はじめに
今更ながらGunosy Advent Calender 2015の19日目の記事です。
今年も終わりですね。
11月からGunosyで働き始めたのですが、とても楽しいです。
普段はデータ分析とアルゴリズム開発をしているので、今回は業務での分析で使う時系列分析について簡単に紹介します。
時系列分析とは
時系列解析とはある現象の変動を過去の動きとの関連で捉えようとするものである
北川源四郎 『時系列解析入門』より
「データドリブン経営」や「ビッグデータ」という言葉も定着し始めており、多くの企業がデータをもとに、プロダクトの改善のための意思決定を行っているかと思います。
しかし、日々変化するデータ(特に売上やKPIと言われる指標)は、ばらつきも大きく、変化を適切に捉えることが難しこともあります。
そこで、時系列分析を行うことで変化を適切に捉えたり、予測をある正確にすることができます。
季節調整
今回は季節調整データを紹介します。
ざっくり説明すると、時系列のデータを
観測値 = トレンド成分 + 季節成分 + ノイズ成分
で説明するモデルです。
※詳しい説明は北川源四郎 『時系列解析入門』の12章を参考にいただけると幸いです。
弊社の提供するアプリもですが、人間の生活に密着している以上は、人間の生活リズムに影響を受けます。大きく分けて「月要因」、「曜日要因」、「時間要因」がありますが、今回は曜日に注目してサンプルを実装しようかと思います。
Rでの実装
東京電力さんのデータを使って実装したいと思います。まずRでやります。
まずは、生データを出力します。
data <- read.csv("tokyo2015_day.csv", header=T) # csvからデータを取得
power <- data[,2] # 数値を抽出
plot(power, type="l") #プロット
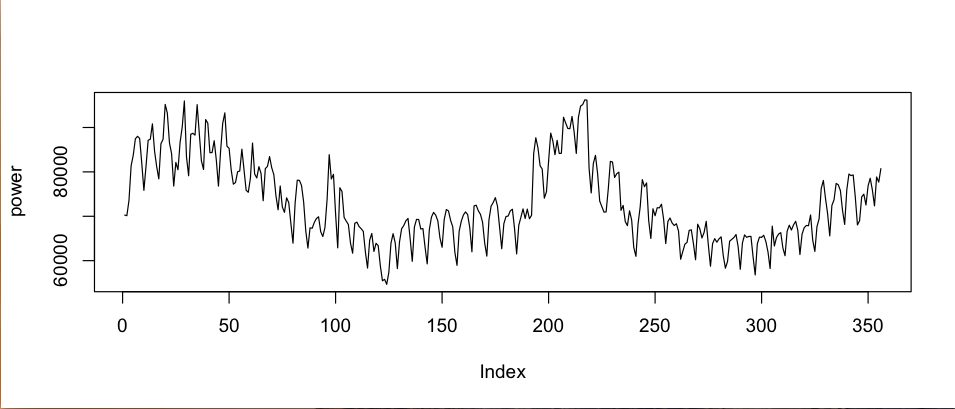
ギザギザしてますね。
Rにはデータを周期テータに変換する ts関数 と、季節調整時系列データに変換してくれる stl関数関数がありこれらを用いれば簡単に季節調整モデルを作成できます。
data <- read.csv("tokyo2015_day.csv", header=T) # csvからデータを取得
power <- data[,2] # 数値を抽出
plot(power, type="l") #プロット
ts <- ts(power, frequency=7) # 周期は7日(1週間)
stl <- stl(ts, s.window="periodic") #季節調整時系列データ作成
plot(stl, type="l") #プロット
