工事データの発掘大冒険! #5
~サンプルコードを使って工事データを取得・ダウンロード!~
みなさん、こんにちは!
この記事は国交DPFアドベントカレンダー2023に参加しています。本日は11日目です。
昨日までのAPI紹介記事は読んでいただけましたか?
今日はサンプルコード解説の最終日ということで、国土交通データプラットフォームのHPに掲載されているサンプルコードの1つ
「cals_download」
を使って、工事データの発掘を体験してみましょう。
昨日までの記事を読んでないよという方もこの記事を読めば、国土交通データプラットフォームから簡単に工事データを取得することができちゃいます。
ち・な・みに
今回はタイトルに発掘と入れているので、建設ワードと関連させながら解説してみようと思います!笑
今回やりたいこと
- 指定した工事の完成年月で電子納品保管管理システムの工事データを取得
- 取得した工事データに添付されている「INDEX_C(工事管理ファイル)」をダウンロード
- ダウンロードした「INDEX_C(工事管理ファイル)」を指定フォルダに工事毎に保存
今回紹介するサンプルコードは、国土交通データプラットフォームのこちらに載っているので、まずは見てみてくださいね。
サンプルコードはJavaScriptとPythonと用意がありますが、今回はJavaScriptで試してみた結果を紹介してみようと思います。
では、さっそく中身を見ていきましょう!
必要なツール(モジュール)の準備
まずは必要なツール(モジュール)をインポートしましょう!
これはもう慣れたものですね。
イメージとしては、発掘するための重機や機械を用意するようなものです!すべてをその手一つでやるわけにはいかないですからね。現実の世界もプログラムの世界も同じようなものです。。
import https from "https";
import axios from "axios";
import fs from "fs";
import { mkdir } from "fs/promises";
import path from "path";
それぞれ、
- https: HTTPSリクエストを行うために必要なライブラリです。
- axios: HTTPSリクエストを行うために必要なaxiosライブラリです。
- fs: ファイルの読み書き操作をするために必要なライブラリです。
- fs/promises: mkdir(フォルダ作成)の関数を使用するために必要なライブラリです。
- path: ファイルのパスを操作するために必要なライブラリです。
https、axios = 「通信用の機械たち」
fs、fs/promises、path = 「発掘したデータを整理整頓するための機械たち」
みたいなものですね!
建設現場でも色々な機械が活躍していますよね。そんなイメージです。
APIのエンドポイントとAPIキーの設定
APIのエンドポイント(建設現場)とAPIキー(作業許可証)を設定します。
これも現実世界では、事前準備ができていないと作業は始められないですよね。
const END_POINT = "https://www.mlit-data.jp/api/v1/";
const API_KEY = "please use your own key";
「END_POINT」は、そのままでOKです!
「API_KEY」は、「please use your own key」の部分に取得したキーを入力してください。
API_KEYを取得したことがないという方は、こちらの記事を参考に取得してみてください!
今回のサンプルコードで大きな要素はこの5つ!
今回紹介しているサンプルコードについて、中身が長くて初心者にはわかりづらいよって思った方もご心配なく!
今回のサンプルコードは大きく分けると以下の5つにわけることができます。
1.「GetData」で対象データの一覧を取得!
取得したいデータの条件を決めておくときは「GetData」の中に記載していきます。たくさんある工事データの中から、必要なデータを絞り込んでおきましょう!
async function GetData(year, month) {
// ...
}
2.「CreateFolders」でデータの整理場所を準備!
せっかくダウンロードしたデータはしっかり整理したいですよね!取得したデータをフォルダなどに整理して格納したいときは「CreateFolders」を使用して、事前の準備をしっかりしておきます!
async function CreateFolders(foldername) {
// ...
}
3.「DownloadFile」で対象データのダウンロード!
データのダウンロード作業は「DownloadFile」の中で作業をします。この関数があるおかげで、取得したデータを安全に自分のPCに保存できます。
async function CreateFolders(foldername) {
// ...
}
4.「GetFiles」で対象データを一気にGET!
指定した条件(今回は工事の完成年月!)に合致するデータを「GetFiles」で一気に掘り出していきます!そういう意味ではこの関数が一番の建設機械ですね!
async function CreateFolders(foldername) {
// ...
