21, 24]、特徴量可視化(Feature Visualization)[45]など様々な分野で広く応用されている知覚距離の考え方を踏襲し、同一人物の異なる顔写真でも、その特徴量は似たような表現であると仮定する。このために、最新の顔認識モデル "Light CNN-29 v2" [42]を用いて、2つの顔画像の256次元顔埋め込み(Facial Embeddings)を抽出し、それらの間の余弦距離を類似度として計算する。損失関数は、実物の写真の顔とイミテーターの顔が同一人物のものかどうかを予測することから、「識別損失」と呼ばれている。上記処理の識別損失関数は次のように定義される。
ここで、2つのベクトル_a_と_b_の間の余弦距離は次のように定義されています。

3.2.2 顔のコンテンツロス(Facial Content Loss)
識別損失に加えて、顔の意味的セグメンテーションモデルから抽出された顔の特徴に基づいてピクセル単位の誤差を計算することにより、コンテンツ損失を定義する。顔のコンテンツロスは、目、口、鼻のような2つの画像における異なる顔の構成要素の形状と変位に対する制約と考えることができる。我々は日常的な画像よりも顔の内容をモデル化することを重視しているため、顔意味的セグメンテーションネットワークは、ImageNetデータセット上で事前に訓練された既製のモデルを使用する代わりに、顔画像の特徴を抽出するために特別に訓練されています[7]。我々は、顔のセグメンテーションモデルを構築します。図5. ゲームキャラクターの自動生成は、イミテータのマニホールド上での探索処理と考えることができる。最適な点を見つけることを目指すy∗ = G(x∗) は,特徴空間内の y と参照顔写真 yr との距離を最小化する.
図6. 2つのクロスドメイン顔画像間の類似度を効果的に測定するために、学習した特徴空間上で定義される識別損失L1と顔内容損失L2の2種類の損失関数を設計します。
Resnet-50 [17]をベースにしており,全結合層を削除し,出力解像度を1/32から1/8に増加させている.このモデルは、よく知られているHelenの顔の意味的セグメンテーションデータセット[23]を用いて学習する。顔の意味的特徴(Facial Semantic Feature)の位置感度を向上させるために、さらに、セグメンテーション結果(クラスごとの確率マップ)を特徴マップのピクセルごとの重みとして使用して、位置感度コンテンツ損失関数を構築する。この顔コンテンツロスは以下のように定義される。

ここで、_F2_は入力画像から顔の意味的特徴量へのマッピングを表し、_ω_は特徴量のピクセル重みを表し、例えば、_ω1_は目と鼻と口のマップを表します。我々のモデルの最終的な損失関数は、2つの目的L1とL2の線形組み合わせとして書くことができます。

ここで,パラメータ_α_は2つのタスクの重要度のバランスをとるために用いられる.図6に特徴抽出器の説明図を示す.勾配降下法を用いて、以下の最適化問題を解く。
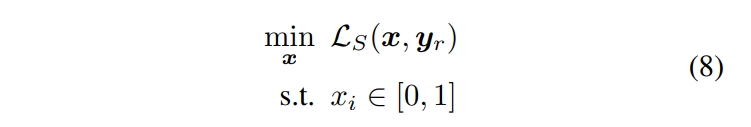
ここで、_x = [x1, x2, ... , xD]_は最適化される顔のパラメータを表し、_yr_は入力された参照顔写真を表す。本手法の完全な最適化プロセスは以下のように要約される。
- ステージⅠ:イミテーターG、顔認識ネットワーク_F1_、顔分割ネットワーク_F2_を訓練(Train)する。
