はじめに
DeepL翻訳の検証がてらAdobeとStandford大学の共同論文「Contact and Human Dynamics from Monocular Video」を【動画ベースモーションキャプチャ最新技術】の理解を深めるために連休中に読んでみました。
※DeepL翻訳はGoogle翻訳よりも「読みやすい訳」をしてくれる印象です。もちろん完ぺきではなく修飾節を思いっきり無視して短縮化されていることもあったり二重翻訳したりもありますが、技術論文のベースを訳してくれる分には十分なクオリティです。
抄録
既存のディープモデルでは,映像から2Dおよび3Dの運動学的なポーズを予測するが,足が地面を貫通していたり,体が極端な角度で傾いていたりするなど,物理的な制約に反した目に見える誤差が含まれている。この論文では、初期の2Dおよび3Dポーズ推定値を入力とし、ビデオシーケンスから3Dの人間の動きを推定する物理ベースの手法を提示する。まず、手でラベルを付けずに学習した新しい予測ネットワークを用いて、地上での接触タイミングを推定する。次に、物理学に基づいた軌道最適化により、入力に基づいて物理的に実現可能な動きを解く。このプロセスにより、純粋な運動学的手法よりもはるかに現実的な運動が生成され、運動学的および動的妥当性の両方の定量的な測定値が大幅に改善されることを示す。本研究では、複雑な接触パターンを持つダンスやスポーツの動的な動きを対象としたキャラクタアニメーションやポーズ推定タスクにおいて、本手法を実証した。
1. 序章
単眼映像からの人間のポーズ推定のための最近の手法 [1,20,34,47] は、ボディフレーム3D座標における真のポーズとの絶対的な差が小さく、正確な全身のポーズを推定しています。しかし、ワールドフレームで復元された動きは、足がわずかに浮いていたり、地面を貫通していたり、体が前に傾いていたり後ろに傾いていたり、ジリジリとした振動するポーズのようなモーションエラーなど、多くの点で視覚的にも物理的にも不自然なものである。これらのエラーは、その後の動作の多くの使用を妨げることになります。例えば、行動、意図、感情の推論は、コンピュータアニメーションと同様に、ポーズ、接触、加速度の微妙な違いに依存することが多い。既存の手法は物理的な妥当性を考慮していないため、より多くの訓練データを追加してもこれらの問題を解決することはできません。
物理学に基づいた軌道最適化は、特に歩行やダンスのような動的な動きに対して、これらの問題に対する魅力的な解決策を提示している。物理学的には,ポーズ空間では表現しにくい重要な制約がありますが,力学的には簡単に表現できます.例えば,静的に接触している足は動かず,身体は接触に対して全体的に滑らかに動き,関節のトルクは大きくありません.しかし,全身ダイナミクスの最適化は,接触が不連続であることや,接触イベントの数が時間の経過とともに指数関数的に増加することなどから,非常に困難であることが知られています[40].その結果,接触とダイナミクスの複合最適化は局所的な最小値に非常に敏感になります.
本論文では、学習した姿勢推定と軌跡最適化による物理的推論を組み合わせて、単眼映像(図1)から動的に有効な全身運動を抽出する新しい手法を紹介します。入力として、運動学的ポーズ推定技術[4,47]の結果を使用しますが、これは全体のポーズは正確ですが、接触やダイナミクスは不正確です。我々の手法は、セントロイドダイナミクスと接触制約を持つ低次元の身体モデル[9,46]を利用して、これらの入力と密接に一致する物理的に検証された運動を生成します。まず、入力映像の2Dポーズから足の接触を推定し、それを物理学に基づいた軌道最適化で使用して、6次元の質量中心運動、足の位置、接触力を推定します。接触予測ネットワークが合成データ上で正確に学習できることを示す。これにより、初期接触推定と運動最適化を分離することができ、最適化がより容易になる。その結果、我々の手法は、物理的な精度を犠牲にすることなく、高度に動的な運動を扱うことができるようになった。本研究では,ダンス,歩行,スポーツなどの一人用の動的運動に焦点を当てている.
我々の手法は、最新の手法と比較して運動のリアルさを大幅に向上させ、シーン特性の推論や動作認識に役立つ多くの物理特性を推定することができる。我々は主に、動画からキャプチャした動きを仮想キャラクタにリターゲティングすることで、キャラクタアニメーションを対象とした手法を実証しています。推定された動きの物理的妥当性を測定するために設計された多数の運動学的・力学的メトリクスを用いて、本手法を評価する。提案手法は、動画からの人間の動き推定に物理的制約を組み込むための重要な一歩を踏み出すものであり、現実的でダイナミックなシーケンスを再構築できる可能性を示しています。
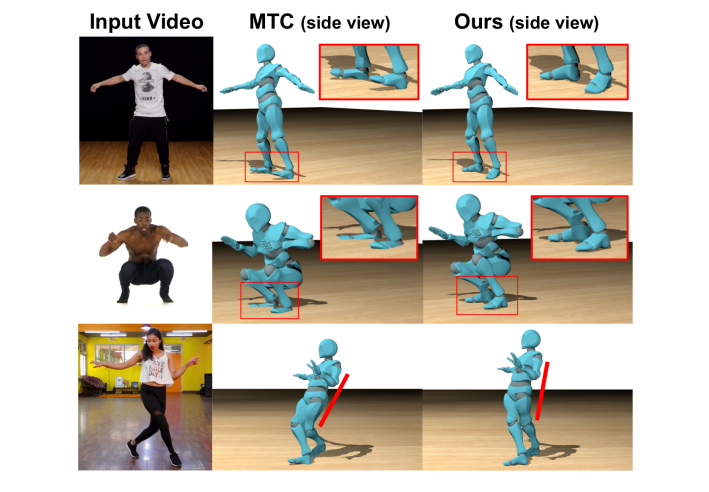
図1. 我々の接触予測と物理ベースの最適化は、足の浮き(上段)、足の貫通(中段)、不自然な傾き(下段)など、単眼トータルキャプチャ(MTC)[47]などからの3D人の動き推定によく見られる、物理的にありえない多くのアーチファクトを修正します。
関連業務
我々は、コンピュータビジョン、アニメーション、ロボット工学の各分野で、それぞれ長い歴史を持ついくつかの研究のスレッドを構築しています[11]。ここでは、最近のビジョンの成果を詳述する。最近の体位推定の進歩は、2Dの人間のキーポイントを正確に検出し [4,14,31]、1枚の画像から3Dの体位を推定することができる [1,20,34]。最近のいくつかの手法は、様々な形態の時間的手がかりを探索することにより、単眼映像から3Dの人間の動きを抽出する[21,30,48,47]。これらの手法はピクセル空間での人の動きを説明することに焦点を当てていますが、物理的な妥当性は考慮していません。最近のいくつかの研究では、人とその環境の間の相互作用を解釈して、それぞれについて推論を行う[7,13,49]があるが、これらの研究はいずれも静的な運動学的制約のみを使用している。Zouら[50]は、ビデオから3次元運動を最適化するために接触制約を推論している。我々は、ダイナミクスが人間とシーンの相互作用の推論を改善し、より物理的にもっともらしいモーションキャプチャを実現する方法を示している。
いくつかの研究では、運動学的追跡の問題に対処するために物理的制約を提案しています。Brubakerら[3]は、低次元歩行モデルに基づいた物理ベースのトラッカーを提案しています。WeiとChai [45]は、キーフレームと接触制約が提供されていると仮定して、ビデオから体の動きを追跡しています。我々の研究と同様に,Brubaker and Fleet [2] は全身運動のための軌道最適化を行っている.接触とダイナミクスを共同で最適化するために,彼らは接触に対する連続近似を用いている.しかし,ソフト接触モデルでは,不正確な遷移や剛性パラメータへの感度などの新たな問題が発生する一方で,局所最小値の問題にも悩まされます.さらに、彼らの低次元モデルは、質量中心の位置運動のみを含み、回転運動をうまく扱うことができません。これとは対照的に,我々は最適化を単純化するために前処理ステップで正確な接触初期化を行い,回転慣性をモデル化している.