}
5.作業開始の号令!
さぁ最後に作業開始の号令をかけちゃってください。
取得したい工事の完成年月と保存先フォルダを指定してあげます。サンプルコードでは、最終行に記載していますね!
:::note info
- year : 完成年を西暦4桁で指定してあげます。
- month : 完成月を1~12の数値で指定してあげます。
- savefoldername : フォルダ名(名称は自由です!)を指定してあげます。
サンプルコードでは、すでにそれぞれ値が入った状態になっていますが、自由に指定することができます。
:::note info
year完成年を西暦4桁で指定してあげます。
- year : 完成年を西暦4桁で指定してあげます。
- month : 完成月を1~12の数値で指定してあげます。
- savefoldername : フォルダ名(名称は自由です!)を指定してあげます。
サンプルコードでは、すでにそれぞれ値が入った状態になっていますが、自由に指定することができます。
なお、今回指定フォルダは相対パスを使って指定してあげています。
await GetFiles(year, month, "./savefoldername");
例えば、こんな感じ!
2022年3月に完成した工事のINDEX_CファイルをINDEX_C-2022-03に保存して!とここでは言っています。
await GetFiles(2022, 3, "./INDEX_C-2022-03");
では、中身を見ていく~
1.「GetData」の内容
const pageSize = 100;
ここでは、pageSizeという定数を定義して、100という値を設定しています。これは、一回のAPIリクエストで取得するデータの最大数を指定しています。
const date_start = year + "-" + (month > 9 ? month : "0" + month) + "-01";
指定された年と月から開始日を生成しています。月が10未満の場合は0を先頭に付けて、日付の形式
を保持するようにしています。日は01で固定しています。(例: "2023-03-01")
const nextmonth = month === 12 ? 1 : month + 1;
const nextyear = nextmonth !== 1 ? year : year + 1;
const date_end =
nextyear + "-" + (nextmonth > 9 ? nextmonth : "0" + nextmonth) + "-01";
終了日を計算します。もし12月が指定された場合は、翌年の1月が終了日となります。それ以外の場合は、翌月が終了日で指定されます。
query{
search(
term: ""
first: ${pagefirst}
size: ${pageSize}
attributeFilter: {
AND: [
{ attributeName: "DPF:dataset_id", is: "cals_construction" },
{ attributeName: "DPF:completion_datetime", gte: "${date_start}", lt: "${date_end}" }
]
}
sortAttributeName: "DPF:completion_datetime"
sortOrder: "asc"
) {
totalNumber
searchResults {
id
title
files {
id
original_path
sizeinbytes
}
}
}
}`;
クエリの内容を記載しています。取得するデータのid,title,fileの情報(id,orijinal_path,sizeinbytes)を結果として返してくれます。
const maximumDataNumber = 1000;
const result = [];
let remainingResult = true;
let pagefirst = 0;
最大1000件のデータを取得するための変数を設定します。resultは取得したデータを格納する配列、remainingResult はさらにデータがあるかどうかを判断するために、pagefirst はページネーションにおける開始点を指定しています。
while (remainingResult && result.length < maximumDataNumber) {
const GraphQLQuery = MakeQueryString(year, month, pagefirst);
残りのデータがあり、かつ取得するデータ数が指定した最大数(今回は1000件)未満の場合は、処理をループさせます。
const request = {
url: END_POINT,
method: "post",
headers: {
"Content-type": "application/json",
apikey: API_KEY,
},
data: { query: GraphQLQuery },
};
HTTPリクエストを設定します。さきほど指定したエンドポイントとAPIキーを参照してきます。
await axios(request)
.then((response) => {
axiosを使って非同期リクエストを送信して、レスポンスを待ちます。成功した場合は、以下のコードが実行されるように設定しています。
response.data.data.search.searchResults.forEach((data) => {
result.push(data);
});
if (response.data.data.search.searchResults.length === pageSize)
pagefirst += pageSize;
else remainingResult = false;
})
2.「CreateFolders」の内容
ここでは、指定されたフォルダ名が存在しない場合にそのフォルダを作成するための処理を記載しています。つまり、何か問題があった(今回は指定フォルダがない!)というときのための事前準備をしておこう作戦というわけですね!