-
ステージⅡ: _G, F1, F2 _を固定し、顔パラメータ x を初期化して更新し、反復回数が最大になるまで繰り返す。

3.3. 実装の詳細
イミテータ(Imitator):イミテータでは、畳み込みカーネルのサイズを4×4に設定し、各畳み込み層のストライドを2に設定することで、各畳み込みの後に特徴マップのサイズが2倍になるようにしています。バッチ正規化とReLU活性化は、出力層を除くすべての畳み込み層の後に、イミテータに埋め込まれている。
また、学習にはSGDオプティマイザを使用し、バッチサイズ=16、運動量=0.9の条件で学習を行います。学習率は0.01に設定し、学習率の減衰は50エポックごとに10%に設定し、500エポックで学習を停止しています。
顔セグメンテーションネットワーク:セグメンテーションネットワークのバックボーンとしてResnet-50を使用しており、完全に接続された層を削除し、その上部に1×1の畳み込み層を追加しています。また、出力解像度を上げるために、Conv 3とConv 4ではストライドを2から1に変更している。我々のモデルは,ImageNet [7]で事前に学習した後,Helenの顔の意味的セグメンテーションデータセット[23]でピクセル単位のクロスエントロピー損失を用いて微調整した.学習率が0.001に設定されていることを除いて、我々はイミテーターと同じ訓練構成を使用しています。
顔のパラメータ:顔パラメータの次元Dは、「男性」が264、「女性」が310に設定されている。これらのパラメータのうち、208は連続値(例えば、眉毛の長さ、幅、太さ)であり、残りは離散値(例えば、髪型、眉毛のスタイル、ひげのスタイル、口紅のスタイル)である。これらの離散的なパラメータは、ワンホットベクトルとして符号化され、連続的なパラメータと連結される。ワンホット・エンコーディングは最適化が難しいので、ソフトマックス関数を用いて、これらの離散変数を以下の変換で平滑化します。
式(9)は離散パラメータのワンホットエンコーディングの次元を表す。β > 0は平滑度を制御する。最適化を高速化するために、比較的大きな_β_、例えば_β_=100を設定する。顔パラメータ_x_の初期化には "平均顔 "を使用しています。 顔パラメータの詳細については、補足資料を参照してください。
最適化(Optimization):ステージIIの最適化については、_α_を0.01、最大反復回数を50、学習率_μ_を10、減衰率を20%とし、5回の反復ごとに最適化を行う。
顔画像のアライメント:顔のアライメントは、特徴抽出器に入力される前の写真をアライメントするために(dlibライブラリ[22]を使用して)実行され、レンダリングされた「平均顔」を参照として使用します。
4. 実験結果と分析
本研究では、50枚の顔アップ写真からなる有名人のデータセットを構築し、実験を行った。図7は、入力写真と生成された顔のパラメータの一部を示しており、このパラメータから、ゲームエンジンによって複数の視点からゲーム内のキャラクターをレンダリングすることができ、入力写真との類似性が高いことも表している。より多くの生成例については、補足資料を参照してください。
図7. 本手法を用いた入力写真と生成されたキャラクター(「アイデンティティ」と「表情」の両方をモデル化している)。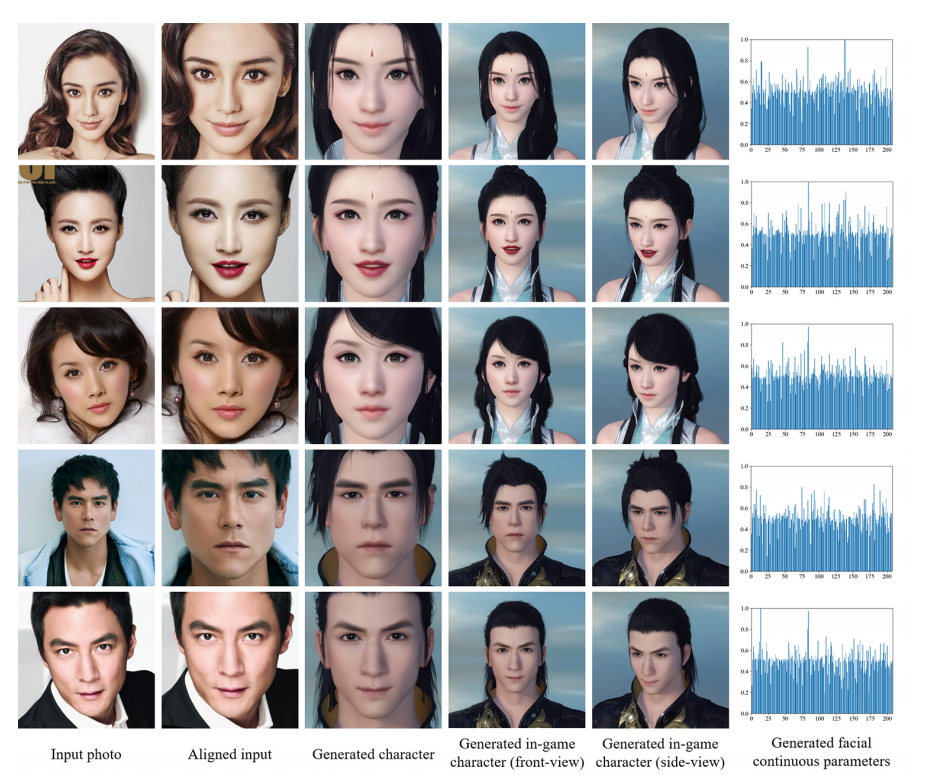