Liら[27]は,動画から動的特性を推定している.Li ら [27] は,ポーズと接触を推定した後,軌道の最適化を行うという全体的なパイプラインを共有している.Li らが人と物体の相互作用のダイナミクスに焦点を当てているのに対し,我々は,ポーズや足の接触が複雑に変化するような,人の動き自体がよりダイナミックな動画に焦点を当てており,人と物体の相互作用は考慮していません.我々の縮小表現とは異なり、よりシンプルなデータ項を使用し、全身ダイナミクスの中で軌跡の最適化を行います。また,我々の自動データセット作成法とは異なり,分類器の学習には手でラベルを付けたデータが必要である.
先行する手法は,動画からキャラクターアニメーションのコントローラを学習する.Vondrakら[42]は,画像のシルエット特徴を用いてステートマシンコントローラを学習している.Pengら[36]は、入力されたビデオシーケンスから運動学的に推定されたポーズに従うことでスキルを実行するコントローラを訓練する。彼らは,さまざまなスキルについて印象的な結果を示している.彼らは、運動や接触の正確な再構成を試みておらず、これらのタスクの評価も行っておらず、むしろ制御学習に焦点を当てている。
我々の最適化は、コンピュータアニメーションにおける物理学に基づく手法、例えば[10,19,24,28,29,37,44]に関連している。我々の最適化の2つのユニークな特徴は、6次元の質量中心運動と接触制約を含む低次元ダイナミクス最適化を使用することで、全身最適化を必要とせずに重要な回転と足音の量を捉えることができることと、最適化の前に接触を判定するための分類器を使用することです。
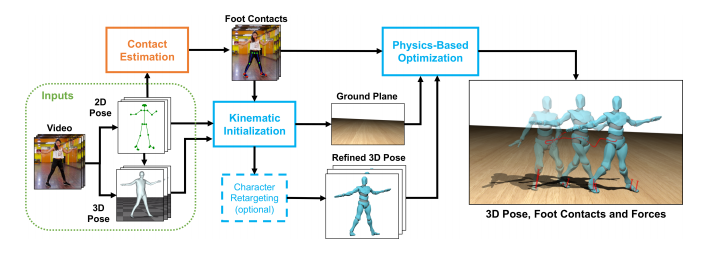
図2. 手法の概要
入力ビデオが与えられると,我々の手法は,既存の2Dおよび3Dポーズ法[4,47]からの初期推定から開始する.下半身の2D関節は、足の接触を推測するために使用されます(オレンジ色のボックス)。我々の最適化フレームワークは2つの部分(青枠)から構成されている.推定された接触と初期ポーズは、3D全身運動を洗練させ、地面にフィットさせる運動学的最適化で使用されます。これらは、ダイナミクスを適用した、物理学に基づいた軌道最適化のために与えられます。
3 物理学に基づく動作推定
本節では,図 2 にまとめた我々の手法を説明する.本手法の中核となるのは,物理学に基づいた軌道最適化であり,入力運動に力学を適用します(3.1節).足の接触タイミングは,最適化への他の入力とともに前処理(3.2節)で推定されます(3.3節).これまでの研究[27,47]と同様に、全身運動を回復するために、カメラの動きがなく、全身が見えることを前提としています。
3.1 物理ベースの軌道最適化
我々のフレームワークの中核は、入力として与えられた初期運動推定値に力学を強制する最適化である(3.3節参照)。その目的は、目的と制約を通して物理的推論を適用することで、運動の信憑性を向上させることである。我々は,物理的に妥当な運動量と接触時の静止した足で滑らかな軌跡を生成することで,一般的な知覚誤差,例えば,足が滑ったり地面に突き刺さったりするようなジッタリした不自然な動きを回避することを目的としている.
最適化は、全体的な運動、回転、接触をキャプチャした低次元のボディモデル上で実行されますが、すべての関節を最適化するという困難を回避します。回転のモデル化は腕振りや反振動のような重要な効果に必要であり[15,24,29],低次元のセントロイドダイナミクスモデルはヒューマノイドロボットのためのもっともらしい軌道を生成することができます[5,9,32].
我々の手法は,ロボットを固定質量と慣性モーメントを持つ剛体として扱うセントロイド力学の簡略化版を利用したWinklerら[46]の最近のロボット運動計画アルゴリズムに基づいています.彼らの手法は,以下に詳述するように,足の位置,接触力,接触時間とともに,質量中心(COM)の位置と回転を最適化することで,実現可能な軌道を見つけ出します.我々はこのアルゴリズムを我々のコンピュータビジョンタスクに適合するように修正する:我々は質量分布の変化(腕を振る)を可能にし、関心のある動的運動を推定できる時間的に変化する慣性テンソルを使用し、入力運動学的運動と足の接触を一致させるためにエネルギー項を追加し、我々のヒューマノイド骨格のための新しい運動学的制約を追加した。
入力
この方法では、初期推定を行います。COMの位置¯r(t)∈R3と方位θ¯(t)∈R3の軌跡、ボディフレーム慣性テンソル軌跡Ib(t)∈R3×3、足関節の位置p¯1:4(t)∈R3の軌跡を初期推定する。
足の関節は、左足指の付け根、左踵、右足指の付け根、右踵の4つがあり、i∈{1,2,3,4}としてインデックス化されている。これらの入力は離散的なタイムステップですが、ここではわかりやすくするために関数として記述します。また、3次元地上面高さhfloorと上向き法線が提供される。さらに、各時刻の各足関節について、足が地面と接触しているかどうかを示すバイナリラベルが提供される。これらのラベルは、以下に説明するように、各足関節T¯i,1, T¯i,2, ... , T¯i,niの接触持続時間の初期推定値を決定する。また、つま先から踵までの距離、およびつま先から股関節までの最大距離も提供される。すべての量は、3.2項と3.3項で説明したようにビデオ入力から計算され、最適化変数の初期化と目的関数のターゲットとして使用される。
最適化変数
最適化変数は、COM位置とオイラー角方位r(t)、θ(t)∈R3、足関節位置pi(t)∈R3、接触力fi(t)∈R3である。これらの変数は時間の連続関数であり、連続性制約を持つピースワイズ3次多項式で表されます。また、接触のタイミングも最適化します。各足関節の接触は、接触と飛行を交互に繰り返す位相のシーケンスによって独立にパラメータ化されています。
オプティマイザは、各相のタイプ(接触または飛行)を変更することはできませんが、それらの持続時間Ti,1, Ti,2, ... Ti,1,Ti,2, ... , Ti,ni∈R ここで、niは第i番目の足関節の総接触相数である。
目的
我々の完全な定式化を図3に示す.EdataおよびEdurは、全持続時間Tにわたって離散的なステップで、ビデオから得られる初期入力に可能な限り近い動きと接触を維持しようとする。