try {
if (!fs.existsSync(foldername)) {
await mkdir(foldername, {
recursive: true,
});
}
} catch (error) {
console.log(error);
}
tryの部分に記載されている内容が実行され、エラーが発生した場合は catch部分に記載されている内容が実行されます。
if (!fs.existsSync(foldername)) {
ここでフォルダの存在チェックをしています。fsの前についている! 演算子は、フォルダが存在しない場合に true を返します。
await mkdir(foldername, {
recursive: true,
});
ここで、mkdir 関数(フォルダを作成するための関数)を呼び出しています。awaitは、この操作が完了するまで待っててね~ということを示しています。
} catch (error) {
console.log(error);
}
この部分は、try の部分に記載されている内容を実行中にエラーが発生した場合に実行されます。エラー情報は error オブジェクトに格納されています。格納されたエラー情報は、コンソール上に表示出力されます。
3.「DownloadFile」の内容
ここでは、取得したダウンロード用URLからファイルをダウンロードして、指定されたパスに保存する処理が書かれています。
const dirname = path.dirname(savepath);
await CreateFolders(dirname);
path モジュールの dirname メソッドを使用して、savepath のディレクトリ名(パス)を取得します。
await CreateFolders(dirname): CreateFolders 関数を呼び出して、savepath に指定されたディレクトリが存在しない場合は作成します。(さっきやったやつだ!笑)
return new Promise((resolve, reject) => {
new Promise((resolve, reject) => { ... }): 非同期処理をカプセル化するためにプロミスという構文を使用しています。成功した場合は resolve を呼び出し、エラーが発生した場合は reject を呼び出します。(これはちょっと難しいですね。。簡単に言うと、ある処理が実行中の他の処理を監視して、処理が問題なく完了すればresolve、反対に問題があればrejectを呼び出す。みたいな感じです。。)
try {
const file = fs.createWriteStream(savepath);
fs モジュールを使用して、保存先のパスに対して書き込み用のストリームを作成します。つまり、「今から書き込みするぜ!」って宣言しているようなものですね。
https.get(URL, function (response) {
https モジュールを使用して、指定された URL からのHTTP GETリクエストを実行します。レスポンスはコールバック関数で受け取ります。
「データの在り処はわかってるんだ、さぁ今から取りに行くぜ!」って感じですね。
const { statusCode } = response;
if (statusCode !== 200) {
reject({ message: "Server response falls out of status=200" });
HTTPレスポンスのステータスコードをチェックしています。ステータスコードが200(正常なレスポンス)ではない場合は、プロミスを reject し、エラーメッセージを返します。
余談ですが、このHTTPのステータスコードって、例えば正常コードはなんで200何だろうって思った方いないですか?
ちなみに私は知らないんですけどww
(知らないんかい!笑)
だれか教えてください。。気になって朝も起きれない・・・。
(朝は起きろよ。)
はい、続けます。
file.on("finish", () => {
file.close();
resolve(true);
});
ファイルのダウンロードが完了し、すべてのデータが書き込まれた後に呼び出されます。
ふぅ~ここまできたら、ファイルストリーム(フォルダの読み書き)を閉じて、プロミスを resolve (成功)とします。
よし、これでファイルのダウンロード処理は完了ですね!
4.「GetFiles」の内容
最後は少し長めです。少し一息つきましょう。。
ラスボスってもちろん最後に出てくるから、ラスボスなんですけど、最初に出てくるラスボスもありだと思うんですよね。その場合はなんていうんでしょう。ファーストとしたらファスボス?笑
なんの話をしているんだろう・・・多分私も少し疲れてるのかも・・・
でもそんなことは言ってられない!さぁいきます!