4.1. アブレーション(切除)研究
本研究では、提案フレームワークの構成要素である1)識別的損失と2)顔内容損失の重要性を分析するために、我々のデータセットを用いてアブレーション研究を行った。
1) 識別損失(Discriminative Loss)
識別損失を用いた場合と用いない場合を問わず、Gatysのコンテンツロス[12]をベースラインとした手法を用いています。図8に示すように、顔認識モデル[42]の出力から余弦距離を用いて、各写真と生成結果の類似度を計算した。識別損失を統合することで、類似度が顕著に改善されていることがわかります。
図8. 異なる目的関数間の性能比較
2)顔コンテンツ損失(Facial Content Loss)
図9は、顔内容損失を考慮した場合と考慮しなかった場合の比較です。より分かりやすいように、顔の意味的マップ(Facial Semantic Maps)と顔の構成要素のエッジを抽出しています。図9では、エッジマップの黄色の画素が参照写真のエッジに対応し、赤色の画素が生成された顔に対応している。顔コンテンツロスを適用することで、入力写真と生成された顔の間の画素位置の対応性が向上していることがわかります。
図9. 顔コンテンツロスの助けを借りて生成された顔の「ある」または「なし」の比較。最初の列は、我々の顔セグメンテーションモデルによって生成されたアラインメントされた写真とそのセマンティックマップを示しています。2番目と3番目の列は、顔コンテンツロスを利用して生成された顔を示しています。黄色のピクセルは参照写真のエッジに、赤のピクセルは生成された顔に対応しています。
3) 主観的評価
2つの損失の重要性を定量的に分析するために、Wolfら[41]の主観的評価法を用いています。具体的には、類似度測定損失関数(L1のみ、L2のみ、L1+L2)の構成を変えた50グループのキャラクター自動作成結果をデータセット上に生成する。次に、15名の専門家以外の有志に、各グループの中で最も優れた作品を選んでもらい、その中から3つのキャラクターをランダムな順序で選んでもらう。最後に、出力されたキャラクターの選択率を、ボランティアによってそのグループの中で最も優れたものとして何%選ばれたかとして定義し、全体の選択率を結果の質を評価するために使用する。その統計を表1に示すが、両方の損失が我々の方法にとって有益であることを示している。
4.2. 他の方法との比較
我々は、我々の手法を、いくつかの一般的なニューラルスタイル変換手法であるグローバル・スタイル法[12]とローカル・スタイル法[16]と比較しています。これらの手法は3D文字の生成に特化して設計されたものではないが,図9と比較している.顔コンテンツ損失の助けを借りて生成された顔の「あり」と「なし」の比較。最初の列は、我々の顔セグメンテーションモデルによって生成されたアラインメントされた写真とそのセマンティックマップを示しています。2番目と3番目の列は、顔コンテンツ損失の有無に関わらず、生成された顔を示しています。黄色のピクセルは参照写真のエッジに、赤のピクセルは生成された顔に対応しています。
表1. 我々の手法の2つの技術要素の主観的評価結果
1)識別損失L1, 2)顔内容損失L2. 選択率が高いほど良好であることを示している。
これらの手法は、多面的に我々のアプローチと類似しているため,これらの手法を使用しています.第一に、これらの方法は、すべてディープラーニング特徴に基づいて2つの画像の類似度を測定するように設計されている。第二に、これらの手法における反復最適化アルゴリズムは、すべてネットワークの入力で実行される。