図3. 物理学に基づく軌道最適化定式化。詳細は本文を参照してください。

これらの項を wd = 0.1, wr = 0.4, wθ = 1.7, wp = 0.3 とします。残りの目的項は、小さな速度と加速度を好む正則化剤であり、結果として、より滑らかな最適軌道になります。
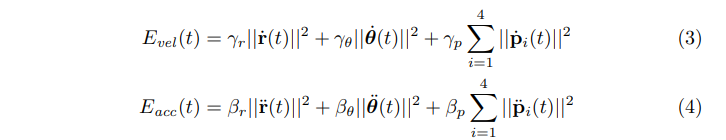
上記の式で、γr = γθ = 10−3, γp = 0.1 そして βr = βθ = βp = 10−4とする。
制約条件
最初の制約は、線形運動量と角運動量を含む有効な剛体力学を厳密に強制します。これは、運動の重要な特性を強制します。例えば、飛行中、COMはニュートンの第二法則に従って放物線状の円弧をたどる必要があります。接触時には、体の運動加速度は接触する力によって制限されます。
各タイムステップでは、入力Ib(t)と現在の姿勢θ(t)から計算されたワールドフレーム慣性テンソルIw(t)を使用します。これは、最終的な出力ポーズが入力ポーズと劇的に異なることはないと仮定しています。Winklerら[46]のように一定の慣性テンソルを使用すると、収束が困難になることがわかりました。重力ベクトルはg = -9.8nˆであり、nˆは地面の法線です。角速度ωは回転θの関数である[46]。接触力は、床から押し離すように拘束されますが、法線方向にはfmax = 1000 Nよりも大きくならないようにします。4本の足のジョイントを使用した場合、これは通常の接触力4000Nを可能にします:100kgの人が非常にダイナミックなダンスの動き[23]で発生する程度の大きさです。接触中に足が滑ることはないと仮定しているため,力は摩擦係数μ=0.5と床面の接線ˆt1,ˆt2で定義された摩擦ピラミッドの中にとどまる必要があります.
最後に、力は、接触していない任意の足の接合部でゼロでなければなりません。足の接触は、制約によって強制されます。足継手が接触しているとき、それは静止していなければなりません(滑りません)。接触していないときは、足は常に地面の上にあるか、地面より上にあるべきです。これにより,足が滑ったり,地面に突き刺さったりするのを防ぐことができます.ヒューマノイドの骨格に対して最適化された動きを有効にするためには、各足のつま先とかかとの距離を一定に保つ必要があります。最後に,足の関節は,対応する股関節から脚の長さよりも離れていてはならない.股関節位置 phip,i(t) は、3.3 節で詳述した骨格内の股関節オフセットに基づいて、その時点での COM 姿勢から計算されます。
最適化アルゴリズム
非線形内部点オプティマイザであるIPOPT [43]を用いて、解析的導関数を用いて最適化を行います。まず、COMと足の位置変数の多項式表現を入力運動にできるだけ近づけるために、接触位相を固定し、力学的制約を与えずに最適化を行います。次に、物理的に有効なモーションを見つけるために力学的制約を追加し、最後に、可能であればモーションをさらに洗練させるために接触位相の持続時間を最適化することを許可します。最適化に続いて、所望のスケルトンStgt(補足付録C参照)上で逆運動学(IK)を使用して物理的に妥当なCOMと足関節の位置から全身運動を計算します。
3.2 接触推定するための学習
物理ベースの最適化を実行する前に、入力映像が与えられたときに被験者の足が地面に接触しているかどうかを推定する必要があります。この接触は物理学的最適化の目標のターゲットであり,その精度が最適化を成功させるために非常に重要です.そのために、各ビデオフレームについて、各足のつま先とかかとが地面に接触しているかどうかを分類するネットワークを訓練します。
主な課題は、適切なデータセットと特徴表現を構築することです。現在のところ,ラベル付けされた足の接触と多種多様な動的動作を持つ動画の一般に公開されているデータセットはありません.大規模で多様なデータセットを手動でラベル付けするのは困難であり、コストもかかる。そこで、モーションキャプチャー(mocap)シーケンスを用いて合成データを生成します。モキャップ内のコンタクトに自動的にラベルを付け、生のレンダリングされたビデオフレームからの画像特徴ではなく、OpenPose [4]からの2D関節位置特徴をモデルへの入力として使用します。これにより、合成データでトレーニングを行い、実際の入力にモデルを適用することができます。
データセット
データセットを構築するために、www.mixamo.com**から**最も人間に近い13 人のキャラクターについて、ダイナミックなダンス動作からアイドリング動作までの 65 個のモーキャプシーケンスを取得しました。私たちのセットには、さまざまなアニメーションキャラクターに再ターゲットを絞った多様なモカッ プシーケンスが含まれています。各モーションシーケンスの各時点で、4 つの可能性のある接触が自動的にヒューリスティック(経験則的に)にラベル付けされます:
- (i) つま先またはかかとの関節が前回から 2cm 未満の移動をしており
- (ii) 既知の接地面から 5cm 以内にある場合、接触していると見なされます。より洗練されたラベリング [17,25] を使用することもできますが、このアプローチは、我々が評価したビデオのモデルを学習するのに十分に正確であることがわかりました。
我々は、モーションブラー、ランダム化されたカメラ視点、照明、床のテクスチャを使用して、これらのモーション(図5(c)参照)をリギングされたキャラクタ上でレンダリングした。各シーケンスについて、2 つのビューをレンダリングし、その結果、ラベル付けされたコンタクトと 2D および 3D ポーズを持つ 100,000 フレーム以上のビデオが得られました。最後に、2Dポーズ推定アルゴリズム**OpenPose [4]**を実行して、モデルが入力として使用する2Dスケルトンを取得します。
モデルとトレーニング
分類問題は、各フレームの2Dポーズから足関節の4つの接触ラベルをマッピングすることである。セクション4.1で実証したように、2D速度に基づく単純なヒューリスティックでは、3D投影とノイズの曖昧さのために正確な接触ラベル付けができません。与えられた時間tについて、我々のラベリング・ニューラル・ネットワークは、tのターゲット・フレームを中心とした持続時間wの時間窓上の2Dポーズを入力として取ります。我々は、w = 9つのビデオフレームを設定し、図4に示すように、13の下半身の関節位置を使用します。また,各関節位置の OpenPose 信頼度 c を入力として含む.したがって、ネットワークへの入力は、次元 3 ∗ 13 ∗ 9 = 351 の(x, y, c)値のベクトルとなります。モデルは、ターゲットを中心とした 5 フレームの窓に対して、4 つの接触ラベル(左右のつま先、左右のかかと)を出力します。テスト時には、重なり合う予測値の多数決を用いて、ラベルを時間的に滑らかにします。
我々はReLU非線形性を持つ5層多層パーセプトロン(MLP) (サイズ1024, 512, 128, 32, 20)を使用しています[33]。我々は合成データセットを80/10/10に分割して、キャラクタごとの動きに基づいてネットワークを完全に訓練/検証/テストする。訓練とテストでは3Dモーションは似ていても、異なるカメラ視点に投影すると、結果として得られる2Dモーション(ネットワーク入力)は大きく異なるものになります。このネットワークは、標準的な2値クロスエントロピー損失を用いて学習されます。
3.3 キネマティック初期化
接触ラベルとともに、物理ベースの最適化には、接地面と COM、足、慣性テンソルの初期軌道を入力として必要とします。これらを得るために,ビデオから初期 3D 全身運動を計算する.この段階では、[12]などの標準的な要素を使用しているので、ここではアルゴリズムをまとめ、詳細は付録Bに記載する。
まず、入力ビデオに単眼トータルキャプチャ[47](MTC)を適用して、各フレームの初期のノイズの多い3Dポーズ推定値を得る。MTC はテクスチャベースの洗練されたステップを通じて動きを考慮していますが、出力にはまだ多くのアーチファクトが含まれており(図 1)、物理学の最適化に直接使用するには不向きです。その代わりに、MTC の入力ポーズから 28 個の身体関節を含むスケルトン Ssrc を初期化し、キネマティック最適化を使用して、接地面のパラメータとともに、時間経過に伴う最適なルート移動と関節角度を解いています。この最適化の目的は、動きを滑らかにし、接触時に足が静止して地面についていることを確認し、2D OpenPoseと3D MTCポーズの両方の入力に近づくようにするための条件を含んでいます。
まず、足が静止しているが、高さが一定ではないように最適化します。次に、ロバスト回帰を使用して、足の関節の接触位置に最もフィットする接地面を見つけます。最後に、接触時にすべての足がこの接地面上にあることを確認するために最適化を続けます。
運動学的最適化の全身出力モーションは、物理学的最適化のための入力を抽出するために使用されます。事前に定義された体の質量(すべての実験で73kg)と分布[26]を使用して、COMと慣性テンソルの軌道を計算します。COM 姿勢は根元関節付近の姿勢を使用し,足関節位置はそのまま使用しています.
4 結果
ここでは、接触推定とモーション最適化の定性的および定量的な評価を紹介します。
4.1 接触推定
本研究では,学習済みの接触推定手法を評価し,合成テストセット(78本)と手動でラベル付けした9本の実動画について,ベースラインとの比較を行った.実動画にはダイナミックなダンスの動きが含まれており,合計700フレームのラベル付けが行われている.表1では、我々の手法と多数のベースラインの分類精度を報告しています。
2D OpenPoseと3D MTCの両方の推定について、セクション3.2で説明したように、足関節の速度ヒューリスティックを使用した場合と比較した。また、関節位置の異なるサブセットを使用した場合と比較しています。下半身の関節をすべて使用したMLPは、合成映像と実映像の両方において、すべてのベースラインよりも実質的に精度が高い。膝までの上半身の関節を使用すると、驚くほど良い結果が得られます。
接触推定の利点をテストするために、ネットワーク予測された接触を使用した合成テストセットでの完全最適化パイプラインと、MTC入力からの3D関節で速度ヒューリスティックを使用して予測された接触を使用した合成テストセットでの完全最適化パイプラインを比較しました。ネットワーク予測された接触を使用した最適化は、テストセットの動画の94.9%で収束したのに対し、速度ヒューリスティックを使用した場合は69.2%に収束しました。このことは、接触予測が運動最適化の成功にいかに重要であるかを示しています。我々の接触予測手法の定性的な結果を図4に示します。我々の手法は、検出がノイズの多い場合には植立した足に対して困難であり、静止しているが地面から離れている関節(踵など)の接触をラベル付けすることが多い2Dの速度ベースラインと比較しています。

表1. ビデオから足の接触を推定する際の分類精度
左:様々なベースラインとの比較,右:入力特徴として関節のサブセットを使用したアブレーション.