ここでは、特定の年月のデータセットから特定のファイル(今回はINDEX_C.XML)をダウンロードし、指定されたフォルダに保存するという処理を書いています。
ついにここまできました。
const datalist = await GetData(year, month);
let cnt = 0;
GetData 関数(最初にやったやつ~)を呼び出して、指定された年月のデータセットを非同期で取得します。取得したデータは datalist に格納されていきます。
let cnt = 0;では、ダウンロードしたファイルの数をせっせとカウントしています。
for (let i = 0; i < datalist.length; i++) {
const data = datalist[i];
console.log("Downloading file for:", data.title);
for ループは datalist に含まれる各データ項目に対して順番に処理を行っていきます。
console.log("Downloading file for:", data.title);では、現在処理しているデータのタイトルをコンソールに出力するようにしています。
if (data.files) {
const filedata = data.files.find((file) => {
return (
path.basename(file.original_path).toLowerCase() === "index_c.xml"
);
});
取得したデータにファイルが添付されているかどうかを確認します。その上で、添付ファイルの中から INDEX_C.XML ファイルを探しています。
const GetFileDownloadURLQuery = `
query {
fileDownloadURLs(
files:[{ id: "${filedata.id}", original_path: "INDEX_C.XML"}]
) {
ID
URL
}
}`;
const request = { ... };
ここでクエリを投げます。データのIDとダウンロードURLをくれ~と全身全霊で訴えます。
await axios(request)
.then((response) => {
...
})
.catch((error) => {
...
});
axios を使用してリクエストを送信し、レスポンスを待ちます。成功した場合とエラーが発生した場合の処理がそれぞれこの後に記述されています。
if (URL) {
try {
await DownloadFile(
URL,
path.join(savefolder, data.id, "INDEX_C.XML")
);
...
} catch (error) {
...
}
}
取得したURLが有効であれば、DownloadFile 関数を使用してファイルをダウンロードし、指定されたフォルダに保存していきます。
try-catchはさっきも出てきましたね!今回はダウンロード処理中に発生する可能性のあるエラーをキャッチ!します。
console.log(
"Downloaded a total of",
cnt,
"files for",
datalist.length,
"construction work data."
);
}
ダウンロードしたファイルの総数と処理したデータの総数をコンソールに表示します。あとでどんな感じで表示されるのか、お見せしますね!
これで完成!
お疲れさまでした!ここまで分解して説明してきましたが、全体はこんな感じ!
ちょっとやり切った感ありますよね?
import https from "https";
import axios from "axios";
import fs from "fs";
import { mkdir } from "fs/promises";
import path from "path";
// エンドポイントとAPIキーを定義しておく
const END_POINT = "https://www.mlit-data.jp/api/v1/";
const API_KEY = "please use your own key";
// 指定した完成年月で工事データ一覧を取得する。
// year = 年
// month = 月 (1..12)
async function GetData(year, month) {
const pageSize = 100;
//GraphQLクエリー内容を作成する関数を作成しておく
function MakeQueryString(year, month, pagefirst) {
const date_start = year + "-" + (month > 9 ? month : "0" + month) + "-01";
const nextmonth = month === 12 ? 1 : month + 1;
const nextyear = nextmonth !== 1 ? year : year + 1;
const date_end =
nextyear + "-" + (nextmonth > 9 ? nextmonth : "0" + nextmonth) + "-01";
return `
query{
search(
term: ""
first: ${pagefirst}
size: ${pageSize}
attributeFilter: {
AND: [
{ attributeName: "DPF:dataset_id", is: "cals_construction" },
{ attributeName: "DPF:completion_datetime", gte: "${date_start}", lt: "${date_end}" }
]
}
sortAttributeName: "DPF:completion_datetime"
sortOrder: "asc"
) {
totalNumber
searchResults {
id
title
files {
id
original_path
sizeinbytes
}
}
}
}`;
}
// APIを呼び出して結果を準備する。
const maximumDataNumber = 1000;
const result = [];
let remainingResult = true; // 複数のページがある時にループして全データを取得するようにする。サンプルなので上限は1000件とする。
let pagefirst = 0;
while (remainingResult && result.length < maximumDataNumber) {
const GraphQLQuery = MakeQueryString(year, month, pagefirst);
// HTTPクエリー内容を作成
const request = {
url: END_POINT,
method: "post",
headers: {
"Content-type": "application/json",
apikey: API_KEY,
},
data: { query: GraphQLQuery },
};
await axios(request)
.then((response) => {
response.data.data.search.searchResults.forEach((data) => {
result.push(data);
});