図10に示すように、画像のスタイルをコンテンツから分離して再構成することで、鮮明なゲームキャラクターを生成することが困難であることがわかる。これは、生成された画像がゲームキャラクターマニフォールドから正確にサンプリングされていないため、RPG環境での適用が困難であるためである。また,我々の手法を一般的な単眼3D顔再構成手法と比較した.3DMM-CNN[39]と比較した結果を図10の右側に示す。3DMM 法では顔の輪郭が似ているマスクしか生成できないのに対し、本手法では自動生成されたゲームキャラクターは入力との類似度が高いことがわかる。
生成された顔とゲーム内スタイルリファレンスとの類似性を定量的に評価するために、Mode Score (MS) [43]とFrechet Inception Distance ´(FID) [18]を指標として使用した。各テスト画像について、イミテータートレーニングセットからランダムに1枚の画像を参照画像として選択し、テストセット全体の平均MSとFIDを計算します。
図10. 他のNST手法との比較。グローバルスタイル[12]とローカルスタイル[16]では、各性別の「平均顔」をこれらのNST手法のスタイル基準としています。また、人気のある単眼3D顔再構成法3DMM-CNN [39]と比較する。

表2. 異なる手法のスタイルの類似性と速度性能。(Mode Scoreが高いか、FIDが低いほど良いことを示す)
上記の操作を5回繰り返して、表2のような最終的な平均値と標準偏差を計算します。 また,各手法の実行時間も記録されている.我々の手法は、他の手法と比較して、より高いスタイル類似性と良好な速度性能を達成している。
4.3. ロバスト性と限界
さらに、我々の手法は、図 11 に示すように、異なるボケ(Blurring)と照明条件で評価した結果、これらの変化に対してもロバストであることがわかった。最後のグループは、我々の手法の失敗例を示すものである。L2は局所的な特徴量で定義されているため、我々の手法はポーズの変化に敏感である。
図11. ロバスト性に関する実験 
4.4. 芸術的な似顔絵を用いた生成
また、実物の写真に限らず、本実施形態では、スケッチ画像や風刺画などの一部の芸術的な似顔絵についても、ゲームキャラクタを生成することができる。図 12 に生成結果の一例を示す。画像は全く異なる分布から収集されていますが、本手法では生のピクセルではなく顔の意味論(Facial Semantics)に基づいて類似度を測定しているため、高品質な結果が得られています。
図12. 芸術的な肖像画上でのゲームキャラクターの自動生成
5. 結論
本論文では、入力された顔写真に基づいてゲーム内キャラクターを自動生成する手法を提案する。本論文では、物理的に意味のある顔パラメータの大集合に対して最適化問題を解くことで、顔の類似度測定とパラメータ探索のパラダイムの下での生成を定式化する。実験の結果、我々の手法は、グローバルな外観と局所的な詳細の両方の点で、入力顔写真とレンダリングされたゲーム内キャラクターの間に高い生成類似性とロバスト性を達成していることを実証した。
A. 付録
A.1. ネットワークの構成