図4. 2次元速度ヒューリスティックと比較した学習モデルを用いた動画からの足の接触推定
可視化されたすべての関節がネットワークへの入力として使用され,4つの接触ラベル(左足の指,左かかと,右足の指,右かかと)が出力される.赤色の関節には接触ラベルが貼られています。主な違いはオレンジ色のボックスで示されています。
4.2 定性的動作評価
我々の手法は、従来の運動学的アプローチよりも質的に改善されています。生成された運動を十分に理解するために、読者には補助的なビデオを見ることをお勧めする。定性評価のために、キャプチャした動きをコンピュータアニメーションされたキャラクタにリターゲティングすることで、ビデオからのアニメーションを実証する。キャラクタのターゲット骨格Stgtが与えられると、図2に示すような運動学的最適化に従ってIKリターゲティングステップを挿入し(詳細は付録Dを参照)、この新しい骨格に対して通常の物理ベースの最適化を実行できるようにします。同じIK手順を使用して、キャラクタに直接ターゲットを絞ったMTCの結果と比較します。
図1は、我々が提案した手法が、足の浮き(上段)、足の貫通(中段)、不自然な傾き(下段)などのアーティファクトを修正していることを示している。図5(a)は,地上の真実の代替ビューを持つ合成映像のMTC入力と我々の最終結果を比較したフレームを示しています.この例では、公平な比較のために真の接地面を入力として使用しています(セクション4.3参照)。入力ビューから、我々の手法は足の浮動と貫通を修正します。
代替ビューの最初のフレームから、MTC のポーズが実際には非常に不安定で、踵でバランスを取りながら後ろに傾いていることがわかります。
図5(b)は、実際の映像を用いて、さらに定性的な結果を示しています。複雑な接触パターンを持つ動的な動きを物理的に正確に再構成していることがわかります。下段は、物理ベースの最適化段階の出力を複数フレームで示しています:COM軌道と各足のかかととつま先の接触力です。

図5 合成データと実データでの定性結果
a) 地上の真実の代替ビューを用いた合成テストビデオでの結果。入力ビデオと代替ビューについて、近くの2つのフレームを示しています。
b) 動的運動映像(上)と出力された全身運動(中)と最適化されたCOM軌道と接触力(下)。
4.3 定量的な運動評価
高品質なモーション推定を定量的に評価することは重要な課題である.最近の姿勢推定の研究では,様々なグローバルアライメント法までのローカルボディフレーム内の関節の平均的な位置誤差を評価しています[35].しかし,このような姿勢誤差は誤解を招く可能性があります.このような誤差は、アニメーション化されたキャラクタにモーションをリマップする際に知覚的に不快感を与える可能性があり、下流の視覚処理タスクで推論されたダイナミクスを使用することができません。
そこで、我々はバイオメカニクスの文献[2,15,19]にヒントを得た一連のメトリクス、すなわち、人間の運動の既知の特性に基づく物理量の信憑性を評価するためのメトリクスを使用することを提案する。我々は2つのベースラインを使用する。MTCは体位推定のための最新技術であり,我々の運動学的な初期化(セクション3.3)は,セクション3.2からの推定接触に合わせてMTCの入力を変換するものである.78本の動画からなる合成テストセットで各手法を実行した。これらの定量的な評価のみを行うために、公平な比較を行うために、我々の手法の入力には接地正解のフロアプレーンを使用している。
これは MTC入力の品質に大きく依存します(推定床を用いた定量的な結果については付録 E を参照してください)。動力学的指標. 動的妥当性を評価するために、我々は、fGRF (t) = Pi fi(t)として定義された正味の地上反力(GRF)を推定します。フルパイプラインでは、物理学に基づいて最適化されたGRFを使用し、運動学のみの初期化とMTC入力からの暗示力と比較しています。運動学的最適化とMTCによって示唆されるGRFを推論するために,物理ベースの最適化(73 kg)と同じ質量と分布を用いて,運動のCOM軌道を推定します.
次に、各時間ステップでの加速度を近似し、すべての時間ステップ(接触時と飛行時の両方)で暗黙のGRFを解いた。我々は、フォース・プレートの研究で測定されたGRFを使用して信憑性を評価します。歩行の場合、GRFは一般的に体重の80%に達し、ダンスジャンプの場合、GRFは体重の約400%に達することがある [23]。被験者の体重がわからないため,50kg~80kgの保守的な範囲で評価を行った.図6は,歩行とスイングダンスの動作に対して,本手法で生成された最適化されたGRFを示している.我々の手法で得られたピークGRFはデータと一致しており、歩行では体重の115~184%、ダンスでは127~204%であった。対照的に、運動のみのGRFは319-510%(歩行)と765-1223%(ダンス)であり、これらはノイズの多い非現実的な関節加速度の結果であると考えられます。

図6. 歩行・ダンス動作の物理学的最適化による接触力
1000N付近の正味の接触力は,想定体重(73kg)の140%であり,先行するフォースプレートデータ[2]と比較して妥当な推定値である.
我々はまた、テストセット全体にわたってGRFの妥当性を測定します(表2(左))。GRF値は、73kgの人がアイドル状態で行ったGRFのパーセンテージとして測定されます。平均して、我々の推定値はアイドル時の力の1%以内ですが、運動学的な動きは、人が24.4%重いかのようなGRFを暗示しています。同様に、運動学的運動のピーク力は、物理学的最適化の後では174kgであったのに対し、被験者は830kgの余分な体重を背負っているのと同等である。
MTCのMax GRFは、運動学的最適化と動力学的最適化の間にスムージングが行われる前のCOM運動がジッタリしているため、さらに信憑性が低くなっています。Ballistic GRFは、接地真実ラベルに従って、足の関節が接触していないはずのCOM上の中央値GRFを測定します。GRFは0%でなければなりません。つまり、COMには接触力がなく重力だけが作用していることを意味します。
運動学的測定基準
私たちは、3つの運動学的な評価基準を考慮しています(表2(右))。これらの指標は、足の接触測定の精度を評価するものである。具体的には、足の接触の接地真実ラベルが与えられると、かかととつま先の関節について、足の浮動、貫通、スケートのインスタンスを計算します。フローティングとは、足の関節が地面から 3cm 以上離れていて、接触しているはずの足の関節の割合をいいます。ペネトレーションとは、常に3cm以上地面を貫通している割合です。スケートとは、接触しているときに2cm以上動いている割合です。キネマティクスの初期化後、これらのメトリクスのスコアは最も良く(すべてのメトリクスで低い方が良い)、物理学を追加した後は若干低下します。これは,物理学に基づいた最適化に続いて全身運動を生成するIKステップに起因しています.運動学的最適化と物理学的最適化の両方の結果は、足の高さが一定になることはほとんどないMTCを大幅に上回る結果となりました。
ポジションメトリクス
完全性のために、標準的な位置測定基準のバリエーションについて、我々の手法の3Dポーズ出力を評価する。結果を表3に示す.合成テストセットに加えて,HumanEva-I [41]のトレーニングスプリットから,既知の接地面を入力として使用して,すべての歩行シーケンスを評価しました.足首と足指の関節(表3の足)と全関節(体)について、関節ごとの平均グローバル位置誤差(mm)を測定します。また、各シーケンスの最初のフレームのルート・ジョイントのみを地上の真実のスケルトンにアラインメントした後の誤差もレポートします(ボディ・アライン1 )。これは、すべてのフレームでルートをアラインメントするという一般的な方法とは異なることに注意してください。すべての手法間の誤差は同等であり、最大でも5cm程度の差がありますが、これはグローバルな関節位置を考慮すると非常に小さいものです。我々の手法の目的は物理的な再現性を向上させることですが、これらの標準的な指標ではポーズに悪影響を与えることはありません。