if (response.data.data.search.searchResults.length === pageSize)
pagefirst += pageSize;
else remainingResult = false;
})
.catch((error) => {
console.error(error.message);
if (error.response) console.debug("Error data:", error.response.data);
remainingResult = false;
});
}
return result;
}
// 指定したフォルダが存在しなければ作成する。
async function CreateFolders(foldername) {
try {
if (!fs.existsSync(foldername)) {
await mkdir(foldername, {
recursive: true,
});
}
} catch (error) {
console.log(error);
}
}
// 指定URLからファイルをダウンロードし、指定保存先に保存する。
async function DownloadFile(URL, savepath) {
// 保存先のフォルダが存在しない場合は作成する。
const dirname = path.dirname(savepath);
await CreateFolders(dirname);
// ファイルをダウンロードする
return new Promise((resolve, reject) => {
try {
const file = fs.createWriteStream(savepath);
https.get(URL, function (response) {
const { statusCode } = response;
if (statusCode !== 200) {
reject({ message: "Server response falls out of status=200" });
} else {
response.pipe(file);
// after download completed close filestream
file.on("finish", () => {
file.close();
resolve(true);
});
}
});
} catch (error) {
reject(error);
}
});
}
// 指定した年月で工事データリストを取得し、INDEX-C.XMLファイルをダウンロードする。
// year = 年
// month = 月 (1..12)
// savefolder = INDEX-Cファイルの保存先
async function GetFiles(year, month, savefolder) {
const datalist = await GetData(year, month);
let cnt = 0;
// すべてのデータを1つずつダウンロードする。
// 以下のループで処理する。
for (let i = 0; i < datalist.length; i++) {
const data = datalist[i];
console.log("Downloading file for:", data.title);
// データにファイルが添付されているかを確認する。
if (data.files) {
// データファイルの中からINDEX_C.XMLのファイル情報を取得する。
const filedata = data.files.find((file) => {
return (
path.basename(file.original_path).toLowerCase() === "index_c.xml"
);
});
// INDEX_C.XMLを見つけた場合にダウンロードを行う。
if (filedata && filedata.id) {
// ダウンロード用のURLを取得するためのクエリーを作成する。
const GetFileDownloadURLQuery = `
query {
fileDownloadURLs(
files:[{ id: "${filedata.id}", original_path: "INDEX_C.XML"}]
) {
ID
URL
}
}`;
const request = {
url: END_POINT,
method: "post",
headers: {
"Content-type": "application/json",
apikey: API_KEY,
},
data: { query: GetFileDownloadURLQuery },
};
// ダウンロード用URLを取得する。
let URL = "";
await axios(request)
.then((response) => {
if (
response.data.data.fileDownloadURLs &&
response.data.data.fileDownloadURLs.length === 1
) {
URL = response.data.data.fileDownloadURLs[0].URL;
}
})
.catch((error) => {
console.error(error.message);
if (error.response)
console.debug(
"Impossible to retreive file download URL.",
error.response.data
);
});
// ダウンロード用URLを取得した場合、実際にダウンロードする
if (URL) {
try {
await DownloadFile(
URL,
path.join(savefolder, data.id, "INDEX_C.XML")
);
console.log("Download completed.");
cnt++;
} catch (error) {
console.log("Error while downloading or saving file:", URL);
console.log(error.message);
}
}
} else {
console.log("No file to download.");
}
}
}
// ダウンロードしたファイル数のまとめを表示する。
console.log(
"Downloaded a total of",
cnt,
"files for",
datalist.length,
"construction work data."
);
}
await GetFiles(2022, 3, "./INDEX_C-2022-03");
実行するときはここを変えて!
ここまで、サンプルデータの中身について解説を行ってきましたが、今回のサンプルデータを動かすのに最終的にどこを変えれば動くんだ?というあなたの今の疑問にお答えします!
変えてほしいのは以下の2点!
まずはAPIキーの設定
const API_KEY = "please use your own key";
「please use your own key」の部分を取得したAPiキーに置き換えてください
そして、年月とフォルダの指定
await GetFiles(2022, 3, "./INDEX_C-2022-03");
ここだけです!説明長い割にそこだけかよ!と思わないでくださいね。。
発掘開始!
せっかくなので、プログラムの実行結果を実際に見てみましょう!