イミテータGと顔セグメンテーションネットワークF2の詳細な構成を表3と表4に示す。顔認識ネットワークF1、すなわちLight CNN-29 v2の詳細については、Wu et al.の論文[42]を参照されたい。具体的には、Convolution/Deconvolution層の_c×w×w/s_において、cはフィルタの数、_w×w_はフィルタの大きさ、_s_はフィルタのストライドを表す。Maxpool層の_w×w/s_では、_w_はプーリングウィンドウのサイズ、_s_はプーリングストライドを表す。n/s Bottleneck ブロック [17] では、n はプレーン数、s はブロックのストライドを表す。
表3. 我々のイミテーターGの詳細な構成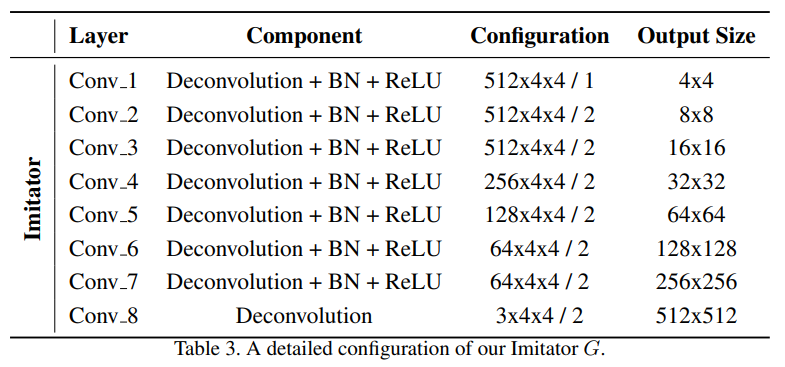
表4. 顔分割モデルF2の詳細構成
A.2. ゲーム内で生成されたキャラクタの例
図13. より多くの生成されたゲーム内キャラクター(女性)
図14. より多くの生成されたゲーム内キャラクター(男性)
A.3. より多くの比較結果
図15. 他のNST手法との比較結果。グローバルスタイル[12]とローカルスタイル[16]。各性別の「平均的な顔」をスタイル画像として使用しています。また、一般的な単眼3D顔再構成法(3DMM-CNN [39])との比較も行っています。
A.4. 我々のイミテーターのトレーニングサンプル
学習過程では、図16に示すように、通常の顔以外にランダムに生成されたゲームの顔を用いて、模倣機の学習を行います。実験では、女性と男性の3Dモデルに合わせて2つのイミテータを採用し、性別の異なるキャラクターを自動生成しています。
図16. イミテーターの訓練サンプルと対応する顔のパラメータ
A.5. 顔のパラメータの説明
表5は各フェイシャルパラメータの詳細な説明を示しており、「コンポーネント(Component)」はパラメータが属するフェイシャルパーツを表し、「コントローラ(Controllers)」は各フェイシャルパーツのユーザ調整可能なパラメータを表し(1つのコントローラは1つの連続パラメータに対応)、「#コントローラ(#Controllers)」はコントローラの総数、すなわち208個を表している。その上、女性用の離散パラメータ102(髪型22、眉スタイル36、口紅スタイル19、口紅色25)と、男性用の離散パラメータ56(髪型23、眉スタイル26、ひげスタイル7)が追加されている。
表5. 各顔のパラメータの詳細な解釈(連続部分)
おわりに
最近の3Dゲームはアバターのキャラクリシステムは必須になってきています。ただ個人的にゼロからチクチクアバターを作っていくのは面倒(さっさとゲームを始めたい)という思いがあるので、こういう補助システムで自分の顔写真や好きな有名人の写真を入力してそれをベースにカスタマイズできるのなら楽しそうです。これからこの手のシステムは主流になるのではないかと思います。一早く取り入れてるNetEaseさんはさすがAI先進国だなという感じです。
また、DeepL翻訳はGoogle翻訳よりも「読みやすい訳」をしてくれる印象です。もちろん完ぺきではなく修飾節を思いっきり無視して短縮化されていることもあったり二重翻訳したりもありますが、技術論文のベースを訳してくれる分には十分なクオリティな気がします。ゼロから翻訳するより雲泥の差がありますし微妙にうまく訳せない文章をいとも簡単に訳してくれて英語の勉強にもなります。これからもガンガン気になる論文を訳していきたいと思います。