表2. 合成試験セットでの物理的妥当性の評価
平均/最大GRFは体重に対する接触力の割合である。弾道GRFは飛行中の説明のつかない力であり,値は小さい方が良い.足位置メトリクスは、関節ごとに典型的な足の接触誤差を含むフレームの割合を測定します。
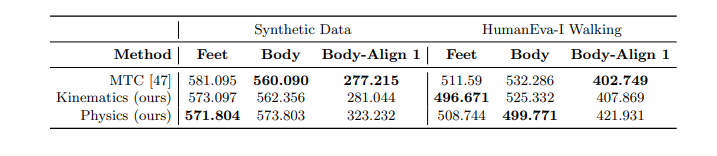
表3. 合成およびHumanEva-I歩行データセットのポーズ評価
足と全身の関節について、関節ごとの平均グローバル3D位置誤差(アライメントなし)を測定しています。全身関節については、各シーケンスの最初のフレームのみのルートアライメント後の誤差も報告しています。我々は、重要な身体的改善を提供しながら、競争力を維持しています。
5 議論
貢献
本論文で紹介する方法は、初期の運動学的ポーズ推定値から物理的に妥当な運動を推定するものである。これにより、最新の方法に比べて、視覚的にも物理的にもはるかに信憑性の高い動きが得られることを示している。本研究では、キャラクタの再ターゲット化についての結果を示したが、運動の力学的特性を利用したさらなるビジョンタスクにも利用可能であることを示した。
正確な人間の動きを推定するには多くの課題がありますが、私たちはその中でも特に重要なサブ課題に焦点を当てています。この空間には他にも、部分的に閉ざされた人の動きや接地面の位置など、いくつかの重要な未知の問題があります。これらの問題や以下に述べる限界は、それ自体が大きな課題であり、今後の研究課題であるが、本研究のアイデアは、これらの問題の解決に貢献し、今後の研究の道を切り開くものと信じている。
制限事項
問題を管理しやすくするためにいくつかの仮定をしていますが、将来的にはこれらの仮定はすべて緩和される可能性があります。これらの仮定は,ビデオモカプアプリケーションからのキャラクタアニメーションでは許容されるが,一般的な動き推定アプローチでは考慮すべきである.我々の最適化はコストがかかります。2秒(60フレーム)のビデオクリップの場合、物理的な最適化には通常30分から1時間かかります。これは主に,先行研究[46]の実装が人間の運動最適化のサイズと複雑さの増大に適していないことに起因します.我々は,特化されたソルバーと最適化された実装により,実行速度が向上することを期待しています.
謝辞
この研究は、NSF助成金IIS1763268、Samsung GROプログラムとスタンフォードSAILトヨタ研究センターからの助成金、Adobe Corporationからの贈り物によって一部サポートされています。ビデオをオンラインで共有してくださった以下のYouTubeチャンネルに感謝します。Dance FreaX、Dancercise Studio、Fencer's Edge、MihranTV、DANCE TUTORIALS、Deepak Tulsyan、Gibson Moraes、pigmie。
付録
A連絡先見積もりの詳細
ここでは、接触推定モデルとセクション3.2のデータセットについて詳述する。
A.1 合成データセット
合成データセットはBlender3を使用してレンダリングされ、www.mixamo.com から取得した各キャラクターを対象とした65種類のモーションキャプチャシーケンスを実行している13人のキャラクターが含まれています。 各モーションは2つのカメラ視点から記録され、1690本の動画と101kフレームのデータになります。
モーションには、サンバ、スイング、サルサダンス、ボクシング、サッカー、野球のアクション、ウォーキング、アイドルポーズなどがあります。動画は1280x720でレンダリングされ、30fpsで2秒の長さです。データセットからのフレーム例を図A1に示す。
データセットの中の 各タイムステップでは,RGBフレームに加えて,2D OpenPose [4]も含まれています.検出、キャラクターの骨格の形をした3Dポーズ(骨格は キャラクターごとに異なり、ポーズは.bvhモーションキャプチャーファイルで提供されます)。本文中に記載されている各足の踵と足指の付け根のフットコンタクトラベル 用紙、カメラのパラメータを指定します。各ビデオについては 多くのパラメータがランダム化されています にカメラを配置します。[4.5, 7.5]の一様ランダム距離とμ=0.9のガウスランダム高さ。とσ=0.3であるが,[0.3, 1.75]になるようにクランプされており,すべてメートル単位である.に配置されている。文字の前から90度以内のランダムな角度 キャラクターの腰の高さを大まかに見ています。の間はカメラは動きません。の動画をご覧ください。床のテクスチャは無地と他26種類のテクスチャからランダムに選択 様々な木、草、タイル、金属、カーペットを使って シーンの中にある4つのライトは ランダムなエネルギーが与えられ、ランダムなオフセットが与えられています。その結果、ビデオ間で多くのシャドウバリエーションが発生します。
A.2 モデルの詳細
接触推定MLP(サイズ1024, 512, 128, 32, 20)をPyTorch [33]で実装した.最後の層を除くすべての層でバッチ正規化を行い、サイズ128の層の前に単一のドロップアウト層を使用しています(ドロップアウト p = 0.3)。学習のために、Adam [22]を用いて、10-4の学習率で二値クロスエントロピー損失を最適化する。我々は、10-4の重みを持つL2重み減衰を適用し、検証セットの損失に基づいて早期停止を使用する。すべての2次元共同入力は、大部分が[-1, 1]の間になるようにスケールする。学習中に、σ=0.005で正規化された関節にガウスノイズを追加します。
我々のネットワークは、各ターゲットに対して5フレームにわたって接触先を共同で分類しています。枠(窓の中心の枠)には、多くの重なり合う テスト時の予測 テスト時に動画全体の接点を推論する場合 の場合、最初にすべてのフレームをターゲットとして使用し、重複する予測から投票を収集します。の過半数の投票があった場合、ジョイントはフレームで接触しているとマークされます。そのフレームでは、接触していると分類します。

図A1. 接触推定学習のための合成データセットからのRGBフレームの例
このデータには、2D OpenPose[4]の検出、3Dポーズの形での キャラクターの骨格、およびつま先の付け根とかかとのコンタクトに自動的にラベルが付けられています。
B キネマティック最適化の詳細
ここでは、物理ベースの最適化を初期化するために使用した運動学的最適化手順の詳細を説明します。概要については 3.3 節を参照してください。
B.1 入力と初期化
当社の三点最適化は、J体の関節を考慮しています。を運動を構成するT個のタイムステップにわたって求めることができます。具体的には、j∈Jとt∈Tに対して、2次元ポーズ OpenPoseからの検出 xj,t∈R 自信を持って2 σj,t, 前段階で推定された連絡先 パイプライン cj,t∈ {0, 1} ここで,ジョイント j が存在する場合,cj,t = 1 の接触状態、そして最後に MTC からの全身 3 次元ポーズを取得した。
MTCの入力を用いて,本論文ではSsrcと呼ばれるカスタムスケルトンを初期化する.J=28関節である。特に、MTCのCOCO リグレッサーを用いて,シーケンス上の19個の身体関節位置(足を除く)と,アダム上の頂点を取得します.のメッシュを使用しています.以下に説明するように、最適化の目的で再投影誤差を使用するために、これらの25個の関節を選択しました。アニメーションのリターゲティング時に使用されるキャラクタ リグへのマッピングをより良くするために、3 つの脊椎ジョイント位置を直接使用しています。を MTC のボディモデルから取り出して、最終的に 28 個の関節を作成しました。注意:ここでは MTCからの手や顔の情報は 私たちの骨格は固定された骨の長さを持っています これらの入力された3Dジョイントの位置に基づいて決定されます。モーションシーケンス: 全体の動きにわたって2つの関節間の距離の中央値 シーケンスは骨の長さを定義します。私たちの骨格(骨の長さを の入力データ)を図A2に可視化する.