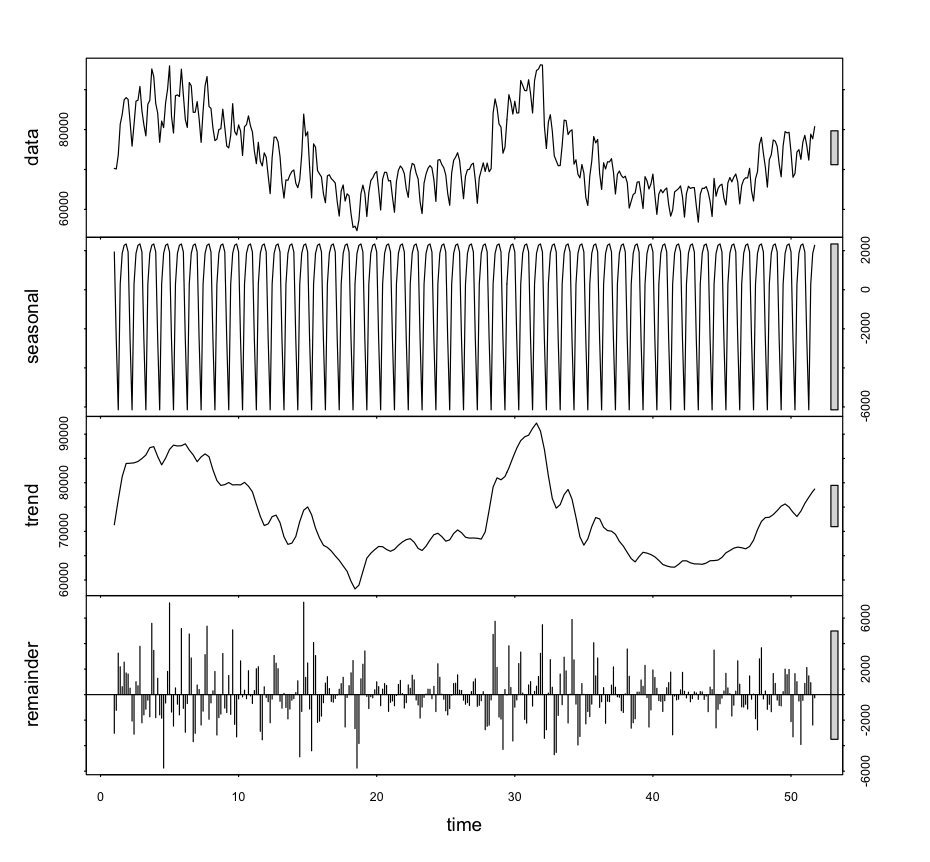
4つのグラフの一番上が生データ(観測値)で、上から順にトレンド成分、季節成分、ノイズ成分に分割することができています。
データ分析においては、トレンド成分を見ることで長期の変化を捉えることができます。
ちょっと考察
やっぱり夏と冬が高く、曜日の影響も大きいようです(多くの方々が同じような周期で生活しているのが見て取れます)。
曜日成分についての主力は下記の通りになります。2015年の1月1日がスタートで、1月1日が木曜日ですので、休日(土曜日、日曜日)の季節成分がマイナスになっているのはわかるかと思います。
$ print(stl$time.series[,1]) #季節成分を出力
2321.9288 1927.3324 -2517.1524 -6122.9112 293.1919 1872.1087 2225.5017...
夏の電力使用量がガクっと下がっているのを見ると、「たしかに今年は9月から急に涼しくなったなあ」と思わないこともありません。
(※他の年と比較して見ないとなんとも言えませんが)
Pythonでの実装
Pythonでもやります。Jupyterです。やってることは一緒です。
import csv
import datetime as datetime
import matplotlib.pyplot as plt
import pandas as pd
from statsmodels.tsa.seasonal import seasonal_decompose
%matplotlib inline
filename = "tokyo2015_day.csv"
with open(filename, 'rt') as f:
data = list(csv.reader(f))
headers = data.pop(0)
df = pd.DataFrame(data, columns=headers)
dataFrame = DataFrame(df['power'].values.astype(int), DatetimeIndex(start='2015-01-01', periods=len(df['power']), freq='D'))
ts = seasonal_decompose(dataFrame.values, freq=7)
plt.plot(ts.trend) # トレンド成分
plt.plot(ts.seasonal) # 季節成分
plt.plot(ts.resid) # ノイズ成分
謝辞
Pythonコードの一部は@moyomotさんにRからPythonに書き換えてもらいました。
おわりに
おしまい