まずは実行環境を整える必要がありますが、まだ実行環境がないよという方は、こちらの記事を参考にやってみてください!
すでに環境がある方は早速やってみましょう!
今回はNode.jsを使って実行してみます。
Node.jsの実行環境が準備できたら、早速コマンドプロンプトを起動してみましょう。
起動できたら、今回のサンプルコードを実行するディレクトリに移動していきましょう。
今回はCドライブ直下にある「project」フォルダにサンプルコード「cals_download.js」を配置しました。
移動できたら以下のコマンドを入力して・・・
C:\project>node cals_download.js
ポチっとな
C:\project>node cals_download.js
Downloading file for: 令和2年度41号高山地区施設修繕工事
Download completed.
Downloading file for: 佐賀3号原地区1工区外改築工事
Download completed.
Downloading file for: R3公園遊具設置工事
Download completed.
///...
Downloaded a total of 30 files for 30 construction work data.
こんな感じで表示されたら成功です!
最終行には取得したファイルの総数もしっかり出ていますね!
肝心のINDEX_Cはちゃんと保存されているのか!?
ちゃんと確認してみます。
30個のフォルダが作成されてますね!

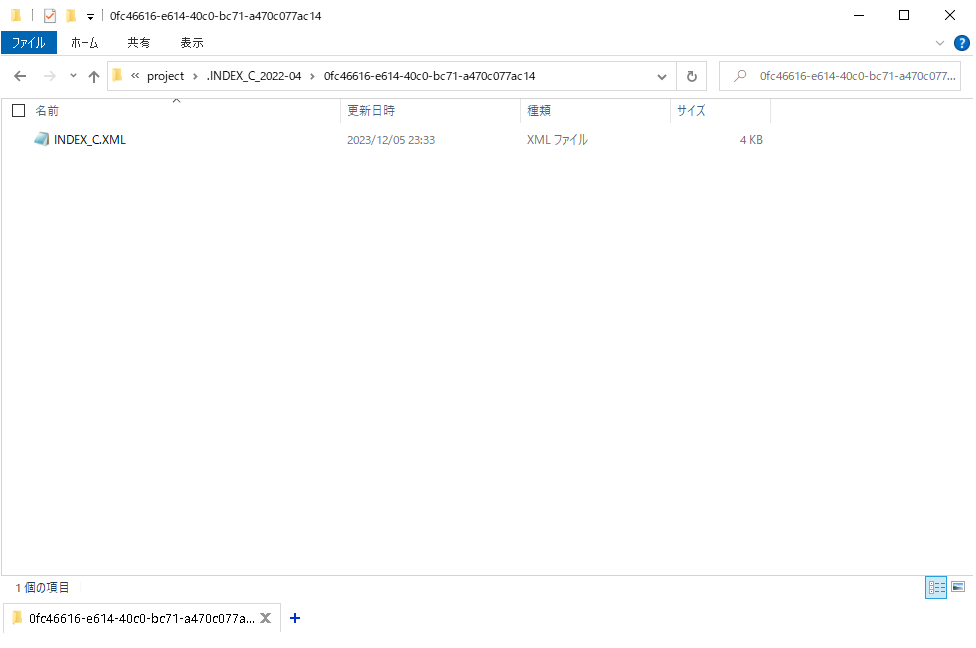
最後にファイル確認!
INDEX_Cファイルもしっかり中に入っています!
最後に
というわけでみなさん、本日の発掘大冒険はここまで。
今日も小さな箱を開けて、何があるかな?というドキドキ感を楽しんでいただけましたでしょうか。
私自身、「建設」「土木」という言葉に対しては、堅苦しいイメージを持っていましたが、実は驚きと発見がいっぱい詰まってるんですよね。
みなさんもそんな驚きと発見の毎日が送れたらそりゃあもうハッピー全開ですよね?笑
今回は国土交通データプラットフォームが提供しているサンプルコードの1つを使って、電子成果品のINDEX_Cファイルを取得して保存するということをやってみました。
ぜひ、まだ見ぬデータ発掘の冒険に出発してみてください!
それでは、引き続き国交DPFアドカレをお楽しみください!
ありがとうございました!