図A2. 骨格
骨の長さとポーズは、運動学的最適化の前に、各モーションシーケンスのMTC入力から初期化される。
入力位置を正規化して、各関節の根元関係位置 qj,t∈R3, j = 1, ... , J, t = 1, ... J, t = 1, ... 最適化の際にターゲットとする大域的な翻訳を初期ルート翻訳proot,tとします。これらの位置はすべて、OpenPose検出の信頼度に基づいて明らかに不正確なフレームを削除するために前処理されます:対応する2D OpenPose検出を持つ25の関節(我々の骨格のすべての非脊椎関節)について、信頼度が0.3未満の場合は、十分な信頼度を持つ最も近い隣接するフレーム間の線形補間でフレームが置き換えられます。
スケルトンの関節角度に対して最適化しているので(後述)、次にMTCの関節位置入力と一致する初期関節角度を見つけなければなりません。MTCボディモデルからそれらをコピーしてスケルトンの関節角を大まかに初期化し、最終的に前処理された関節位置をターゲットとした逆運動学(IK)を実行して、スケルトン上のMTC入力の再構成を行います。8]に基づくヤコビアンベースの全身IKソルバーを使用しています。これは、運動学的初期化を通して最適化されたスケルトンである。
B.2 最適化変数
大域的な3次元根移動proot,t∈R3とスケルトンジョイントオイラー角θj,t∈R3をj=1...J, t=1....Tとして最適化します。また、法線ベクトルと平面上の点である接地面パラメータnˆ,pfloor ∈R3を求めます。後述するように、これらを一度にすべて共同最適化するのではなく、段階的に行い、別々に床をフィットさせます。
B.3 問題の定式化
以下の目的関数の最小化を求めます。

ここで、αは定数の重みである。αproj = 0.5、αvel = αang = 0.1、αacc = 0.5、αdata = 0.3、αcont = αfloor = 10を使用する。ここで、これらのエネルギー項について詳細に説明する。
qj,t∈R3, j = 1, ... , j, t = 1, ... Tは、現在の関節角度θj,tを用いて、Ssrc上の前方運動学を用いて計算できる最適化時の現在の関節位置推定値である。次に、我々のエネルギー項は以下のように定義される。
- 2次元再投影誤差 : 対応するOpenPose検出値からの関節の偏差を最小化し,検出信頼度で重み付けしたもの

ここで、Πは焦点距離f(20000と仮定)と[cx,cy]でパラメータ化された透視投影である。
-
速度平滑化:時間経過に伴う関節位置及び角度の変化を最小化する。

-
線形加速度平滑化:関節の線速度の経時変化を最小化

-
3Dデータエラー:3D MTCジョイント初期化からの偏差を最小化

-
接触速度誤差:接触中と表示された場合、足の関節(つま先とかかと)が静止することを促します。

ここで JF は足の関節のセットです。
- 接触位置誤差 : 接触中と表示されている場合、つま先とかかとの関節が接地面上にあることを促します。

B.4 最適化アルゴリズム
この最適化を主に3つの段階で行う。まず、接触位置誤差を除くすべての目的を強制し、スケルトンの根元位置と関節角度のみを解決します(フロアパラメータは使用しません)。次に、ロバストなフーバー回帰を使用して、足関節の接触位置に最適な床面を見つけ、外れ値、すなわち、地面から離れているのに接触しているとラベル付けされた関節を除外します。
外れ値の接触は、その後のすべての処理で非接触として再ラベル付けされます。最後に、全身最適化を繰り返し、今度は足が地面に接地していることを確認するために接触位置の目的を有効にします。解析的導関数を使用して、信頼領域反射アルゴリズムを使用して最適化します。
B.5 物理ベースの最適化のための入力の抽出
この運動学的最適化の全身出力から、物理ベースの最適化のための入力を抽出する必要があります(第3.1節)。COM ターゲット r(t)∈R3 を得るために、各ボディパーツをあらかじめ定義された質量を持つ点として扱います [26]。これにより、各時間ステップIb(t)∈R3×3でのボディ-フレーム慣性テンソルの計算も可能となり、力学的制約を強制するために使用されます。
特に断りのない限り、キャラクタのボディマスを73kgと仮定しています。根元関節に関する方位をCOM方位θ(t)∈R3とし、足関節位置p1:4(t)∈R3は全身運動から直接取得したものを使用する。
C 物理ベースの最適化の詳細
ここでは,3.1節からの物理ベースの軌道最適化について詳述する.
C.1 多項式パラメータ化
COM の位置と姿勢,飛行中の足の位置,およびスタンス中の接触力は,Winkler ら [46] で行われているように,一連の三次多項式によってパラメータ化されている.これらの多項式はHermiteパラメータ化を使用しています:我々は多項式係数を直接最適化するのではなく,持続時間,開始位置と終了位置,境界速度を最適化します.
COMの位置と方向は、0.1秒ごとに1つの多項式を使用します。足の位置と力は常に位相ごとに少なくとも6つの多項式を使用しますが,これは非常に動的な運動を正確に生成するために必要であることがわかりました.私たちは、位相の長さに応じて多項式を適応的に追加します。位相が2秒よりも長い場合は、それに応じて追加の多項式を追加します。立脚時の足の位置は単一の定数値とし、飛行時の接触力は定数0の値としています。
これにより、飛行中の無スリップおよび無力制約が満たされることが保証されます。接触相持続時間パラメータ化とともに多項式パラメータ化のより詳細な議論については、Winklerら[46]を参照してください。
C.2 制約パラメータ
最適化変数は連続多項式ですが、目的エネルギーと制約は離散的な間隔で実行されます。実際には、速度境界制約は、ノイズの多い動きに対してよりロバストになるように、最初の(最後の)5フレームの平均初期速度と一致させようとしています。スムージングを含む目的項は、入力データがあるすべてのステップで強制されます。例えば、30 fps の合成データセットでは、(1/30)秒間隔で客観項を提供します。
C.3 接触タイミングの最適化
3.1 節で説明したように、我々の物理学的最適化は段階的に行われ、接触相の持続時間は最後の段階まで最適化されません。このように接触相の持続時間をダイナミクスとともに最適化することは、本質的に困難で安定性の低い最適化であるため、必ずしもより良い解が得られるとは限らないことがわかりました。したがって、今回の結果では、固定入力接触タイミングを使用したソリューション(我々のニューラルネットワークからの)と、運動が改善されている場合に位相の持続時間を変更できるようにした後のソリューションの2つのソリューションのうち、より良い方を使用しています。
C.4 全身出力
物理ベースの最適化に続いて、物理的に有効な COM と足の関節位置から IK を使用して全身モーションを計算する必要があります。上半身(足の付け根を含む)については、物理最適化への入力モーションのCOMから各関節のオフセットを計算し、このオフセットを新たな最適COMに加えたものをIK時の関節ターゲットとして使用します。これにより、上半身の動きは、運動学的最適化の結果と実質的に同じになる(新しいCOMの位置により姿勢が改善される可能性はあるが)。下半身については、物理的に最適化された出力に直接つま先とかかとの関節をターゲットとし、残りの関節(すなわち、足首、膝、および腰)は入力とは大幅に異なる可能性がある IK の結果に任せます。付録B.1と同じIKアルゴリズムを使用する。
D 新しいキャラクタへのリターゲティング
多くの場合、推定された動きを新たにアニメーション化されたキャラクタのメッシュにリターゲットしたいと考える。定性的な評価のために 4.2 節のメインペーパーでこれを行います。IK リターゲティング処理後の出力モーションに物理ベースのモーションリターゲティング手法を適用することも可能である。しかし、ここでは、物理ベースの最適化をターゲットキャラクタの骨格に対して直接実行することで、このような余分なステップを回避する。
ターゲット・スケルトンStgtが与えられると、運動学的最適化に続いて追加のリターゲティング・ステップを挿入します(図2を参照)。すなわち、Ssrcをターゲット骨格の近似サイズに一様にスケーリングし、定義済みの関節マッピングに基づいてIK最適化を実行して、Stgtの関節角度を回復します。
そして、その後の物理ベースの最適化と全身のアップグレードは、このスケルトンをSsrcに置き換えて実行される。我々は付録B.1と同じIKアルゴリズムを使用する。
MTCとの定性的な比較のために、非常に類似した手順を実行していることに注意。これは、MTCからStgtに関節角を直接コピーするようなナイーブなアプローチよりも強力なベースラインを提供します。
E 評価の内容と追加結果
ここでは、評価のための追加の結果と詳細を含みます。
E.1 接触見積もり
接触推定の主な結果を 4.1 節に示す。表E1は、各手法の精度、リコール、F1スコアで主な結果を補足しています。これらは、データラベルがわずかに不均衡(ノーコンタクトよりも多くの非接触フレーム)であるため、精度と比較した場合の追加的な洞察を与えます。
表E2は、我々のネットワークのための異なる入力ウィンドウと出力ウィンドウサイズの組み合わせの間のアブレーション研究を示しています。入力ウィンドウは、ネットワークに与えられた2次元下半身関節のフレーム数であり、予測ウィンドウは、ネットワークが足の接触分類を出力するフレーム数である。表に示すように,実際の映像で最も精度が高いため,実験では入力ウィンドウw=9,予測ウィンドウ5を使用しています.一般的に予測窓の大きさには明確な傾向はないが、入力窓の大きさが大きくなるにつれて、実データセットの精度も向上する。
図E1は、合成テストセットの5フレームの予測ウィンドウ全体での接触推定精度を示している。この場合のターゲットフレームはフレームインデックス2であるが、ターゲットから外れたフレームの予測はわずかに劣化するだけで、入力ウィンドウが9フレームであるため、依然として非常に正確である。このことが、推論時に多数決方式を使用する動機となっています。

表E1. 動画から足の接触を推定する際の精度、リコール、F1スコア(Prec/Rec/F1)
左:様々なベースラインとの比較、右:関節のサブセットを特徴として用いたアブレーション。補足 表1.

表E2. 学習された接触推定のための入力と出力のウィンドウサイズのアブレーション研究
多くの異なる組み合わせに対する分類精度を示す。

図E1. 合成テストセット(9フレームを入力として与えられた)の5フレームの出力窓の全フレームに対する接触推定分類精度。中央のフレームインデックス2がターゲットフレームであるが、ターゲット外の接触予測は依然として正確である。
E.2 定性的動作評価
広範な定性的評価については、補足ビデオを参照してください。実際のデータについては、公開されているデータセット[6,36]、クリエイティブ・コモンズの下でライセンスされているか、コンテンツ制作者の許可を得て本出版物で使用するYouTube動画、およびライセンスされたストック映像からの動画を使用しています。
E.3 定量的な動きの評価
4.3 節では、運動再構成の主要な定量評価結果を示す。これらの定量的評価では、入力として接地真実床面を使用しています。我々の手法では、実写単眼映像での定性評価結果で示されているように、我々のフロアフィッティング手法は十分に機能することに注意が必要である。しかし、我々はカメラに向かって直接または離れて移動するケースを多く含むデータで定量的な評価を行いました:MTCにとって難しいケースであり、その結果、我々の手法への入力としてノイズの多い足の関節が発生し、フロアフィットが悪くなります。これは最適化を困難にし、我々の主要な貢献度の評価を妨げることになります。
しかし、ここでは完全性を確保するために、合成テストセットの床フィッティング手順を用いた定量的な結果を含めています(入力として基底真理床を用いるのではなく)。表E3はフィットした床を用いた運動学的および力学的評価を示し、表E4はポーズの評価を示しています。表E4はポーズ評価である。
E.4 グローバルポーズ推定に関する考察
4.3 節の定量的評価では、他の大域的な人の動き推定手法との比較は行わず、運動学のみのバージョンと MTC の初期化を用いた独自の手法のアブレーションを評価しています。
MTCや本研究のように時間的に一貫した大域的な運動を予測するという問題は、まだ十分に研究されていないため、比較可能な先行研究はほとんどありません。多くの手法は、従来の局所的な3Dポーズ推定やカメラからの大域的なルート移動の予測を行っていますが、これらの手法では首尾一貫した大域的な動きが得られることはほとんどありません。
例えば、**SMPLify-X**と呼ばれるPavlakosらの最近の研究[34]は、グローバルなカメラの外部特性、ローカルなポーズ、体形を推定し、動画に適用した場合にグローバルな動きを与える。しかし,時間的な追跡手法を用いたMTCの方がより良い結果が得られることが分かり,パイプラインの初期化にMTCを使用する動機付けとなった.図E2は、同じビデオクリップのSMPLify-XとMTCの結果を固定した側面図である。SMPLify-Xはノイズが多く、特に大域的な変換の点で一貫性がありません。

表E3. 合成テストセットの推定フロアを用いた物理的妥当性の評価。表2を補足します。
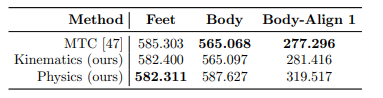
表E4. 推定床を用いた合成テストセットのポーズ評価。補足表3.
E.5 ポーズ推定評価の詳細
4.3 節では,ポーズ推定を定量的に評価する.我々の合成テストセットとHumanEva-I [41]の歩行シーケンスを用いて評価を行います.多くの姿勢推定ベンチマーク(Human3.6M [18]など)と同様に,HumanEvaでは足の接触パターンが興味深い動的な動作はほとんどありません.そのため,この基準を満たす歩行シーケンスを含むサブセットで評価を行います.
MTCベースラインについては,我々の手法への入力として与えられたリグレッションされた関節に直接基づいて精度を測定する.我々の手法では、付録B.1に記載されているように、MTC入力から初期フィットされたカスタムスケルトン上で、完全な物理ベースのモーションパイプラインの後に推定された関節を使用する。
合成テストセットについては、首、肩、肘、手首、腰、膝、足首、足の指(背骨のジョイントは含まない)の 16 個のジョイントを含む既知のキャラクタ・リグのサブセットについて、ジョイント・エラーを測定する。表3の「足」の欄には、足首と足指の関節のみが含まれている。
表3の右側では、**HumanEva-I **[41]のトレーニングスプリット(被験者1、2、3を含む)の歩行シーケンスについて手法を評価している。先行研究[35]に従って、まず、破損したモーションキャプチャフレームを除去することで、歩行シーケンスを連続したチャンクに分割する。さらに、これらのチャンクを約120フレーム(約2秒)のシーケンスに分割し、我々の手法への入力として使用する。データセットからカメラの外部特性を使用して地上の真実の床面を抽出し、これを手法への入力として使用します。関節誤差は、HumanEvaの正解モーションキャプチャから適応された15関節のスケルトン[35]を基準に測定されます(根元、頭部、首、肩、肘、手首、腰、膝、足首を含みます)。表3の「足」の列には、足首の関節のみが含まれています。
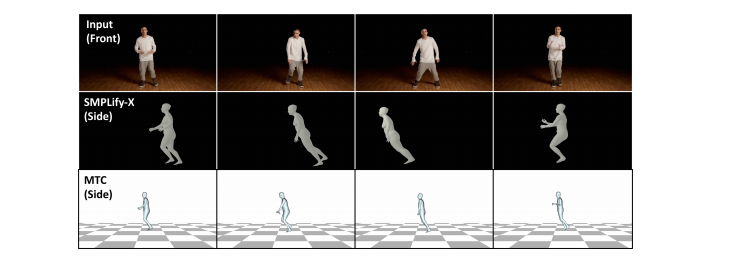
図E2. SMPLify-X[34]とMonocular Total Capture(MTC)[47]からの固定側面図を示す。SMPLify-Xはノイズが多く一貫性のない大域的な動きを与えるのに対し、MTCはトラッキングの精密化により、より滑らかな結果が得られます。

図E3. 我々の手法は、体格や質量分布の異なる複数のキャラクターに適用可能です。左からYbot(体重73kg)、Ty(36.5kg)、スケルトンゾンビ(146kg)である。
E.6 マルチキャラクターの一般化
付録 D に記載されている手順に従って、物理ベースの最適化を、身体と質量の分布が異なる多くのキャラクタの骨格に適用することができます。図 E3 は、3 つの異なるキャラクタについて、同じ動画から動きを推定した例を示しています。Ybot、Ty、スケルトンゾンビです。Ybotの体格は73kgで、典型的な人間の質量分布を持っています[26]。
Tyは36.5kgと非常に軽く、彼の質量の40%が頭部にあるように分布が修正されています。スケルトンゾンビは146kgとはるかに質量が大きく、腕だけで質量の36%を占めています(巨大な爪のため)。私たちの物理学に基づいた最適化は、これらのバリエーションを処理しても、動画から正確にモーションを復元することができます。追加の例については、補足動画をご覧ください。
References
-
- Bogo, F., Kanazawa, A., Lassner, C., Gehler, P., Romero, J., Black, M.J.: Keep it smpl: Automatic estimation of 3d human pose and shape from a single image. In: European Conference on Computer Vision (ECCV). pp. 561–578 (2016)
-
- Brubaker, M.A., Sigal, L., Fleet, D.J.: Estimating contact dynamics. In: The IEEE International Conference on Computer Vision (ICCV). pp. 2389–2396 (2009)
-
- Brubaker, M.A., Fleet, D.J., Hertzmann, A.: Physics-based person tracking using the anthropomorphic walker. International Journal of Computer Vision 87(1), 140- 155 (2010)
-
- Cao, Z., Hidalgo, G., Simon, T., Wei, S.E., Sheikh, Y.: Openpose: Realtime multiperson 2d pose estimation using part affinity fields. IEEE Transactions on Pattern Analysis and Machine Intelligence (2019)
-
- Carpentier, J., Mansard, N.: Multicontact locomotion of legged robots. IEEE Transactions on Robotics 34(6), 1441–1460 (2018)
-
- Chan, C., Ginosar, S., Zhou, T., Efros, A.A.: Everybody dance now. In: IEEE International Conference on Computer Vision (ICCV) (2019)
-
- Chen, Y., Huang, S., Yuan, T., Qi, S., Zhu, Y., Zhu, S.C.: Holistic++ scene understanding: Single-view 3d holistic scene parsing and human pose estimation with human-object interaction and physical commonsense. In: The IEEE International Conference on Computer Vision (ICCV). pp. 8648–8657 (2019)
-
- Choi, K.J., Ko, H.S.: On-line motion retargetting. In: Pacific Conference on Computer Graphics and Applications. pp. 32– (1999)
-
- Dai, H., Valenzuela, A., Tedrake, R.: Whole-body motion planning with centroidal dynamics and full kinematics. In: IEEE-RAS International Conference on Humanoid Robots. pp. 295–302 (2014)
-
- Fang, A.C., Pollard, N.S.: Efficient synthesis of physically valid human motion. ACM Trans. Graph. 22(3), 417–426 (2003)
-
- Forsyth, D.A., Arikan, O., Ikemoto, L., O’Brien, J., Ramanan, D.: Computational studies of human motion: Part 1, tracking and motion synthesis. Foundations and Trends in Computer Graphics and Vision 1(2–3), 77–254 (2006)
-
- Gleicher, M.: Retargetting motion to new characters. In: SIGGRAPH. pp. 33–42 (1998)
-
- Hassan, M., Choutas, V., Tzionas, D., Black, M.J.: Resolving 3d human pose ambiguities with 3d scene constraints. In: The IEEE International Conference on Computer Vision (ICCV). pp. 2282–2292 (2019)
-
- He, K., Gkioxari, G., Dollar, P., Girshick, R.: Mask r-cnn. In: The IEEE International Conference on Computer Vision (ICCV). pp. 2961–2969 (2017)
-
- Herr, H., Popovic, M.: Angular momentum in human walking. Journal of Experimental Biology 211(4), 467–481 (2008)
-
- Hoyet, L., McDonnell, R., O’Sullivan, C.: Push it real: Perceiving causality in virtual interactions. ACM Trans. Graph. 31(4), 90:1–90:9 (2012)
-
- Ikemoto, L., Arikan, O., Forsyth, D.: Knowing when to put your foot down. In:Symposium on Interactive 3D Graphics and Games (I3D). pp. 49–53 (2006)
-
- Ionescu, C., Papava, D., Olaru, V., Sminchisescu, C.: Human3.6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE Transactions on Pattern Analysis and Machine Intelligence 36(7), 1325–1339(2014)
-
- Jiang, Y., Van Wouwe, T., De Groote, F., Liu, C.K.: Synthesis of biologically realistic human motion using joint torque actuation. ACM Trans. Graph. 38(4), 72:1–72:12 (2019)
-
- Kanazawa, A., Black, M.J., Jacobs, D.W., Malik, J.: End-to-end recovery of human shape and pose. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7122–7131 (2018)
-
- Kanazawa, A., Zhang, J.Y., Felsen, P., Malik, J.: Learning 3d human dynamics from video. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5614–5623 (2019)
-
- Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: International Conference on Learning Representations (ICLR) (2015)
-
- Kulig, K., Fietzer, A.L., Jr., J.M.P.: Ground reaction forces and knee mechanics in the weight acceptance phase of a dance leap take-off and landing. Journal of Sports Sciences 29(2), 125–131 (2011)
-
- de Lasa, M., Mordatch, I., Hertzmann, A.: Feature-based locomotion controllers. In: SIGGRAPH. pp. 131:1–131:10 (2010)
-
- Le Callennec, B., Boulic, R.: Robust kinematic constraint detection for motion data. In: ACM SIGGRAPH/Eurographics Symposium on Computer Animation (SCA). pp. 281–290 (2006)
-
- de Leva, P.: Adjustments to zatsiorsky-seluyanov’s segment inertia parameters. Journal of Biomechanics 29(9), 1223 – 1230 (1996)
-
- Li, Z., Sedlar, J., Carpentier, J., Laptev, I., Mansard, N., Sivic, J.: Estimating 3d motion and forces of person-object interactions from monocular video. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8640–8649 (2019)
-
- Liu, C.K., Hertzmann, A., Popovi´c, Z.: Learning physics-based motion style with nonlinear inverse optimization. ACM Trans. Graph. 24(3), 1071–1081 (2005)
-
- Macchietto, A., Zordan, V., Shelton, C.R.: Momentum control for balance. In: SIGGRAPH. pp. 80:1–80:8 (2009)
-
- Mehta, D., Sridhar, S., Sotnychenko, O., Rhodin, H., Shafiei, M., Seidel, H.P., Xu, W., Casas, D., Theobalt, C.: Vnect: Real-time 3d human pose estimation with a single rgb camera. ACM Trans. Graph. 36(4) (2017)
-
- Newell, A., Yang, K., Deng, J.: Stacked hourglass networks for human pose estimation. In: European Conference on Computer Vision (ECCV). pp. 483–499 (2016)
-
- Orin, D.E., Goswami, A., Lee, S.H.: Centroidal dynamics of a humanoid robot. Autonomous Robots 35(2-3), 161–176 (2013)
-
- Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., Chintala, S.: Pytorch: An imperative style, high-performance deep learning library. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 8026–8037 (2019)
-
- Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3d hands, face, and body from a single image. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10975–10985 (2019)
-
- Pavllo, D., Feichtenhofer, C., Grangier, D., Auli, M.: 3d human pose estimation in video with temporal convolutions and semi-supervised training. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7753–7762 (2019)
-
- Peng, X.B., Kanazawa, A., Malik, J., Abbeel, P., Levine, S.: Sfv: Reinforcement learning of physical skills from videos. ACM Trans. Graph. 37(6), 178:1–178:14 (2018)
-
- Popovi´c, Z., Witkin, A.: Physically based motion transformation. In: SIGGRAPH. pp. 11–20 (1999)
-
- Reitsma, P.S.A., Pollard, N.S.: Perceptual metrics for character animation: Sensitivity to errors in ballistic motion. ACM Trans. Graph. 22(3), 537–542 (2003)
-
- Robertson, D.G.E., Caldwell, G.E., Hamill, J., Kamen, G., Whittlesey, S.N.: Research Methods in Biomechanics. Human Kinetics (2004)
-
- Safonova, A., Hodgins, J.K., Pollard, N.S.: Synthesizing physically realistic human motion in low-dimensional, behavior-specific spaces. In: SIGGRAPH. pp. 514–521. ACM (2004)
-
- Sigal, L., Balan, A., Black, M.: Humaneva: Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion. International Journal of Computer Vision 87, 4–27 (2010)
-
- Vondrak, M., Sigal, L., Hodgins, J., Jenkins, O.: Video-based 3d motion capture through biped control. ACM Trans. Graph. 31(4), 27:1–27:12 (2012)
-
- W¨achter, A., Biegler, L.T.: On the implementation of an interior-point filter linesearch algorithm for large-scale nonlinear programming. Mathematical Programming 106(1), 25–57 (2006)
-
- Wang, J.M., Hamner, S.R., Delp, S.L., Koltun, V.: Optimizing locomotion controllers using biologically-based actuators and objectives. ACM Trans. Graph. 31(4) (2012)
-
- Wei, X., Chai, J.: Videomocap: Modeling physically realistic human motion from monocular video sequences. In: SIGGRAPH. pp. 42:1–42:10 (2010)
-
- Winkler, A.W., Bellicoso, D.C., Hutter, M., Buchli, J.: Gait and trajectory optimization for legged systems through phase-based end-effector parameterization. IEEE Robotics and Automation Letters (RA-L) 3, 1560–1567 (2018)
-
- Xiang, D., Joo, H., Sheikh, Y.: Monocular total capture: Posing face, body, and hands in the wild. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10965–10974 (2019)
-
- Xu, W., Chatterjee, A., Zollh¨ofer, M., Rhodin, H., Mehta, D., Seidel, H.P., Theobalt, C.: Monoperfcap: Human performance capture from monocular video. ACM Trans. Graph. 37(2), 27:1–27:15 (2018)
-
- Zanfir, A., Marinoiu, E., Sminchisescu, C.: Monocular 3d pose and shape estimation of multiple people in natural scenes-the importance of multiple scene constraints. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2148–2157 (2018)
-
- Zou, Y., Yang, J., Ceylan, D., Zhang, J., Perazzi, F., Huang, J.B.: Reducing footskate in human motion reconstruction with ground contact constraints. In: The IEEE Winter Conference on Applications of Computer Vision (WACV). pp. 459–468 (2020)